




 本文详细介绍了如何在Hadoop和HBase中集成Snappy压缩库,包括Linux上安装Snappy、编译Hadoop源码、在Hadoop中添加Snappy支持、在HBase中添加Snappy支持以及测试Snappy压缩效果的全过程。
本文详细介绍了如何在Hadoop和HBase中集成Snappy压缩库,包括Linux上安装Snappy、编译Hadoop源码、在Hadoop中添加Snappy支持、在HBase中添加Snappy支持以及测试Snappy压缩效果的全过程。
| (1)hadoop2.7.1源码编译 | http://aperise.iteye.com/blog/2246856 |
| (2)hadoop2.7.1安装准备 | http://aperise.iteye.com/blog/2253544 |
| (3)1.x和2.x都支持的集群安装 | http://aperise.iteye.com/blog/2245547 |
| (4)hbase安装准备 | http://aperise.iteye.com/blog/2254451 |
| (5)hbase安装 | http://aperise.iteye.com/blog/2254460 |
| (6)snappy安装 | http://aperise.iteye.com/blog/2254487 |
| (7)hbase性能优化 | http://aperise.iteye.com/blog/2282670 |
| (8)雅虎YCSBC测试hbase性能测试 | http://aperise.iteye.com/blog/2248863 |
| (9)spring-hadoop实战 | http://aperise.iteye.com/blog/2254491 |
| (10)基于ZK的Hadoop HA集群安装 | http://aperise.iteye.com/blog/2305809 |
lzo snappy gzip是hadoop支持的三种压缩方式,目前网上推荐snappy,这里讲解如何安装snappy
1.在linux上安装snappy压缩库
#1.去https://github.com/google/snappy/releases下载snappy-1.1.3.tar.gz并解压
cd /root
wget https://github.com/google/snappy/releases/download/1.1.3/snappy-1.1.3.tar.gz
tar -zxvf snappy-1.1.3.tar.gz
#2.在linux上编译安装
cd /root/snappy-1.1.3
./configure
make
make install
#3.默认安装在/usr/local/lib,安装成功后文件如下:

github上Hadoop源码(https://github.com/apache/hadoop/blob/trunk/BUILDING.txt)推荐的安装方式为:sudo apt-get install snappy libsnappy-dev
2.编译Hadoop2.7.1源码中模块hadoop-common
当前Hadoop新的版本在模块hadoop-common中都已经集成了相关压缩库的编解码工具,无需去其它地方下载编解码打包:
如果之前编译过Hadoop源代码,这一步骤可以不做。
官网给定的安装包中是不支持snappy压缩的,需要自己重新编译Hadoop源码,而编译源码首先需要保证linux上已经安装了linux关于snappy的库,已经在步骤1中解决。
关于如何编译Hadoop源代码,请参见http://aperise.iteye.com/blog/2246856
1.下载hadoop源代码hadoop-2.7.1-src.tar.gz放置于/root下并解压缩
cd /root
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.1/hadoop-2.7.1-src.tar.gz
tar -zxvf hadoop-2.7.1-src.tar.gz 2.准备Hadoop编译必备环境,请参见http://aperise.iteye.com/blog/2246856
3.单独编译打包hadoop-common,获取对于snappy压缩的支持(如果想编译整个工程请参见http://aperise.iteye.com/blog/2246856)
cd /root/hadoop-2.7.1-src
export MAVEN_OPTS="-Xms256m -Xmx512m"
mvn package -Pdist,native -DskipTests -Dtar -rf :hadoop-common -Drequire.snappy -X
#如果想编译整个代码且单独指定snappy库位置,命令如下:
#mvn package -Pdist,native,docs,src -DskipTests -Drequire.snappy -Dsnappy.lib=/usr/local/lib 4.编译完成后,在/root/hadoop-2.7.1-src/hadoop-dist/target/hadoop-2.7.1/lib/native下得到如下文件: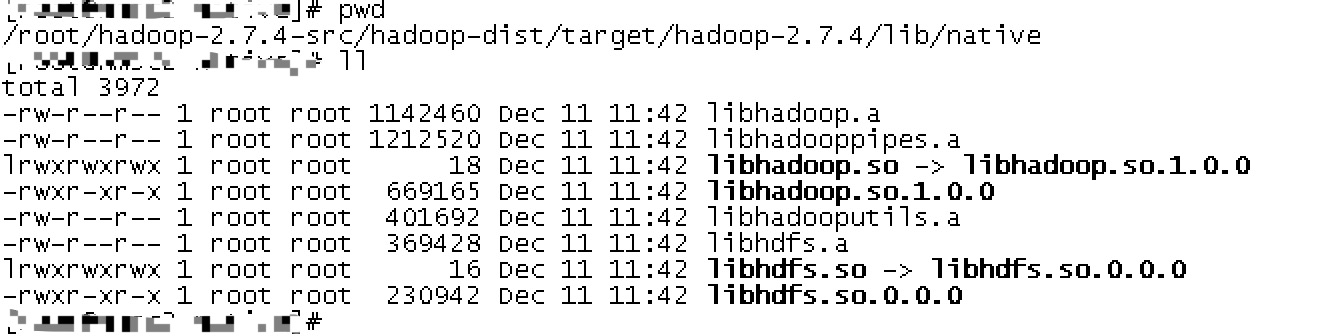
5.编译完成后,在/root/hadoop-2.7.1-src/hadoop-dist/target/hadoop-2.7.1/share/hadoop/common下得到如下文件: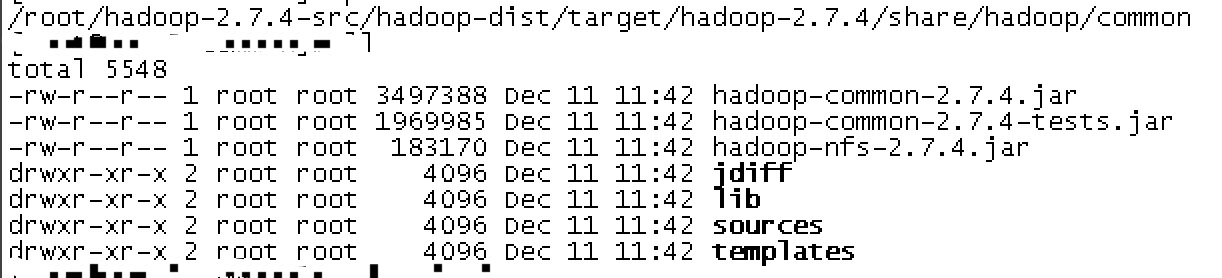
3.hadooo中添加snappy支持
#1.将步骤2中编译的snappy支持文件拷贝到Hadoop中
#这里我安装的Hadoop位置为/home/hadoop/hadoop-2.7.1
cp -r /root/hadoop-2.7.1-src/hadoop-dist/target/hadoop-2.7.1/lib/native/* /home/hadoop/hadoop-2.7.1/lib/native/
cp /usr/local/lib/* /home/hadoop/hadoop-2.7.1/lib/native/
#2.将步骤3编译后的hadoop-common-2.7.1.jar文件拷贝到Hadoop
#这里我安装的Hadoop位置为/home/hadoop/hadoop-2.7.1
cp -r /root/hadoop-2.7.1-src/hadoop-dist/target/hadoop-2.7.1/share/hadoop/common/* /home/hadoop/hadoop-2.7.1/share/hadoop/common/
#3.修改hadoop的配置文件/home/hadoop/hadoop-2.7.1/etc/hadoop/core-site.xml,增加如下配置:
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.Lz4Codec,
org.apache.hadoop.io.compress.SnappyCodec
</value>
<description>A comma-separated list of the compression codec classes that can
be used for compression/decompression. In addition to any classes specified
with this property (which take precedence), codec classes on the classpath
are discovered using a Java ServiceLoader.</description>
</property>
#4.修改/home/hadoop/hadoop-2.7.1/etc/hadoop/mapred-site.xml,添加如下内容:
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
<description>Should the job outputs be compressed?
</description>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.type</name>
<value>RECORD</value>
<description>If the job outputs are to compressed as SequenceFiles, how should
they be compressed? Should be one of NONE, RECORD or BLOCK.
</description>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description>If the job outputs are compressed, how should they be compressed?
</description>
</property>
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
<description>Should the outputs of the maps be compressed before being
sent across the network. Uses SequenceFile compression.
</description>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description>If the map outputs are compressed, how should they be
compressed?
</description>
</property> 至此,Hadoop中已经可以支持snappy压缩算法了,hbase目前还待配置,请往下看。
4.hbase中添加snappy支持
#1.在hbase中创建放置Hadoop对于本地库支持的文件目录
mkdir -p /home/hadoop/hbase-1.2.1/lib/native/Linux-amd64-64
#2.拷贝Hadoop中所有本地库支持到hbase中
cp -r /home/hadoop/hadoop2.7.1/lib/native/* /home/hadoop/hbase-1.2.1/lib/native/Linux-amd64-64/
至此,hbase中已经添加了对于snappy的支持。
5.在hbase中测试snappy
cd /home/hadoop/hbase-1.2.1/bin/
./hbase org.apache.hadoop.hbase.util.CompressionTest hdfs://hadoop-ha-cluster/hbase/data/default/signal/3a194dcd996fd03c0c26bf3d175caaec/info/0c7f62f10a4c4e548c5ff1c583b0bdfa snappy 上面hdfs://hadoop-ha-cluster/hbase/data/default/signal/3a194dcd996fd03c0c26bf3d175caaec/info/0c7f62f10a4c4e548c5ff1c583b0bdfa是存在于我Hadoop上的HDFS文件

6.HDFS中如何查看压缩格式为snappy的文件
hdfs dfs -text /aaa.snappy

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









