






Postgres SQL 实现的MVCC的机制不同于 oracle,mysql innodb 的 undo机制。表上所用的更新和删除等操作的行为,都不会实际的删除或修改,而是标记为死元祖(dead rows or dead tuples),也因此,在大表进行长事务增删改的时候,表的磁盘使用空间会逐渐变大,并且,表的读写性能会随着表膨胀的程度加深而逐渐下降。
那么表和索引的膨胀会造成两个后果,第一是磁盘空间的占用,比如,某个几百G的大表delete删除后,并不会释放磁盘空间,并且在删除的过程中还会引发wal日志的膨胀,而数据库服务器的磁盘空间并不是无限的,第二个就是会使得表的查询和写入性能下降,也就是查询速度降低或者插入/更新速度明显下降。
因此,我们在数据库的使用过程中,应该避免表膨胀,至少是将表膨胀控制在一个合理的,可接受的范围内,完全的避免表膨胀是确定无疑的不可能。
postgresql数据库对于表膨胀这个问题是有几种处理方式
第一,是在postgresql的主配置文件内定义autovacuum,也就是让postgresql数据库自己决定何时治理表膨胀。
第二,手动vacuum 治理表膨胀。
第三,CLUSTER命令治理表膨胀。
第四,利用外部插件,例如pg_repack、pgcompacttable、pg_sequence治理表膨胀。
第五,recreate table or reindex : 相当于重建表和索引。
对于大表来说,根据表的数据规模大小,很多时候vacuum或者CLUSTER的时候都是几个小时甚至十几个小时,而在此期间表被锁住是无法接受的,读写都有问题,锁表会造成业务的中断。
一、 pg_repack部署及使用
pg_repack的处理方式是创建一张新表,再将历史数据从原表中拷贝一份到新表。在拷贝过程中为了避免表被锁定,会创建了一个额外的日志表来记录原表的改动,并添加了一个涉及INSERT、UPDATE、DELETE操作的触发器将变更记录同步到日志表。当原始表中的数据全部导入到新表中,索引重建完毕以及日志表的改动全部完成后,pg_repack会用新表替换旧表,并将原旧表Drop掉。此工具过程简单且靠谱,但需要额外的磁盘空间来报错临时创建的中间表。
1.1 安装pg_repack
