




 本文探讨了支持向量机(SVM)的大边界分类原理,解析了核函数在非线性分类中的作用,以及如何选择合适的核函数和参数。介绍了高斯核函数和其他核函数的特性,以及在多类分类问题中的应用。
本文探讨了支持向量机(SVM)的大边界分类原理,解析了核函数在非线性分类中的作用,以及如何选择合适的核函数和参数。介绍了高斯核函数和其他核函数的特性,以及在多类分类问题中的应用。
12.支持向量机大边界分类背后的数学和核函数
本章编程作业及代码实现部分见:Python实现支持向量机
12.1 大边界分类背后的数学(选修)
在本节课中,我将介绍一些大间隔分类背后的数学原理。这会让你对支持向量机中的优化问题,以及如何得到大间距分类器,产生更好的直观理解。
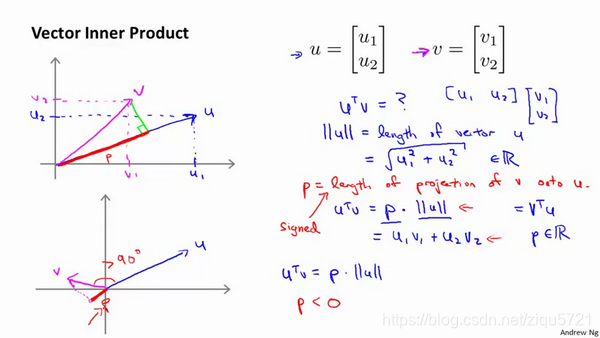
首先,让我来给大家复习一下关于向量内积的知识。假设我有两个向量, u u u和 v v v,我将它们写在这里。两个都是二维向量,我们看一下, u T v u^T v uTv的结果。 u T v u^T v uTv也叫做向量 u u u和 v v v之间的内积。由于是二维向量,我可以将它们画在这个图上。我们说,这就是向量 u u u即在横轴上,取值为某个 u 1 {{u}_{1}} u1,而在纵轴上,高度是某个 u 2 {{u}_{2}} u2作为 u u u的第二个分量。现在,很容易计算的一个量就是向量 u u u的范数。 ∥ u ∥ \left\| u \right\| ∥u∥表示 u u u的范数,即 u u u的长度,即向量 u u u的欧几里得长度。根据毕达哥拉斯定理, ∥ u ∥ = u 1 2 + u 2 2 \left\| u \right\|=\sqrt{u_{1}^{2}+u_{2}^{2}} ∥u∥=u12+u22,这是向量 u u u的长度,它是一个实数。现在你知道了这个的长度是多少了。我刚刚画的这个向量的长度就知道了。
回头来看向量 v v v ,因为我们想计算内积。 v v v是另一个向量,它的两个分量 v 1 {{v}_{1}} v1和 v 2 {{v}_{2}} v2是已知的。向量 v v v可以画在这里,现在让我们来看看如何计算 u u u和 v v v之间的内积。这就是具体做法,我们将向量 v v v投影到向量 u u u上,我们做一个直角投影,或者说一个90度投影将其投影到 u u u上,接下来我度量这条红线的长度。我称这条红线的长度为 p p p,因此 p p p就是长度,或者说是向量 v v v投影到向量 u u u上的量,我将它写下来, p p p是 v v v投影到向量 u u u上的长度,因此可以将 u T v = p ⋅ ∥ u ∥ {{u}^{T}}v=p\centerdot \left\| u \right\| uTv=p⋅∥u∥,或者说 u u u的长度。这是计算内积的一种方法。如果你从几何上画出 p p p的值,同时画出 u u u的范数,你也会同样地计算出内积,答案是一样的。另一个计算公式是: u T v u^T v uTv就是 [ u 1 u 2 ] \left[ {{u}_{1}}\text{ }{{u}_{2}} \right] [u1 u2] 这个一行两列的矩阵乘以 v v v。因此可以得到 u 1 × v 1 + u 2 × v 2 {{u}_{1}}\times {{v}_{1}}+{{u}_{2}}\times {{v}_{2}} u1×v1+u2×v2。根据线性代数的知识,这两个公式会给出同样的结果。顺便说一句, u T v = v T u u^Tv=v^Tu uTv=vTu。因此如果你将 u u u和 v v v交换位置,将 u u u投影到 v v v上,而不是将 v v v投影到 u u u上,然后做同样地计算,只是把 u u u和 v v v的位置交换一下,你事实上可以得到同样的结果。申明一点,在这个等式中 u u u的范数是一个实数, p p p也是一个实数,因此 u T v u^T v uTv就是两个实数正常相乘。
