



 文章详细介绍了在Ceph集群管理中遇到的问题:在配置主管理节点时,因未在所有节点添加UDEV规则而导致vdb1和vdb2设备重启后权限归属错误。通过在每个节点的/uve/rules.d目录下创建并编辑90-cephdisk.rules文件,添加了相应的UDEV规则,从而解决了设备权限归属问题。操作步骤包括编辑规则文件、重启主机以应用更改。
文章详细介绍了在Ceph集群管理中遇到的问题:在配置主管理节点时,因未在所有节点添加UDEV规则而导致vdb1和vdb2设备重启后权限归属错误。通过在每个节点的/uve/rules.d目录下创建并编辑90-cephdisk.rules文件,添加了相应的UDEV规则,从而解决了设备权限归属问题。操作步骤包括编辑规则文件、重启主机以应用更改。
重启ceph的时候,在配置主管理节点查看ceph的状态的时候报错。
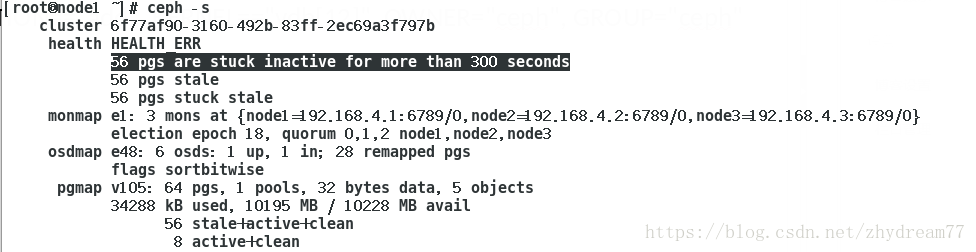
报错原因是忘记在node2,node3节点加UDEV规则,使得vdb1和vdb2重启后,属主属组仍然是ceph,在配置的ceph的三个节点加入以下的规则,在重启三台主机。
[root@node1~]# vim /etc/udev/rules.d/90-cephdisk.rules
ACTION=="add",KERNEL=="vdb[12]", OWNER="ceph", GROUP="ceph"
[root@node1~]# vim /etc/udev/rules.d/90-cephdisk.rules
ACTION=="add",KERNEL=="vdb[12]", OWNER="ceph", GROUP="ceph"
[root@node2~]# vim /etc/udev/rules.d/90-cephdisk.rules
ACTION=="add",KERNEL=="vdb[12]", OWNER="ceph", GROUP="ceph"
[root@node3~]# vim /etc/udev/rules.d/90-cephdisk.rules
ACTION=="add",KERNEL=="vdb[12]", OWNER="ceph", GROUP="ceph"

















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