[postgres@jdcloud ~]$ unzip pg_repack-1.5.1.zip
[postgres@jdcloud ~]$ cd /postgresql/soft/pg_repack-1.5.1
[postgres@jdcloud pg_repack-1.5.1]$ make
[postgres@jdcloud pg_repack-1.5.1]$ make install
1.2 准备环境
postgres=# create database mydb;
CREATE DATABASE
postgres=# \c mydb
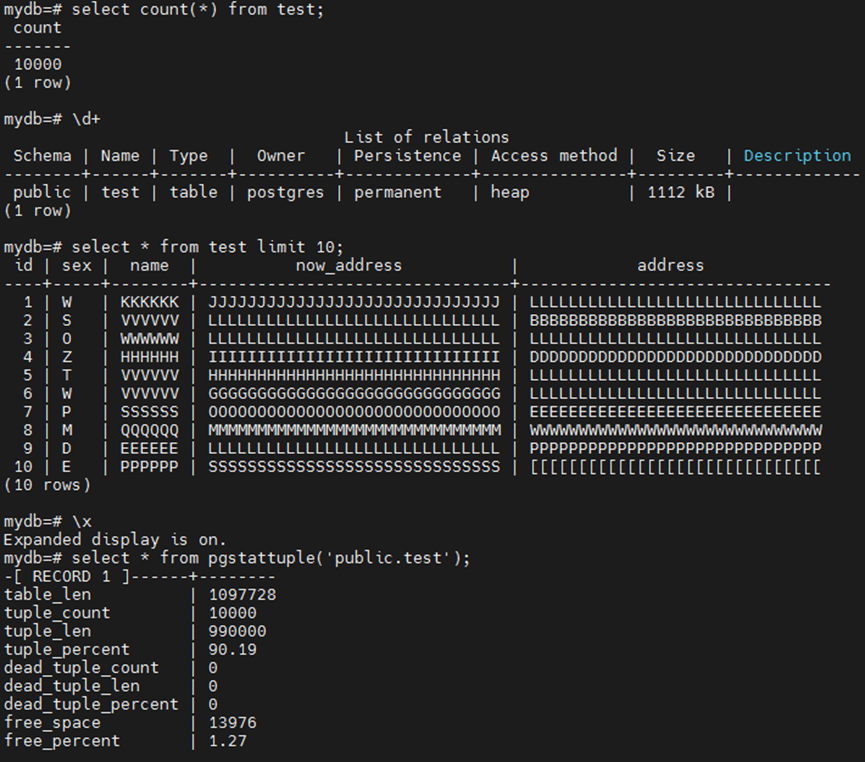
mydb=# create extension pgstattuple ;
CREATE EXTENSION
mydb=# create extension pg_repack;
CREATE EXTENSION
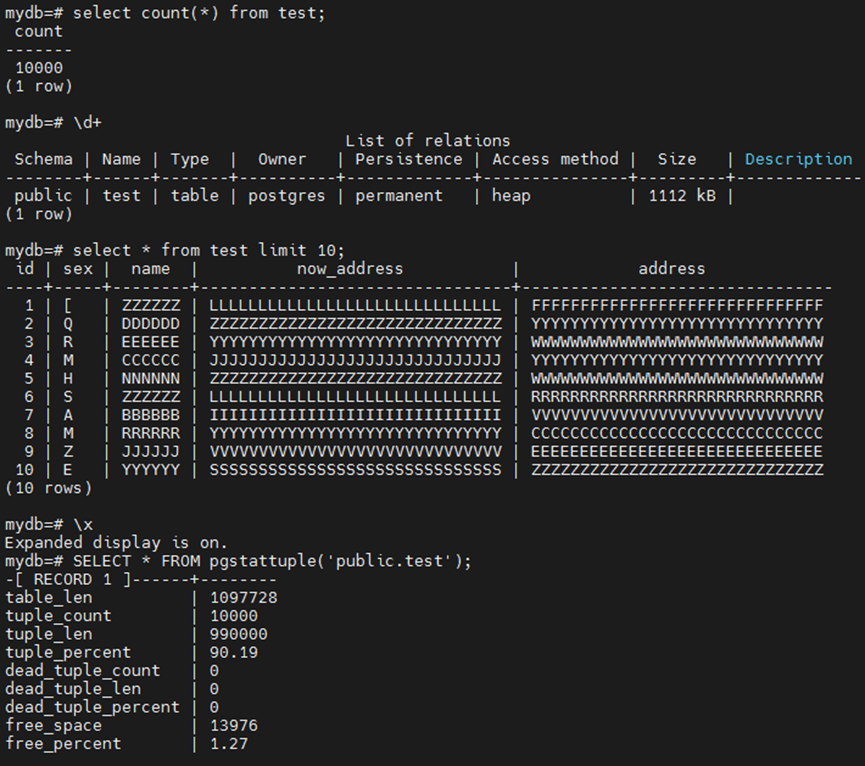
mydb=# create table test (id int,sex varchar(2),name varchar(8),now_address text,address text);
CREATE TABLE
mydb=# insert into test values(generate_series(1,10000),repeat( chr(int4(random()*26)+65),1),repeat( chr(int4(random()*26)+65),6),repeat( chr(int4(random()*26)+65),30),repeat( chr(int4(random()*26)+65),30));
INSERT 0 10000
mydb=# alter table test add primary key (id);
ALTER TABLE
mydb=# create index on test(name,now_address,address);
CREATE INDEX
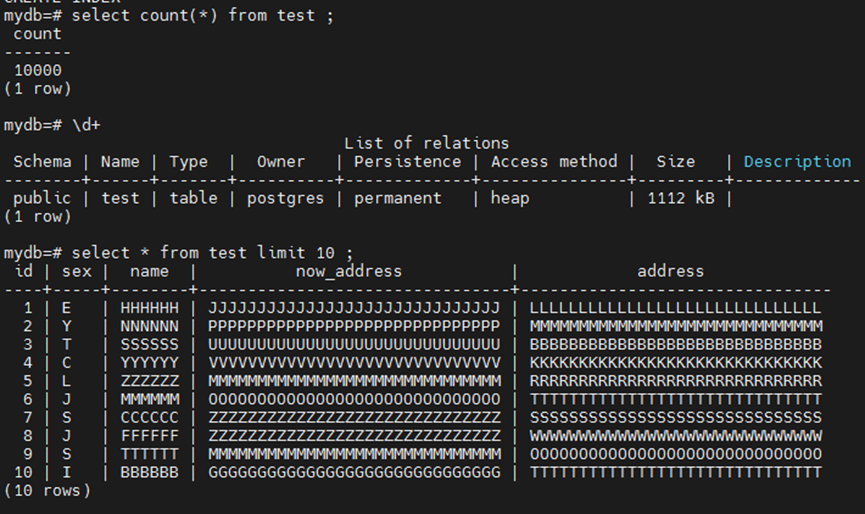
1.3 模拟修改数据
#!/bin/bash
#version: 1.0
#function: bulk update data
