




 本文探讨使用多种机器学习算法预测泰坦尼克号乘客生存率,包括数据预处理、特征工程及模型评估,如线性回归、逻辑回归、随机森林和集成学习。
本文探讨使用多种机器学习算法预测泰坦尼克号乘客生存率,包括数据预处理、特征工程及模型评估,如线性回归、逻辑回归、随机森林和集成学习。
主要内容:
缺失值的填充
特征中的字符串映射为int或float操作
特征构造
对特征的重要性进行分析以及可视化操作
算法:线性回归 逻辑回归 随机森林 集成方法分类
#分析泰坦尼克号获救情况
import pandas
titanic = pandas.read_csv('./titantic_data/train.csv')
# print(titanic.head())
# print(titanic.describe())
#通过数据分析发现Age特征中存在200多个缺失值,所以需要对缺失数据进行填充
# print(titanic.Age.unique())
titanic['Age'] = titanic['Age'].fillna(titanic['Age'].median())
# print(titanic.describe())
#因为特征项中存在字符串 例如 性别等 所以需要将他转换为 int或float型
# print(titanic['Sex'].unique())
titanic.loc[titanic['Sex'] == 'male','Sex'] = 0
titanic.loc[titanic['Sex'] == 'female','Sex'] = 1
# print(titanic['Embarked'].unique())
titanic['Embarked'] = titanic['Embarked'].fillna('S')
titanic.loc[titanic['Embarked'] == 'S','Embarked'] = 0
titanic.loc[titanic['Embarked'] == 'C','Embarked'] = 1
titanic.loc[titanic['Embarked'] == 'Q','Embarked'] = 2
#尝试用线性回归对数据进行分类
from sklearn.linear_model import LinearRegression
from sklearn.cross_validation import KFold
#选择需要的特征
predictors = ['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']
alg = LinearRegression()
kf = KFold(titanic.shape[0],n_folds=3,random_state=1)
predictions = []
for train,test in kf:
train_predictors = (titanic[predictors].iloc[train,:])
train_target = titanic['Survived'].iloc[train]
alg.fit(train_predictors,train_target)
test_predictions = alg.predict(titanic[predictors].iloc[test,:])
predictions.append(test_predictions)
import numpy as np
predictions = np.concatenate(predictions,axis=0)
predictions[predictions > .5] = 1
predictions[predictions <= .5] = 0
# accuracy = sum(predictions[predictions == titanic['Survived']]) / len(predictions)
# print(accuracy) #0.78338 实测0.2615039281705948
#尝试用逻辑回归对数据进行分类
from sklearn import cross_validation
from sklearn.linear_model import LogisticRegression
alg = LogisticRegression(random_state=1)
scores = cross_validation.cross_val_score(alg, titanic[predictors],titanic['Survived'],cv =3)
print(scores.mean()) #实测0.7878787878787877
#随机森林 样本随机(有放回的取样) 特征随机(随机抽取特征) 多个决策树
titanic_test = pandas.read_csv('./titantic_data/test.csv')
titanic_test['Age'] = titanic['Age'].fillna(titanic['Age'].median())
titanic_test['Fare'] = titanic_test['Fare'].fillna(titanic_test['Fare'].median())
titanic_test.loc[titanic_test['Sex'] == 'male','Sex'] = 0
titanic_test.loc[titanic_test['Sex'] == 'female','Sex'] = 1
titanic_test.loc[titanic_test['Embarked'] == 'S','Embarked'] = 0
titanic_test.loc[titanic_test['Embarked'] == 'C','Embarked'] = 1
titanic_test.loc[titanic_test['Embarked'] == 'Q','Embarked'] = 2
from sklearn import cross_validation
from sklearn.ensemble import RandomForestClassifier
predictors = ['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']
alg = RandomForestClassifier(random_state= 1, n_estimators= 10, min_samples_split= 2, min_samples_leaf= 1)
kf = cross_validation.KFold(titanic.shape[0],n_folds=3,random_state=1)
scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic['Survived'],cv = kf)
print(scores.mean()) #0.7856341189674523
#修改一下随机森林的参数 比较一下效果
alg = RandomForestClassifier(random_state= 1, n_estimators= 50, min_samples_split= 4, min_samples_leaf= 2)
kf = cross_validation.KFold(titanic.shape[0],n_folds=3,random_state=1)
scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic['Survived'],cv = kf)
print(scores.mean()) #0.8159371492704826
输出:
D:\F\Anaconda3\lib\site-packages\sklearn\cross_validation.py:44: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.
