




目录
题解之前:
1.有关unordered_map的count功能:查询key!
或contains
2. unordered_map的find功能是查找key,返回指向pair<k, v>的迭代器it,it->second返回其value。

Leetcode 1.两数之和

解题思路:

class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
vector<int> res;
// key:具体的数值(便于count查看是否存在) value:具体的下标索引idx(ans)
unordered_map<int, int> s;
for(int i = 0; i < nums.size(); i ++){
int left = target - nums[i];
if(s.count(left)){ // 已经存在了
res.push_back(i); res.push_back(s[left]);
break;
}
s[nums[i]] = i;
}
return res;
}
};Leetcode 1865. 找出和为指定值的下标对

思路:本质是两数之和的变题,需要利用类成员变量的思想,维护两个数组和一个哈希表。这题在add之后,记得还要维护一下哈希表的最新状态。
Code:
class FindSumPairs { vector<int> nums1, nums2; unordered_map<int, int> cnt; public: FindSumPairs(vector<int>& nums1, vector<int>& nums2) { this -> nums1 = nums1; this -> nums2 = nums2; for (int x: nums2) cnt[x] ++; } void add(int index, int val) { cnt[nums2[index]] --; nums2[index] += val; cnt[nums2[index]] ++; } int count(int tot) { int res = 0; for (int x: nums1) res += cnt[tot - x]; return res; } };
Leetcode 454.四数相加 II

解题思路:

代码:
class Solution {
public:
int fourSumCount(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3, vector<int>& nums4) {
int res = 0;
unordered_map<int, int> s;
for(auto a: nums1)
for(auto b: nums2)
s[a + b] ++;
for(auto c: nums3)
for(auto d: nums4)
res += s[-c - d];
return res;
}
};Leetcode 49.字母异位词分组
算法核心:选择什么作为哈希表的key?

解法一:排序+hash

class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>> ans;
unordered_map<string, int> s;
int idx = -1;
for(auto v: strs){
string cp = v;
sort(v.begin(), v.end());
if(!s.count(v)){
vector<string> t = {cp};
ans.push_back(t);
s[v] = ++ idx;
}else{
ans[s[v]].push_back(cp);
}
}
return ans;
}
};解法二:计数+hash


class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
int idx = -1;
vector<vector<string>> ans;
unordered_map<string, int> map;
for(auto v: strs){
vector<int> cnt(26, 0); // 计数数组
// 初始化计数数组
for(char c: v)
cnt[c - 'a'] ++;
// 生成字符串key
string key = "";
for(int i = 0; i < 26; i ++){
key += 'a' + i;
key += cnt[i];
}
// 看看是否出现过
if(!map.count(key)){ // 没有出现过
vector<string> t = {v};
ans.push_back(t);
map[key] = ++ idx;
}else // 出现过
ans[map[key]].push_back(v);
}
return ans;
}
};Leetcode 128. 最长连续序列

解题思路:


代码:
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int> S;
for(auto& v: nums) S.insert(v); // 去重
int res = 0; // 初始化最长连续序列长度为0
for(auto& v: S){
if(!S.count(v - 1)){ // 不是序列首部数据就直接跳过
// 进入本代码块说明是本连续序列的首部
int curnum = v;
int len = 1; // 当前长度
while(S.count(curnum + 1)){ // 存在下一个连续数的时候
curnum ++, len ++;
}
res = max(res, len);
}
}
return res;
}
};Leetcode 594. 最长和谐子序列

错因:写的时候当成连续的子数组了->用的二分答案。
分析:由于max-min=1,相当于数组只能有x和x+1两个数,那么这个数组的长度就是x的个数+(x+1)的个数。又因为是子序列,可以隔着选出所有的x和x+1。那么问题转化为统计数组中每个数字的个数即可。
Code:O(N)
class Solution { public: int findLHS(vector<int>& nums) { unordered_map<int, int> cnt; for (int x: nums) cnt[x] ++; int res = 0; for (auto& [x, c]: cnt) if (cnt.contains(x + 1)) res = max(res, c + cnt[x + 1]); return res; } };
Leetcode 966. 元音拼写检查器