for((i=1;i<=10000;i++));
do
a=`tr -dc A-Z[ < /dev/urandom | head -c1`
psql -Upostgres -h 127.0.0.1 -d mydb -c "update test set name=repeat( chr(int4(random()*26)+65),6),now_address=repeat( chr(int4(random()*26)+65),30),address=repeat( chr(int4(random()*26)+65),30) where sex='$a';" >>/dev/null
if [ $? == 0 ]
then
echo "$a is ok" >>update.log
else
echo "$a is close" >>update.err.log
exit 1;
fi
done
1.4 膨胀再现
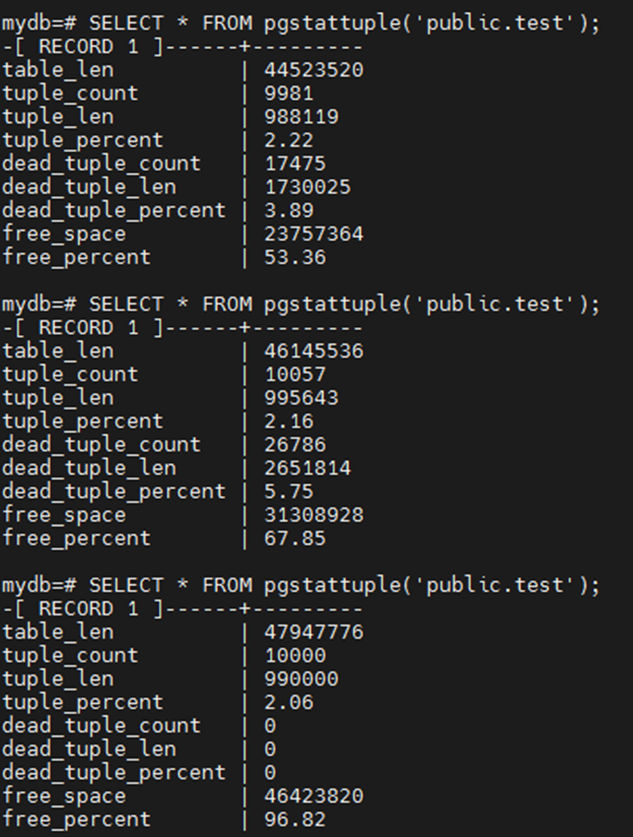
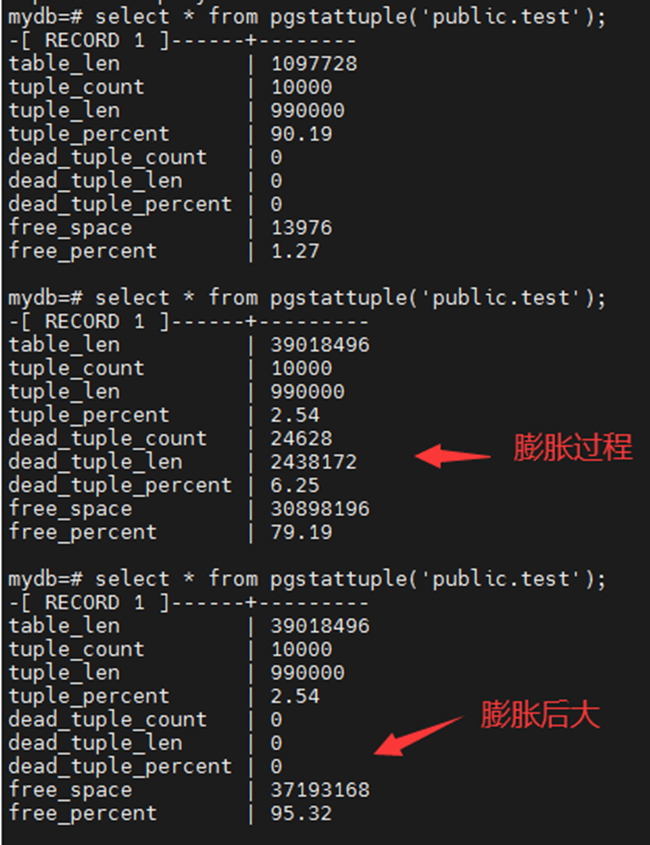
由于我们表的基数是10000,autovacuum_vacuum_threshold是50 , autovacuum_vacuum_scale_factor 是 0.2,所以触发 auto_vacuumn 的阀值是 50 + 10000 * 0.2 = 2050。
10000条数据的更新,达到阀值,所以触发 auto vacuum。
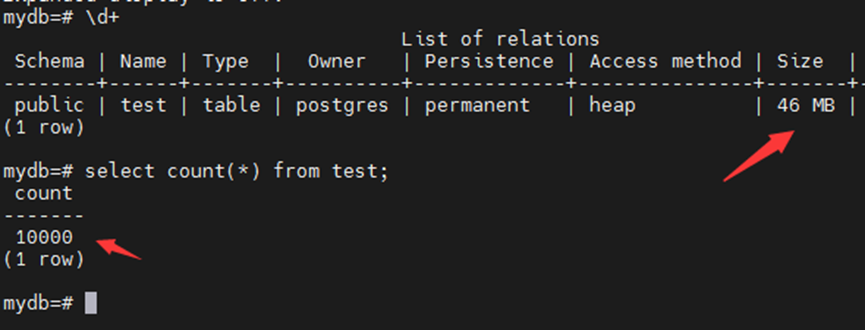
表数量没变,但是大小膨胀了几十倍。
1.5 pg_repack使用
[postgres@jdcloud pg_repack-1.5.1]$ pg_repack -h 127.0.0.1 -p 5432 -U postgres -W -d mydb -t public.test -j 2 -k -D
Password:
NOTICE: Setting up workers.conns
INFO: repacking table "public.test"
LOG: Initial worker 0 to build index: CREATE INDEX index_16432 ON repack.table_16426 USING btree (name, now_address, address)