"This module will be removed in 0.20.", DeprecationWarning)
0.7878787878787877
0.7856341189674523
0.8159371492704826
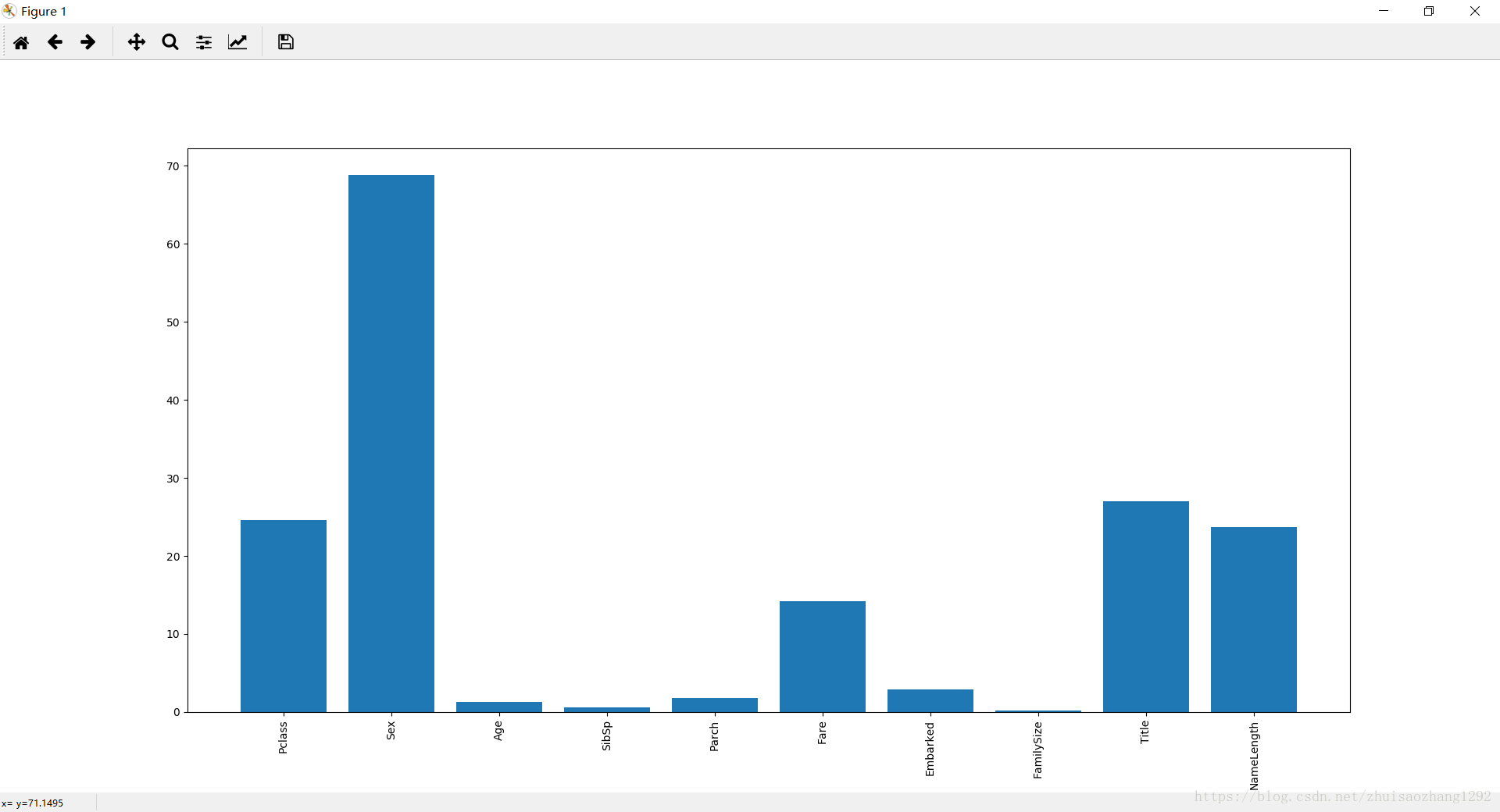
通过Pandas构造特征 并对特征的重要性进行排序 以柱状图展示
import pandas
titanic = pandas.read_csv('./titantic_data/train.csv')
# print(titanic.head())
# print(titanic.describe())
#通过数据分析发现Age特征中存在200多个缺失值,所以需要对缺失数据进行填充
# print(titanic.Age.unique())
titanic['Age'] = titanic['Age'].fillna(titanic['Age'].median())
# print(titanic.describe())
#因为特征项中存在字符串 例如 性别等 所以需要将他转换为 int或float型
# print(titanic['Sex'].unique())
titanic.loc[titanic['Sex'] == 'male','Sex'] = 0
titanic.loc[titanic['Sex'] == 'female','Sex'] = 1
# print(titanic['Embarked'].unique())
titanic['Embarked'] = titanic['Embarked'].fillna('S')
titanic.loc[titanic['Embarked'] == 'S','Embarked'] = 0
titanic.loc[titanic['Embarked'] == 'C','Embarked'] = 1
titanic.loc[titanic['Embarked'] == 'Q','Embarked'] = 2
from sklearn.ensemble import RandomForestClassifier
#通过pandas构造特征
titanic['FamilySize'] = titanic['SibSp'] + titanic['Parch']
titanic['NameLength'] = titanic['Name'].apply(lambda x:len(x))
import re
def get_title(name):
title_search = re.search(' ([A-Za-z]+)\.',name)
if title_search:
return title_search.group(1)
return ''
titles = titanic['Name'].apply(get_title)
print(pandas.value_counts(titles))