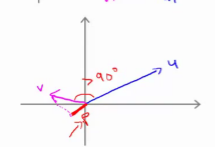
最后一点,需要注意的就是 p p p值, p p p事实上是有符号的,即它可能是正值,也可能是负值。我的意思是说,如果 u u u是一个类似这样的向量, v v v是一个类似这样的向量, u u u和 v v v之间的夹角大于90度,则如果将 v v v投影到 u u u上,会得到这样的一个投影,这是 p p p的长度,在这个情形下我们仍然有 u T v {{u}^{T}}v uTv是等于 p p p乘以 u u u的范数。唯一一点不同的是 p p p在这里是负的。在内积计算中,如果 u u u和 v v v之间的夹角小于90度,那么那条红线的长度 p p p是正值。然而如果这个夹角大于90度,则 p p p将会是负的。就是这个小线段的长度是负的。如果它们之间的夹角大于90度,两个向量之间的内积也是负的。这就是关于向量内积的知识。我们接下来将会使用这些关于向量内积的性质试图来理解支持向量机中的目标函数。

这就是我们先前给出的支持向量机模型中的目标函数。为了讲解方便,我做一点简化,仅仅是为了让目标函数更容易被分析。
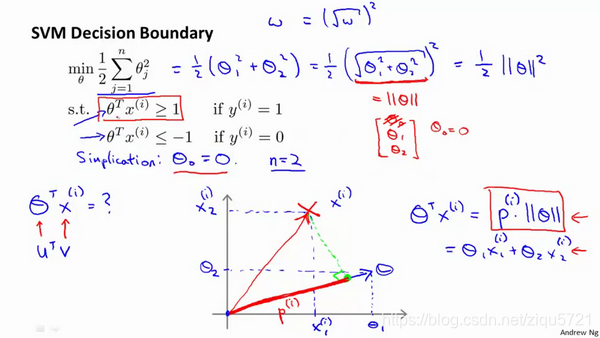
我接下来忽略掉截距,令 θ 0 = 0 {{\theta }_{0}}=0 θ0=0,这样更容易画示意图。我将特征数 n n n置为2,因此我们仅有两个特征 x 1 , x 2 {{x}_{1}},{{x}_{2}} x1,x2,现在我们来看一下目标函数,支持向量机的优化目标函数。当我们仅有两个特征,即 n = 2 n=2 n=2时,这个式子可以写作: 1 2 ( θ 1 2 + θ 2 2 ) = 1 2 ( θ 1 2 + θ 2 2 ) 2 \frac{1}{2}\left({\theta_1^2+\theta_2^2}\right)=\frac{1}{2}\left(\sqrt{\theta_1^2+\theta_2^2}\right)^2 21(θ12+θ22)=21(θ12+θ22)2,我们只有两个参数 θ 1 , θ 2 {{\theta }_{1}},{{\theta }_{2}} θ1,θ2。你可能注意到括号里面的这一项是向量 θ {{\theta }} θ的范数,或者说是向量 θ {{\theta }} θ的长度。我的意思是如果我们将向量 θ {{\theta }} θ写出来,那么我刚刚画红线的这一项就是向量 θ {{\theta }} θ的长度或范数。这里我们用的是之前学过的向量范数的定义,事实上这就等于向量 θ {{\theta }} θ的长度。
当然你可以将其写作 θ 0 , θ 1 , θ 2 {{\theta }_{0}}\text{,}{{\theta }_{1}},{{\theta }_{2}} θ0,θ1,θ2,如果 θ 0 = 0 {{\theta }_{0}}=0 θ0=0,那就是 θ 1 , θ 2 {{\theta }_{1}},{{\theta }_{2}} θ1,θ2的长度。在这里我将忽略 θ 0 {{\theta }_{0}} θ0,这样来写 θ \theta θ的范数,它仅仅和 θ 1 , θ 2 {{\theta }_{1}},{{\theta }_{2}} θ1,θ2有关。但是,数学上不管你是否包含,其实并没有差别,因此在我们接下来的推导中去掉 θ 0 {{\theta }_{0}} θ0不会有影响这意味着我们的目标函数是等于 1 2 ∥ θ ∥ 2 \frac{1}{2}\left\| \theta \right\|^2 21∥θ∥2。因此支持向量机做的全部事情,就是极小化参数向量 θ {{\theta }} θ范数的平方,或者说长度的平方。
现在我将要看看这些项:
θ
T
x
\theta^{T}x