LOG: Initial worker 1 to build index: CREATE UNIQUE INDEX index_16481 ON repack.table_16426 USING btree (id)
LOG: Command finished in worker 1: CREATE UNIQUE INDEX index_16481 ON repack.table_16426 USING btree (id)
LOG: Command finished in worker 0: CREATE INDEX index_16432 ON repack.table_16426 USING btree (name, now_address, address)
postgres= SELECT * FROM pgstattuple('public.test');
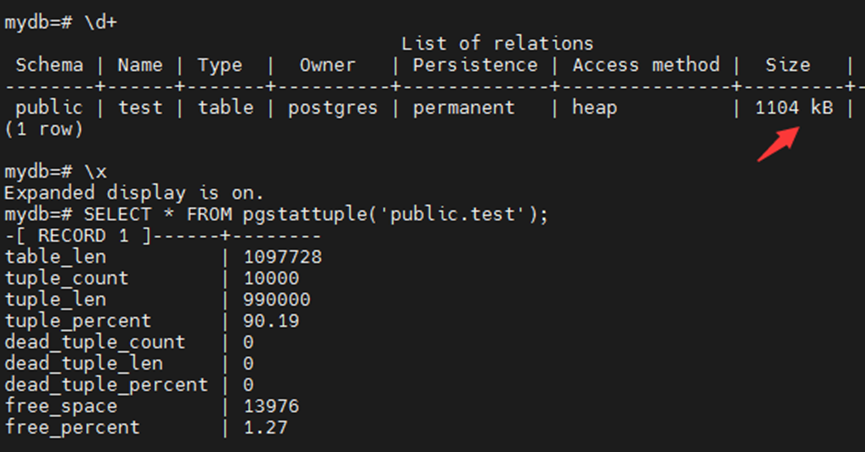
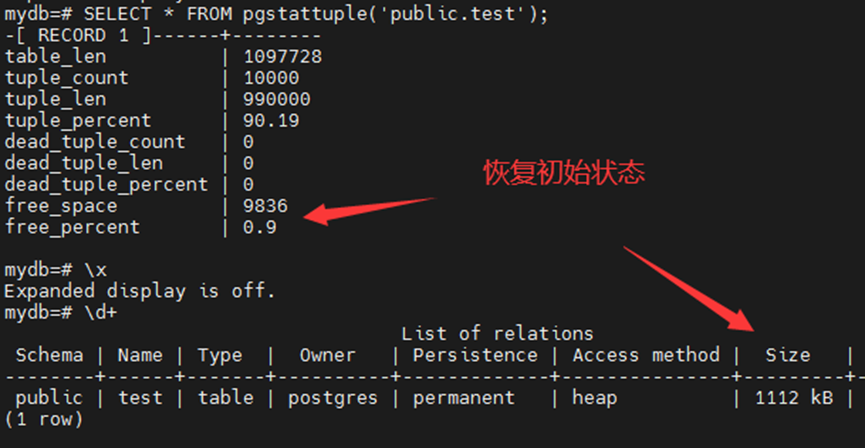
表大小恢复到初始状态1104KB。
二、pgcompacttable部署及使用
pgcompacttable利用了PostgreSQL的一个有趣特性:在执行INSERT和UPDATE操作时,会将所有新版本的行移到表最开始的可用空间。此为pgcompacttable工具的关键,因为如果从末端反向开始更新所有行,最终所有可用空间被这些行填充,并将表尾部的空间全部释放以便让定期vacuum进行truncate。这样一来,pgcompacttable通过批量更新和vacuum强制移动,最终整个表被重新整理,达到压缩的效果。此工具对磁盘空间要求低,且性能影响可控。
pgcompacttable可以对database级别、schema级别、table级别进行压缩。
2.1 安装pgcompacttable
--依赖库安装,pgcompacttable是用Perl编写的,需要Perl DBI库
# yum install perl-Time-HiRes perl-DBI perl-DBD-Pg –y
--解压软件