title_mapping = {'Mr':1,'Miss':2,'Mrs':3,'Master':4,'Dr':5,'Rev':6,'Major':7,'Col':7,'Mlle':8,'Mme':8,'Don':9,'Lady':10,'Countess':10,'Jonkheer':10,'Sir':9,'Capt':7,'Ms':2}
for k,v in title_mapping.items():
titles[titles == k] = v
titanic['Title'] = titles
#对特征的重要性进行排序 并以柱状图的形式显示出来
import numpy as np
from sklearn.feature_selection import SelectKBest,f_classif
import matplotlib.pyplot as plt
predictors = ['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked','FamilySize','Title','NameLength']
selector = SelectKBest(f_classif,k=5)
selector.fit(titanic[predictors],titanic['Survived'])
scores = -np.log10(selector.pvalues_)
plt.bar(range(len(predictors)),scores)
plt.xticks(range(len(predictors)),predictors,rotation = 'vertical')
plt.show()
predictors = ['Pclass',"sex",'Fare','Title']
alg = RandomForestClassifier(random_state = 1,n_estimators=50,min_samples_split=8,min_samples_leaf=4)
输出:
Mr 517
Miss 182
Mrs 125
Master 40
Dr 7
Rev 6
Mlle 2
Major 2
Col 2
Don 1
Capt 1
Countess 1
Ms 1
Lady 1
Mme 1
Sir 1
Jonkheer 1
Name: Name, dtype: int64
D:\F\Anaconda3\lib\site-packages\sklearn\utils\__init__.py:54: FutureWarning: Conversion of the second argument of issubdtype from `int` to `np.signedinteger` is deprecated. In future, it will be treated as `np.int32 == np.dtype(int).type`.