θTx更深入地理解它们的含义。给定参数向量
θ
\theta
θ给定一个样本
x
x
x,这等于什么呢?在前一页幻灯片上,我们画出了在不同情形下,
u
T
v
u^Tv
uTv的示意图,我们将会使用这些概念,
θ
\theta
θ和
x
(
i
)
x^{(i)}
x(i)就类似于
u
u
u和
v
v
v 。
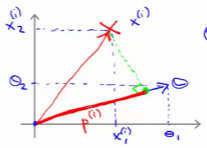
让我们看一下示意图:我们考察一个单一的训练样本,我有一个正样本在这里,用一个叉来表示这个样本 x ( i ) x^{(i)} x(i),意思是在水平轴上取值为 x 1 ( i ) x_1^{(i)} x1(i),在竖直轴上取值为 x 2 ( i ) x_2^{(i)} x2(i)。这就是我画出的训练样本。尽管我没有将其真的看做向量。它事实上就是一个始于原点,终点位置在这个训练样本点的向量。现在,我们有一个参数向量我会将它也画成向量。我将 θ 1 θ_1 θ1画在横轴这里,将 θ 2 θ_2 θ2 画在纵轴这里,那么内积 θ T x ( i ) θ^T x^{(i)} θTx(i) 将会是什么呢?
使用我们之前的方法,我们计算的方式就是我将训练样本投影到参数向量 θ {{\theta }} θ,然后我来看一看这个线段的长度,我将它画成红色。我将它称为 p ( i ) p^{(i)} p(i)用来表示这是第 i i i个训练样本在参数向量 θ {{\theta }} θ上的投影。根据我们之前幻灯片的内容,我们知道的是 θ T x ( i ) θ^Tx^{(i)} θTx(i)将会等于 p p p 乘以向量 θ θ θ 的长度或范数。这就等于 θ 1 ⋅ x 1 ( i ) + θ 2 ⋅ x 2 ( i ) \theta_1\cdot{x_1^{(i)}}+\theta_2\cdot{x_2^{(i)}} θ1⋅x1(i)+θ2⋅x2(i)。这两种方式是等价的,都可以用来计算 θ θ θ和 x ( i ) x^{(i)} x(i)之间的内积。
这里表达的意思是:这个
θ
T
x
(
i
)
>
=
1
θ^Tx^{(i)}>=1
θTx(i)>=1 或者
θ
T
x
(
i
)
<
−
1
θ^Tx^{(i)}<-1
θTx(i)<−1的,约束是可以被
p
(
i
)
⋅
x
>
=
1
p^{(i)}\cdot{x}>=1
p(i)⋅x>=1这个约束所代替的。因为
θ
T
x
(
i
)
=
p
(
i
)
⋅
∥
θ
∥
θ^Tx^{(i)}=p^{(i)}\cdot{\left\| \theta \right\|}
θTx(i)=p(i)⋅∥θ∥ ,将其写入我们的优化目标。我们将会得到没有了约束,
θ
T
x
(
i
)
θ^Tx^{(i)}
θTx(i)而变成了
p
(
i
)
⋅
∥
θ
∥
p^{(i)}\cdot{\left\| \theta \right\|}
p(i)⋅∥θ∥。

需要提醒一点,我们之前曾讲过这个优化目标函数可以被写成等于 1 2 ∥ θ ∥ 2 \frac{1}{2}\left\| \theta \right\|^2 21∥θ∥2。
现在让我们考虑下面这里的训练样本。现在,继续使用之前的简化,即 θ 0 = 0 {{\theta }_{0}}=0 θ0=0,我们来看一下支持向量机会选择什么样的决策界。这是一种选择,我们假设支持向量机会选择这个决策边界。这不是一个非常好的选择,因为它的间距很小。这个决策界离训练样本的距离很近。我们来看一下为什么支持向量机不会选择它。
对于这样选择的参数
θ
{{\theta }}
θ,可以看到参数向量
θ
{{\theta }}
θ事实上是和决策界是90度正交的,因此这个绿色的决策界对应着一个参数向量
θ
{{\theta }}
θ这个方向,顺便提一句
θ
0
=
0
{{\theta }_{0}}=0
θ0=0的简化仅仅意味着决策界必须通过原点
(
0
,
0
)
(0,0)