[postgres@jdcloud soft]$ unzip pgcompacttable-master.zip
[postgres@jdcloud soft]$ cd pgcompacttable-master
[postgres@jdcloud pgcompacttable-master]$ ls
bin LICENSE README.md
[postgres@jdcloud pgcompacttable-master]$ cd bin
[postgres@jdcloud bin]$ ls
pgcompacttable
2.2 准备环境
postgres=# \c mydb
mydb=# create extension pgstattuple ;
CREATE EXTENSION
mydb=# create table test (id int primary key,sex varchar(2),name varchar(8),now_address text,address text);
CREATE TABLE
mydb=# insert into test values(generate_series(1,10000),repeat( chr(int4(random()*26)+65),1),repeat( chr(int4(random()*26)+65),6),repeat( chr(int4(random()*26)+65),30),repeat( chr(int4(random()*26)+65),30));
INSERT 0 10000
mydb=# create index on test(name,now_address,address);
CREATE INDEX
2.3 模拟修改数据
#!/bin/bash
#version: 1.0
#function: bulk update data
for((i=1;i<=10000;i++));
do
a=`tr -dc A-Z[ < /dev/urandom | head -c1`
psql -Upostgres -h 127.0.0.1 -d mydb -c "update test set name=repeat( chr(int4(random()*26)+65),6),now_address=repeat( chr(int4(random()*26)+65),30),address=repeat( chr(int4(random()*26)+65),30) where sex='$a';" >>/dev/null
if [ $? == 0 ]
then
echo "$a is ok" >>update.log
else
echo "$a is close" >>update.err.log
exit 1;
fi
done
2.4 膨胀再现
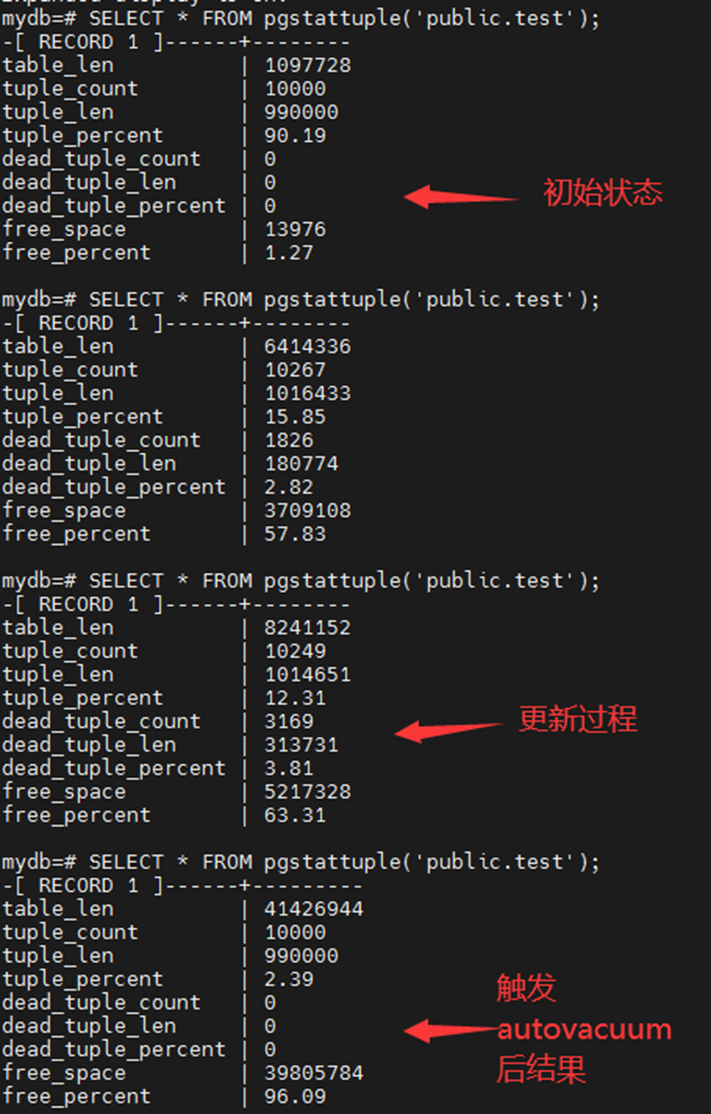
由于我们表的基数是10000,autovacuum_vacuum_threshold是50 , autovacuum_vacuum_scale_factor 是 0.2,所以触发 auto_vacuumn 的阀值是 50 + 10000 * 0.2 = 2050。
10000条数据的更新,达到阀值,所以触发 auto vacuum。
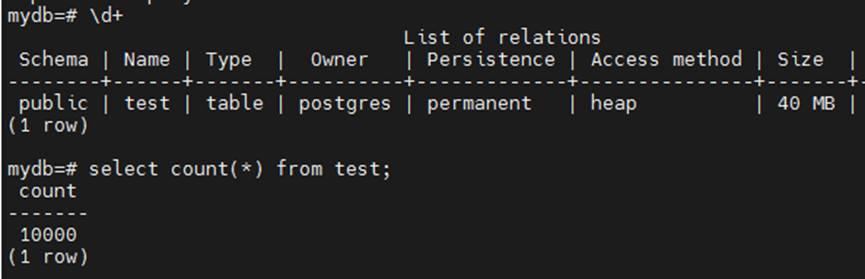
表数量没变,但是大小膨胀了几十倍。
2.5 pgcompacttable使用
[postgres@jdcloud bin]$ ./pgcompacttable -h 127.0.0.1 -U postgres -d mydb -t test
[Fri Mar 28 12:43:32 2025] (mydb) Connecting to database
[Fri Mar 28 12:43:32 2025] (mydb) Postgres backend pid: 7128
[Fri Mar 28 12:43:32 2025] (mydb) Handling tables. Attempt 1
[Fri Mar 28 12:43:32 2025] (mydb:public.test) Statistics: 5057 pages (6306 pages including toasts and indexes), it is expected that ~96.090% (4859 pages) can be compacted with the estimated space saving being 37.962MB.