if np.issubdtype(mask.dtype, np.int):
通过集成学习分类的办法进行分类
#分析泰坦尼克号获救情况
import pandas
titanic = pandas.read_csv('titanic_train.csv')
# print(titanic.head())
# print(titanic.describe())
#通过数据分析发现Age特征中存在200多个缺失值,所以需要对缺失数据进行填充
# print(titanic.isnull().any()) 查看列中是否存在缺失值
titanic['Age'] = titanic['Age'].fillna(titanic['Age'].median())
# print(titanic.describe())
#因为特征项中存在字符串 例如 性别等 所以需要将他转换为 int或float型
# print(titanic['Sex'].unique())
titanic.loc[titanic['Sex'] == 'male','Sex'] = 0
titanic.loc[titanic['Sex'] == 'female','Sex'] = 1
# print(titanic['Embarked'].unique())
# print(titanic['Embarked'].value_counts())
titanic['Embarked'] = titanic['Embarked'].fillna('S')
titanic.loc[titanic['Embarked'] == 'S','Embarked'] = 0
titanic.loc[titanic['Embarked'] == 'C','Embarked'] = 1
titanic.loc[titanic['Embarked'] == 'Q','Embarked'] = 2
# # #尝试用线性回归对数据进行分类
from sklearn.linear_model import LinearRegression
from sklearn.cross_validation import KFold
# #选择需要的特征
predictors = ['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']
alg = LinearRegression()
kf = KFold(titanic.shape[0],n_folds=3,random_state=1)
predictions = []
for train,test in kf:
train_predictors = (titanic[predictors].iloc[train])#,:
train_target = titanic['Survived'].iloc[train]
alg.fit(train_predictors,train_target)
test_predictions = alg.predict(titanic[predictors].iloc[test])#,:
predictions.append(test_predictions)
import numpy as np
# print(predictions)
predictions = np.concatenate(predictions,axis=0)
predictions[predictions > .5] = 1
predictions[predictions <= .5] = 0
# a = predictions == titanic['Survived'] #True: 698, False: 193
# b = predictions[predictions == titanic['Survived']] # 0.0: 465, 1.0: 233
#
# from collections import Counter
# res = Counter(b)
# print(res)
#个人觉得这个精度计算是错误的 ,这边算的是 预测结果正确的值的和 / 预测数据的总长度 其中正确的值中既有0 又有1 算出来的精度就小了
# accuracy = sum(predictions[predictions == titanic['Survived']]) / len(predictions) #0.2615039281705948
#应该更换为下面的计算方式
accuracy = sum(predictions == titanic['Survived']) / len(predictions)
print('LinearRegression accuracy:',accuracy) #0.78338
# # #
# #尝试用逻辑回归对数据进行分类
# from sklearn import cross_validation
from sklearn.linear_model import LogisticRegression
# alg = LogisticRegression(random_state=1)
# scores = cross_validation.cross_val_score(alg, titanic[predictors],titanic['Survived'],cv =3)
# print('LogisticRegression accuracy:',scores.mean()) #实测0.7878787878787877
# #
#随机森林 样本随机(有放回的取样) 特征随机(随机抽取特征) 多个决策树
titanic_test = pandas.read_csv('./titantic_data/test.csv')
titanic_test['Age'] = titanic['Age'].fillna(titanic['Age'].median())
titanic_test['Fare'] = titanic_test['Fare'].fillna(titanic_test['Fare'].median())
titanic_test.loc[titanic_test['Sex'] == 'male','Sex'] = 0
titanic_test.loc[titanic_test['Sex'] == 'female','Sex'] = 1
titanic_test.loc[titanic_test['Embarked'] == 'S','Embarked'] = 0
titanic_test.loc[titanic_test['Embarked'] == 'C','Embarked'] = 1
titanic_test.loc[titanic_test['Embarked'] == 'Q','Embarked'] = 2
# from sklearn import cross_validation
from sklearn.ensemble import RandomForestClassifier
# predictors = ['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']
# alg = RandomForestClassifier(random_state= 1, n_estimators= 10, min_samples_split= 2, min_samples_leaf= 1)
# kf = cross_validation.KFold(titanic.shape[0],n_folds=3,random_state=1)
# scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic['Survived'],cv = kf)
# print('RandomForestClassifier accuracy:',scores.mean()) #0.7856341189674523
# # #修改一下随机森林的参数 比较一下效果
# alg = RandomForestClassifier(random_state= 1, n_estimators= 500, min_samples_split= 4, min_samples_leaf= 2)
# kf = cross_validation.KFold(titanic.shape[0],n_folds=3,random_state=1)
# scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic['Survived'],cv = kf)
# print(scores.mean()) #0.8159371492704826
#通过pandas构造特征
titanic['FamilySize'] = titanic['SibSp'] + titanic['Parch']
titanic['NameLength'] = titanic['Name'].apply(lambda x:len(x))
import re
def get_title(name):
title_search = re.search(' ([A-Za-z]+)\.',name)
if title_search:
return title_search.group(1)