思路:暴力会超时,使用两次哈希来优化查询时间。
暴力就是对于每一个query,重新遍历每一个wordlist看是否有符合要求的。如果用哈希,只需要用O(1)的时间去拿到wordlist里面是否有符合要求的。
注意,在代码实现的时候,需要注意优先级,优先返回wordlist里面靠前符合要求的匹配项。所以在构建unordered_map 的时候,记得倒序遍历构建(后遍历到的会覆盖->体现出优先级)。
在 C++ 的
unordered_map(或其他语言中的哈希表/字典) 中,如果你用一个已经存在的键(key)去插入一个新的键值对,新的值(value)会覆盖旧的值。通过倒序遍历并利用哈希表键值覆盖的特性,我们可以巧妙地确保对于任何一个变形后的键(如
"kite"或"k?t?"),最终存储在哈希表中的值都对应于它在原始wordlist中第一次出现的那个单词。这样就轻松地满足了题目中关于优先级的规定。Code:
class Solution { public: string tolower_string(string s) { for (char& c: s) c = tolower(c); // ①引用 ②tolower参数是char return s; } string replace_vowels(string s) { for (char& c: s) if (c == 'a' || c == 'e' || c == 'i' || c == 'o' || c == 'u') c = '?'; return s; // 元音字母不参与比较 } vector<string> spellchecker(vector<string>& wordlist, vector<string>& queries) { int n = wordlist.size(); unordered_set<string> origin(wordlist.begin(), wordlist.end()); unordered_map<string, string> lower2origin; unordered_map<string, string> vowel2origin; for (int i = 0; i < n; i ++) { string& s = wordlist[i]; string lower = tolower_string(s); lower2origin[lower] = s; // 如kite-> KiTe vowel2origin[replace_vowels(lower)] = s; // 如k?t? -> KiTe } for (string& q: queries) { if (origin.contains(q)) continue; // 完全匹配 string lower = tolower_string(q); auto it = lower2origin.find(lower); if (it != lower2origin.end()) // 不区分大小写的匹配 q = it -> second; else { // 不区分大小写+元音模糊匹配 auto it = vowel2origin.find(replace_vowels(lower)); q = it != vowel2origin.end() ? it -> second : ""; } }return queries; } };

Leetcode 3408. 设计任务管理器

思路:懒删除堆,具体详见“堆专题-”
======前缀和与哈希表专题======
核心技巧:“枚举右,维护左”
相关题单:(1.2节部分)
Leetcode 560. 和为 K 的子数组


class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
int presum = 0, n = nums.size(), res = 0;
unordered_map<int, int> hash;
hash[0] ++; // hash的含义:左边前缀和大小的取值个数的映射
// 那么, 左边取值和的大小0的值,至少本身就算1个(左边都不要,只要自身一个即可)
for(int i = 0; i < n; i ++){
presum += nums[i];
res += hash[presum - k]; // 不存在的键自动取值为0
hash[presum] ++;
}
return res;
}
};Leetcode 2588. 统计美丽子数组数目

Case分析:
class Solution { public: long long beautifulSubarrays(vector<int>& nums) { long long res = 0; int s = 0; unordered_map<int, int> cnt{{0, 1}}; for (int x : nums){ s ^= x; res += cnt[s ^ 0]; // 异或运算中,只有1能改变答案,所以此处等价于cnt[s] cnt[s] ++; } return res; } };