(0,0)。现在让我们看一下这对于优化目标函数意味着什么。
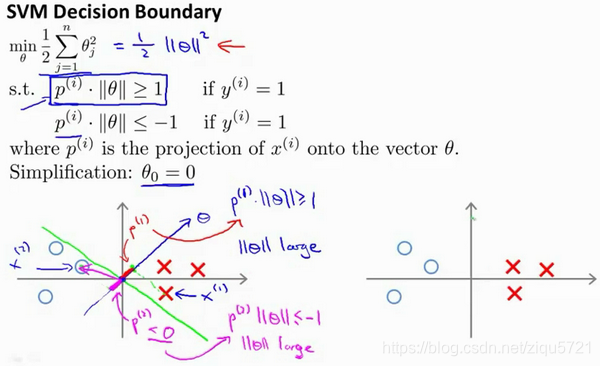
比如这个样本,我们假设它是我的第一个样本
x
(
1
)
x^{(1)}
x(1),如果我考察这个样本到参数
θ
{{\theta }}
θ的投影,投影是这个短的红线段,就等于
p
(
1
)
p^{(1)}
p(1),它非常短。类似地,这个样本如果它恰好是
x
(
2
)
x^{(2)}
x(2),我的第二个训练样本,则它到
θ
{{\theta }}
θ的投影在这里。我将它画成粉色,这个短的粉色线段是
p
(
2
)
p^{(2)}
p(2),即第二个样本到我的参数向量
θ
{{\theta }}
θ的投影。因此,这个投影非常短。
p
(
2
)
p^{(2)}
p(2)事实上是一个负值,
p
(
2
)
p^{(2)}
p(2)是在相反的方向,这个向量和参数向量
θ
{{\theta }}
θ的夹角大于90度,
p
(
2
)
p^{(2)}
p(2)的值小于0。
我们会发现这些
p
(
i
)
p^{(i)}
p(i)将会是非常小的数,因此当我们考察优化目标函数的时候,对于正样本而言,我们需要
p
(
i
)
⋅
∥
θ
∥
>
=
1
p^{(i)}\cdot{\left\| \theta \right\|}>=1
p(i)⋅∥θ∥>=1,但是如果
p
(
i
)
p^{(i)}
p(i)在这里非常小,那就意味着我们需要
θ
{{\theta }}
θ的范数非常大.因为如果
p
(
1
)
p^{(1)}
p(1) 很小,而我们希望
p
(
1
)
⋅
∥
θ
∥
>
=
1
p^{(1)}\cdot{\left\| \theta \right\|}>=1
p(1)⋅∥θ∥>=1,令其实现的唯一的办法就是这两个数较大。如果
p
(
1
)
p^{(1)}
p(1) 小,我们就希望
θ
{{\theta }}
θ的范数大。类似地,对于负样本而言我们需要
p
(
2
)
⋅
∥
θ
∥
<
=
−
1
p^{(2)}\cdot{\left\|\theta \right\|}<=-1
p(2)⋅∥θ∥<=−1。我们已经在这个样本中看到
p
(
2
)
p^{(2)}
p(2)会是一个非常小的数,因此唯一的办法就是
θ
{{\theta }}
θ的范数变大。但是我们的目标函数是希望找到一个参数
θ
{{\theta }}
θ,它的范数是小的。因此,这看起来不像是一个好的参数向量
θ
{{\theta }}
θ的选择。
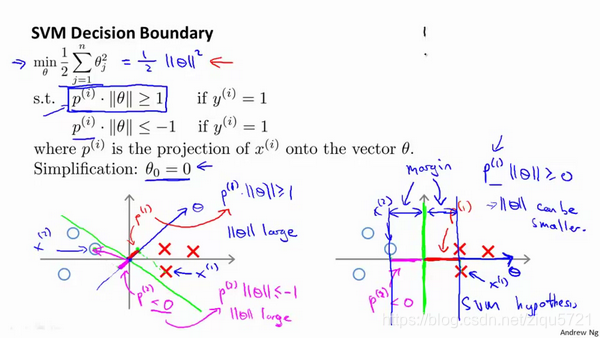
相反的,来看一个不同的决策边界。比如说,支持向量机选择了这个决策界,现在状况会有很大不同。如果这是决策界,这就是相对应的参数 θ {{\theta }} θ的方向,因此,在这个决策界之下,垂直线是决策界。使用线性代数的知识,可以说明,这个绿色的决策界有一个垂直于它的向量 θ {{\theta }} θ。现在如果你考察你的数据在横轴 x x x上的投影,比如这个我之前提到的样本,我的样本 x ( 1 ) x^{(1)} x(1),当我将它投影到横轴 x x x上,或说投影到 θ {{\theta }} θ上,就会得到这样 p ( 1 ) p^{(1)} p(1)。它的长度是 p ( 1 ) p^{(1)} p(1),另一个样本,那个样本是 x ( 2 ) x^{(2)} x(2)。我做同样的投影,我会发现, p ( 2 ) p^{(2)} p(2)的长度是负值。你会注意到现在 p ( 1 ) p^{(1)} p(1) 和 p ( 2 ) p^{(2)} p(2)这些投影长度是长多了。如果我们仍然要满足这些约束, P ( i ) ⋅ ∥ θ ∥ P^{(i)}\cdot{\left\| \theta \right\|} P(i)⋅∥θ∥>1,则因为 p ( 1 ) p^{(1)} p(1)变大了, θ {{\theta }} θ的范数就可以变小了。因此这意味着通过选择右边的决策界,而不是左边的那个,支持向量机可以使参数 θ {{\theta }} θ的范数变小很多。因此,如果我们想令 θ {{\theta }} θ的范数变小,从而令 θ {{\theta }} θ范数的平方变小,就能让支持向量机选择右边的决策界。这就是支持向量机如何能有效地产生大间距分类的原因。