return ''
titles = titanic['Name'].apply(get_title)
# print(pandas.value_counts(titles))
title_mapping = {'Mr':1,'Miss':2,'Mrs':3,'Master':4,'Dr':5,'Rev':6,'Major':7,'Col':7,'Mlle':8,'Mme':8,'Don':9,'Lady':10,'Countess':10,'Jonkheer':10,'Sir':9,'Capt':7,'Ms':2}
for k,v in title_mapping.items():
titles[titles == k] = v
titanic['Title'] = titles
# #对特征的重要性进行排序 并以柱状图的形式显示出来
import numpy as np
from sklearn.feature_selection import SelectKBest,f_classif
import matplotlib.pyplot as plt
predictors = ['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked','FamilySize','Title','NameLength']
selector = SelectKBest(f_classif,k=5)
selector.fit(titanic[predictors],titanic['Survived'])
scores = -np.log10(selector.pvalues_)
plt.bar(range(len(predictors)),scores)
plt.xticks(range(len(predictors)),predictors,rotation = 'vertical')
# plt.show()
predictors = ['Pclass',"sex",'Fare','Title']
alg = RandomForestClassifier(random_state = 1,n_estimators=50,min_samples_split=8,min_samples_leaf=4)
#
#通过集成的方法进行分类
#训练
from sklearn.ensemble import GradientBoostingClassifier
import numpy as np
algorithms = [
[GradientBoostingClassifier(random_state=1,n_estimators=25,max_depth=3),['Pclass','Sex','Fare','FamilySize','Title','Age','Embarked']],
[LogisticRegression(random_state=1),['Pclass','Sex','Fare','FamilySize','Title','Age','Embarked']]
]
kf = KFold(titanic.shape[0],n_folds=3,random_state=1)
predictions = []
for train,test in kf:
train_target = titanic['Survived'].iloc[train]
full_test_predictinons = []
for alg,predictors in algorithms:
alg.fit(titanic[predictors].iloc[train,:],train_target)
test_predictions = alg.predict_proba(titanic[predictors].iloc[test,:].astype(float))[:,1]
full_test_predictinons.append(test_predictions)
test_predictions = (full_test_predictinons[0] + full_test_predictinons[1]) / 2
test_predictions[test_predictions <= .5] = 0
test_predictions[test_predictions > .5] = 1
predictions.append(test_predictions)
# import numpy as np
predictions = np.concatenate(predictions,axis = 0)
#这个计算公式也是错误的 同上
# accuracy = sum(predictions[predictions == titanic['Survived']]) / len(predictions) #实测0.27946127946127947
#将其改为下面计算公式
accuracy = sum(predictions == titanic['Survived']) / len(predictions)
print('GradientBoostingClassifier accuracy:',accuracy) #0.82154
# #测试 通过上面的分析 可以在测试中给不同的分类器加以不同的权重
##下面这个程序运行不了 因为title_mapping 没有映射全
# titles = titanic_test['Name'].apply(get_title)
# title_mapping = {'Mr':1,'Miss':2,'Mrs':3,'Master':4,'Dr':5,'Rev':6,'Major':7,'Col':7,'Mile':8,'Mme':8,'Don':9,'Lady':10,'Countess':10,'Jonkheer':10,'Sir':9,'Capt':7,'Ms':2}
# for k,v in title_mapping.items():
# titles[titles == k] = v
# titanic['Title'] = titles
# print(pandas.value_counts(titanic_test['Title']))
# titanic_test['FamilySize'] = titanic_test['SibSp'] + titanic_test['Parch']
# predictors = ['Pclass','Sex','Age','Fare','Embarked','FamilySize','Title']
# algorithms = [
# [GradientBoostingClassifier(random_state=1,n_estimators=25,max_depth=3),predictors],
# [LogisticRegression(random_state=1),['Pclass','Sex','Fare','FamilySize','Title','Age','Embarked']]
# ]
# full_predictions = []
# for alg,predictors in algorithms:
# alg.fit(titanic[predictors],titanic['Survived'])
# predictions = alg.predict_proba(titanic_test[predictors].astype(float))[:,1]
# full_predictions.append(predictions)
# predictions = (full_predictions[0] * 3 + full_predictions[1]) / 4
# print(predictions)
输出:
D:\F\Anaconda3\lib\site-packages\sklearn\cross_validation.py:44: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.
"This module will be removed in 0.20.", DeprecationWarning)
LinearRegression accuracy: 0.7833894500561167
D:\F\Anaconda3\lib\site-packages\sklearn\utils\__init__.py:54: FutureWarning: Conversion of the second argument of issubdtype from `int` to `np.signedinteger` is deprecated. In future, it will be treated as `np.int32 == np.dtype(int).type`.
if np.issubdtype(mask.dtype, np.int):
GradientBoostingClassifier accuracy: 0.8215488215488216

















 2216
2216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