Leetcode 437. 路径总和 III
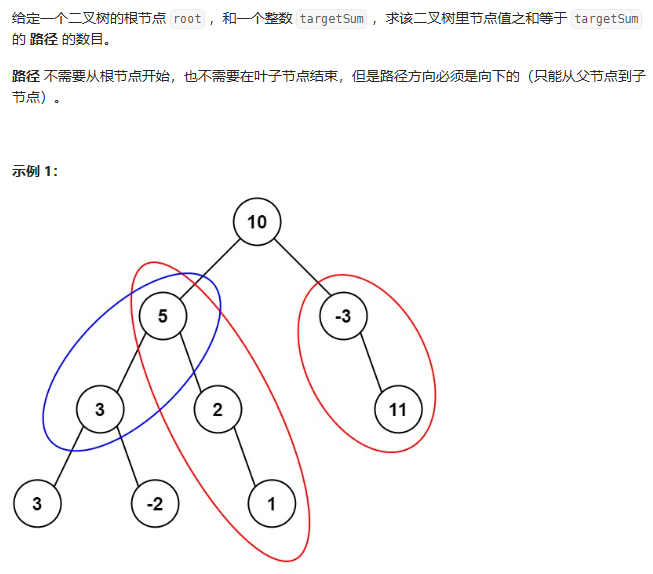
思路同560.前缀和+哈希表

class Solution {
public:
int pathSum(TreeNode* root, int targetSum) {
int ans = 0;
unordered_map<long long, int> cnt;
cnt[0] ++; // 理由同560,前面都不要
function<void(TreeNode*, long long)> dfs =[&](TreeNode* root, long long presum)->void{
if(root == nullptr) return;
presum += root -> val;
ans += (cnt.count(presum - targetSum)? cnt[presum-targetSum]: 0);
cnt[presum] ++;
dfs(root -> left, presum);
dfs(root -> right, presum);
cnt[presum] --; // 恢复现场,回溯
};
dfs(root, 0);
return ans;
}
};//时间复杂度:O(n),其中 n 是二叉树的节点个数。空间复杂度:O(n)。 
======原地哈希专题======
原地哈希就相当于,让每个数字n都回到下标为n-1的家里。
而那些没有回到家里的就成了孤魂野鬼流浪在外,他们要么是根本就没有自己的家(数字小于等于0或者大于nums.size()),要么是自己的家被别人占领了(出现了重复)。
这些流浪汉被临时安置在下标为i的空房子里,之所以有空房子是因为房子i的主人i+1失踪了(数字i+1缺失)。
因此通过原地构建哈希让各个数字回家,我们就可以找到原始数组中重复的数字还有消失的数字。
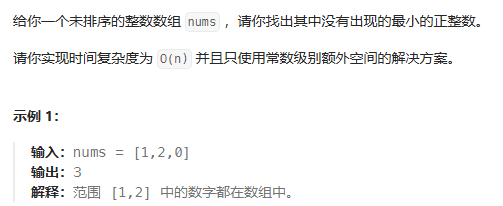
Leetcode 41. 缺失的第一个正数
原地哈希的while注意,会帮每一个这个位置上数字进行归位,一旦归位后的数字再在for中遍历到,那么就不会再执行了,所以时间复杂度是O(n)的。

class Solution {
public:
int firstMissingPositive(vector<int>& nums) {
int n = nums.size();
for(int i = 0; i < n; i ++) // while进行持续归位
while (nums[i] > 0 && nums[i] <= n && nums[nums[i] - 1] != nums[i])
swap(nums[i], nums[nums[i] - 1]);
for(int i = 0; i < n; i ++){
if(i + 1 != nums[i])
return i + 1;
}
return n + 1; // 执行到这一步说明前面都占满了, [1, n],那么没出现过的必然是n + 1
}
};Leetcode LCR 120. 寻找文件副本

class Solution {
public:
// 抓住题目的条件: 0<=id<=n-1可以使用原地哈希
int findRepeatDocument(vector<int>& documents) {
int n = documents.size();
int i = 0;
while (i < n){
if(i == documents[i]) {
i ++; // 只有完成当前坑位的任务,才会i++
continue; // 已经对应上坑位了,跳过
}
if(documents[i] == documents[documents[i]]) // 找到一组重复值
return documents[i];
swap(documents[i], documents[documents[i]]);// 说明不相等,swap
}
return -1;
}
};Leetcode 448. 找到所有数组中消失的数字
Leetcode 442. 数组中重复的数据
======字符串哈希======
板子


核心思想:将字符串看成P进制数,P的经验值是 131 或 13331,取这两个值的冲突概率低
小技巧:取模的数用2 ^ 64,这样直接用unsigned long long存储,溢出的结果就是取模的结果
typedef unsigned long long ULL;
ULL h[N], p[N]; // h[k]存储字符串前k个字母的哈希值, p[k]存储 P^k mod 2^64
// 初始化
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * P + str[i]; //str[]也是从第一个为有效位数
p[i] = p[i - 1] * P;
}
// 计算子串 str[l ~ r] 的哈希值
ULL get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}


















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