看这条绿线,这个绿色的决策界。我们希望正样本和负样本投影到 θ \theta θ的值大。要做到这一点的唯一方式就是选择这条绿线做决策界。这是大间距决策界来区分开正样本和负样本这个间距的值。这个间距的值就是 p ( 1 ) , p ( 2 ) , p ( 3 ) p^{(1)},p^{(2)},p^{(3)} p(1),p(2),p(3)等等的值。通过让间距变大,即通过这些 p ( 1 ) , p ( 2 ) , p ( 3 ) p^{(1)},p^{(2)},p^{(3)} p(1),p(2),p(3)等等的值,支持向量机最终可以找到一个较小的 θ {{\theta }} θ范数。这正是支持向量机中最小化目标函数的目的。
以上就是为什么支持向量机最终会找到大间距分类器的原因。因为它试图极大化这些
p
(
i
)
p^{(i)}
p(i)的范数,它们是训练样本到决策边界的距离。最后一点,我们的推导自始至终使用了这个简化假设,就是参数
θ
0
=
0
θ_0=0
θ0=0。
这个的作用是: θ 0 = 0 θ_0=0 θ0=0的意思是我们让决策界通过原点。如果你令 θ 0 θ_0 θ0不是0的话,含义就是你希望决策界不通过原点。我将不会做全部的推导。实际上,支持向量机产生大间距分类器的结论,会被证明同样成立,证明方式是非常类似的,是我们刚刚做的证明的推广。
之前说过,即便 θ 0 θ_0 θ0不等于0,支持向量机要做的事情都是优化这个目标函数对应着 C C C值非常大的情况,但是可以说明的是,即便 θ 0 θ_0 θ0不等于0,支持向量机仍然会找到正样本和负样本之间的大间距分隔。
12.2 核函数1
回顾我们之前讨论过可以使用高级数的多项式模型来解决无法用直线进行分隔的分类问题:
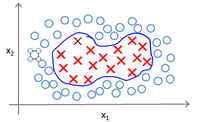
为了获得上图所示的判定边界,我们的模型可能是
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
θ
3
x
1
x
2
+
θ
4
x
1
2
+
θ
5
x
2
2
+
⋯
{{\theta }_{0}}+{{\theta }_{1}}{{x}_{1}}+{{\theta }_{2}}{{x}_{2}}+{{\theta }_{3}}{{x}_{1}}{{x}_{2}}+{{\theta }_{4}}x_{1}^{2}+{{\theta }_{5}}x_{2}^{2}+\cdots
θ0+θ1x1+θ2x2+θ3x1x2+θ4x12+θ5x22+⋯的形式。
我们可以用一系列的新的特征 f f f来替换模型中的每一项。例如令: f 1 = x 1 , f 2 = x 2 , f 3 = x 1 x 2 , f 4 = x 1 2 , f 5 = x 2 2 {{f}_{1}}={{x}_{1}},{{f}_{2}}={{x}_{2}},{{f}_{3}}={{x}_{1}}{{x}_{2}},{{f}_{4}}=x_{1}^{2},{{f}_{5}}=x_{2}^{2} f1=x1,f2=x2,f3=x1x2,f4=x12,f5=x22…得到 h θ ( x ) = θ 1 f 1 + θ 2 f 2 + . . . + θ n f n h_θ(x)={{\theta }_{1}}f_1+{{\theta }_{2}}f_2+...+{{\theta }_{n}}f_n hθ(x)=θ1f1+θ2f2+...+θnfn。然而,除了对原有的特征进行组合以外,有没有更好的方法来构造 f 1 , f 2 , f 3 f_1,f_2,f_3 f1,f2,f3?我们可以利用核函数来计算出新的特征。
给定一个训练样本
x
x
x,我们利用
x
x
x的各个特征与我们预先选定的地标(landmarks)
l
(
1
)
,
l
(
2
)
,
l
(
3
)
l^{(1)},l^{(2)},l^{(3)}
l(1),l(2),l(3)的近似程度来选取新的特征
f
1
,
f
2
,
f
3
f_1,f_2,f_3
f1,f2,f3。
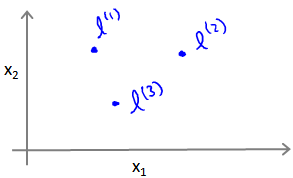
例如:
f
1
=
s
i
m
i
l
a
r
i
t
y
(
x
,
l
(
1
)
)
=
e
(
−
∥
x
−
l
(
1
)
∥
2
2
σ
2
)
{{f}_{1}}=similarity(x,{{l}^{(1)}})=e(-\frac{{{\left\| x-{{l}^{(1)}} \right\|}^{2}}}{2{{\sigma }^{2}}})
f1=similarity(x,l(1))=e(−2σ2∥x−l(1)∥2)
其中: ∥ x − l ( 1 ) ∥ 2 = ∑ j = 1 n ( x j − l j ( 1 ) ) 2 {{\left\| x-{{l}^{(1)}} \right\|}^{2}}=\sum{_{j=1}^{n}}{{({{x}_{j}}-l_{j}^{(1)})}^{2}} ∥∥x−l(1)∥∥2=∑j=1n(xj−lj(1))2,为实例 x x x中所有特征与地标 l ( 1 ) l^{(1)} l(1)之间的距离的和。上例中的 s i m i l a r i t y ( x , l ( 1 ) ) similarity(x,{{l}^{(1)}}) similarity(x,l(1))就是核函数,具体而言,这里是一个高斯核函数(Gaussian Kernel)。 注:这个函数与正态分布没什么实际上的关系,只是看上去像而已。
这些地标的作用是什么?如果一个训练样本 x x x与地标 l l l之间的距离近似于0,则新特征 f f f近似于 e − 0 = 1 e^{-0}=1 e−0=1,如果训练样本 x x x与地标 l l l之间距离较远,则 f f f近似于 e − ( 一 个 较 大 的 数 ) = 0 e^{-(一个较大的数)}=0 e−(一个较大的数)=0。
假设我们的训练样本含有两个特征[
x
1
x_{1}
x1
x
2
x{_2}
x2],给定地标
l
(
1
)
l^{(1)}
l(1)与不同的
σ
\sigma
σ值,见下图:
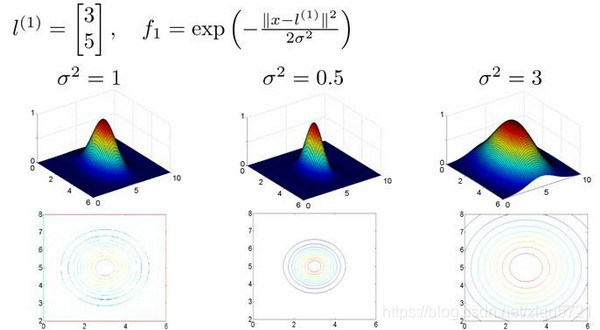
图中水平面的坐标为
x
1
x_{1}
x1,
x
2
x_{2}
x2而垂直坐标轴代表
f
f
f。可以看出,只有当
x
x
x与
l
(
1
)
l^{(1)}
l(1)重合时
f
f
f才具有最大值。随着
x
x
x的改变
f
f
f值改变的速率受到
σ
2
\sigma^2
σ2的控制。
在下图中,当样本处于洋红色的点位置处,因为其离
l
(
1
)
l^{(1)}
l(1)更近,但是离
l
(
2
)
l^{(2)}
l(2)和
l
(
3
)
l^{(3)}
l(3)较远,因此
f
1
f_1
f1接近1,而
f
2
f_2
f2,
f
3
f_3
f3接近0。因此
h
θ
(
x
)
=
θ
0
+
θ
1
f
1
+
θ
2
f
2
+
θ
1
f
3
>
0
h_θ(x)=θ_0+θ_1f_1+θ_2f_2+θ_1f_3>0
hθ(x)=θ0+θ1f1+θ2f2+θ1f3>0,因此预测
y
=
1
y=1
y=1。同理可以求出,对于离
l
(
2
)
l^{(2)}
l(2)较近的绿色点,也预测
y
=
1
y=1
y=1,但是对于蓝绿色的点,因为其离三个地标都较远,预测
y
=
0
y=0
y=0。
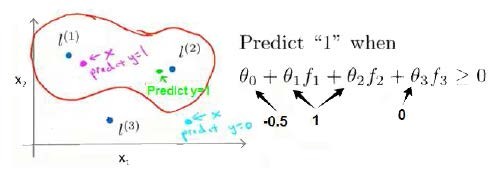
这样,图中红色的封闭曲线所表示的范围,便是我们依据一个单一的训练样本和我们选取的地标所得出的判定边界,在预测时,我们采用的特征不是训练样本本身的特征,而是通过核函数计算出的新特征
f
1
,
f
2
,
f
3
f_1,f_2,f_3
f1,f2,f3。
12.3 核函数2
在上一节我们讨论了核函数这个想法,以及怎样利用它去实现支持向量机的一些新特性。在这一节我将补充一些缺失的细节,并简单的介绍一下怎么在实际中使用应用这些想法。
如何选择地标?
我们通常是根据训练集的数量选择地标的数量,即如果训练集中有
m
m
m个样本,则我们选取
m
m
m个地标,并且令:
l
(
1
)
=
x
(
1
)
,
l
(
2
)
=
x
(
2
)
,
.
.
.
.
.
,
l
(
m
)
=
x
(
m
)
l^{(1)}=x^{(1)},l^{(2)}=x^{(2)},.....,l^{(m)}=x^{(m)}
l(1)=x(1),l(2)=x(2),.....,l(m)=x(m)。这样做的好处在于:现在我们得到的新特征是建立在原有特征与训练集中所有其他特征之间距离的基础之上的,即:
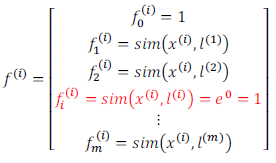

下面我们将核函数运用到支持向量机中,修改我们的支持向量机假设为:
• 给定 x x x,计算新特征 f f f,当 θ T f > = 0 θ^Tf>=0 θTf>=0 时,预测 y = 1 y=1 y=1,否则反之。
相应地修改代价函数为: ∑ j = 1 n = m θ j 2 = θ T θ \sum{_{j=1}^{n=m}}\theta _{j}^{2}={{\theta}^{T}}\theta ∑j=1n=mθj2=θTθ,
m
i
n
C
∑
i
=
1
m
[
y
(
i
)
c
o
s
t
1
(
θ
T
f
(
i
)
)
+
(
1
−
y
(
i
)
)
c
o
s
t
0
(
θ
T
f
(
i
)
)
]
+
1
2
∑
j
=
1
n
=
m
θ
j
2
min C\sum\limits_{i=1}^{m}{[{{y}^{(i)}}cos {{t}_{1}}}( {{\theta }^{T}}{{f}^{(i)}})+(1-{{y}^{(i)}})cos {{t}_{0}}( {{\theta }^{T}}{{f}^{(i)}})]+\frac{1}{2}\sum\limits_{j=1}^{n=m}{\theta _{j}^{2}}
minCi=1∑m[y(i)cost1(θTf(i))+(1−y(i))cost0(θTf(i))]+21j=1∑n=mθj2
在具体实施过程中,我们还需要对最后的正则化项进行些微调整,在计算
∑
j
=
1
n
=
m
θ
j
2
=
θ
T
θ
\sum{_{j=1}^{n=m}}\theta _{j}^{2}={{\theta}^{T}}\theta
∑j=1n=mθj2=θTθ时,我们用
θ
T
M
θ
θ^TMθ
θTMθ代替
θ
T
θ
θ^Tθ
θTθ,其中
M
M
M是根据我们选择的核函数而不同的一个矩阵。这样做的原因是为了简化计算。
理论上讲,我们也可以在逻辑回归中使用核函数,但是上面使用 M M M来简化计算的方法不适用与逻辑回归,因此计算将非常耗费时间。
在此,我们不介绍最小化支持向量机的代价函数的方法,你可以使用现有的软件包(如liblinear,libsvm等)。在使用这些软件包最小化我们的代价函数之前,我们通常需要编写核函数,并且如果我们使用高斯核函数,那么在使用之前进行特征缩放是非常必要的。
另外,支持向量机也可以不使用核函数,不使用核函数又称为线性核函数(linear kernel),当我们不采用非常复杂的函数,或者我们的训练集特征非常多而样本非常少的时候,可以采用这种不带核函数的支持向量机。
下面是支持向量机的两个参数 C C C和 σ \sigma σ的影响:
C = 1 / λ C=1/\lambda C=1/λ
C C C 较大时,相当于 λ \lambda λ较小,可能会导致过拟合,高方差;
C C C 较小时,相当于 λ \lambda λ较大,可能会导致低拟合,高偏差;
σ \sigma σ较大时,可能会导致低方差,高偏差;
σ \sigma σ较小时,可能会导致低偏差,高方差。
12.4 使用支持向量机
目前为止,我们已经讨论了SVM比较抽象的层面,在这个视频中我将要讨论到为了运行或者运用SVM。你实际上所需要的一些东西:支持向量机算法,提出了一个特别优化的问题。但是就如在之前的视频中我简单提到的,我真的不建议你自己写软件来求解参数 θ {{\theta }} θ,因此由于今天我们中的很少人,或者其实没有人考虑过自己写代码来转换矩阵,或求一个数的平方根等我们只是知道如何去调用库函数来实现这些功能。同样的,用以解决SVM最优化问题的软件很复杂,且已经有研究者做了很多年数值优化了。因此你提出好的软件库和好的软件包来做这样一些事儿。然后强烈建议使用高优化软件库中的一个,而不是尝试自己落实一些数据。有许多好的软件库,我正好用得最多的两个是liblinear和libsvm,但是真的有很多软件库可以用来做这件事儿。你可以连接许多你可能会用来编写学习算法的主要编程语言。
在高斯核函数之外我们还有其他一些选择,如:
多项式核函数(Polynomial Kernel)
字符串核函数(String kernel)
卡方核函数( chi-square kernel)
直方图交集核函数(histogram intersection kernel)
等等…
这些核函数的目标也都是根据训练集和地标之间的距离来构建新特征,这些核函数需要满足Mercer’s定理,才能被支持向量机的优化软件正确处理。
多类分类问题
假设我们利用之前介绍的一对多方法来解决一个多类分类问题。如果一共有 k k k个类,则我们需要 k k k个模型,以及 k k k个参数向量 θ {{\theta }} θ。我们同样也可以训练 k k k个支持向量机来解决多类分类问题。但是大多数支持向量机软件包都有内置的多类分类功能,我们只要直接使用即可。
尽管你不去写你自己的SVM的优化软件,但是你也需要做几件事:
1、是提出参数 C C C的选择。我们在之前的视频中讨论过误差/方差在这方面的性质。
2、你也需要选择内核参数或你想要使用的相似函数,其中一个选择是:我们选择不需要任何内核参数,没有内核参数的理念,也叫线性核函数。因此,如果有人说他使用了线性核的SVM(支持向量机),这就意味这他使用了不带有核函数的SVM(支持向量机)。
从逻辑回归模型,我们得到了支持向量机模型,在两者之间,我们应该如何选择呢?
下面是一些普遍使用的准则:
n n n为特征数, m m m为训练样本数。
(1)如果相较于 m m m而言, n n n要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
(2)如果 n n n较小,而且 m m m大小中等,例如 n n n在 1-1000 之间,而 m m m在10-10000之间,使用高斯核函数的支持向量机。
(3)如果 n n n较小,而 m m m较大,例如 n n n在1-1000之间,而 m m m大于50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。
值得一提的是,神经网络在以上三种情况下都可能会有较好的表现,但是训练神经网络可能非常慢,选择支持向量机的原因主要在于它的代价函数是凸函数,不存在局部最小值。
参考资料: 吴恩达机器学习课程;黄海广机器学习课程笔记

















 976
976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