[Fri Mar 28 12:43:55 2025] (mydb:public.test) Reindex: public.test_pkey, initial size 57 pages(456.000KB), has been reduced by 47% (216.000KB), duration 0 seconds.
[Fri Mar 28 12:43:56 2025] (mydb:public.test) Reindex: public.test_name_now_address_address_idx, initial size 1186 pages(9.266MB), has been reduced by 91% (8.500MB), duration 0 seconds.
[Fri Mar 28 12:43:56 2025] (mydb:public.test) Processing results: 134 pages left (267 pages including toasts and indexes), size reduced by 38.461MB (47.180MB including toasts and indexes) in total.
[Fri Mar 28 12:43:56 2025] (mydb) Processing complete.
[Fri Mar 28 12:43:56 2025] (mydb) Processing results: size reduced by 38.461MB (47.180MB including toasts and indexes) in total.
[Fri Mar 28 12:43:56 2025] (mydb) Disconnecting from database
[Fri Mar 28 12:43:56 2025] Processing complete: 1 retries to process has been done
[Fri Mar 28 12:43:56 2025] Processing results: size reduced by 38.461MB (47.180MB including toasts and indexes) in total, 38.461MB (47.180MB) mydb.
三、pg_squeeze部署及使用
pg_squeeze是一个扩展,它从表中删除未使用的空间,并且可以选择根据特定索引对元组进行排序,一般当一个表膨胀时一般使用vacuum full或者cluster进行表重建,在这一过程中会加排他锁,导致该表无法进行读写,只有等整个过程完成后才可以进行正常使用。
pg_squeeze就是来解决这个问题的,它只会在最后切换filenode的过程中加锁,其他过程中是不影响读写的。
pg_squeeze的优点
相比pg_repack或pg_reorg,pg_squeeze不需要建触发器,所以在重组时对原表的DML几乎没有性能影响。安装
3.1 安装pg_sequence
解压文件,安装即可。
[postgres@jdcloud soft]$ unzip pg_squeeze-master.zip
[postgres@jdcloud soft]$ cd pg_squeeze-master
[postgres@jdcloud pg_squeeze-master]$ make
[postgres@jdcloud pg_squeeze-master]$ make install
修改postgresql.conf 参数文件并重启生效
#将pg_squeeze添加到现有库中。
shared_preload_libraries = 'pg_squeeze'
修改wal_level为logical
3.2 准备环境
mydb=# create extension pg_squeeze;
CREATE EXTENSION
mydb=# create table test (id int primary key,sex varchar(2),name varchar(8),now_address text,address text);
CREATE TABLE
mydb=# insert into test values(generate_series(1,10000),repeat( chr(int4(random()*26)+65),1),repeat( chr(int4(random()*26)+65),6),repeat( chr(int4(random()*26)+65),30),repeat( chr(int4(random()*26)+65),30));
INSERT 0 10000
mydb=# create index on test(name,now_address,address);
CREATE INDEX
3.3 模拟修改数据
#!/bin/bash
#version: 1.0
#function: bulk update data
for((i=1;i<=10000;i++));
do
a=`tr -dc A-Z[ < /dev/urandom | head -c1`
psql -Upostgres -h 127.0.0.1 -d mydb -c "update test set name=repeat( chr(int4(random()*26)+65),6),now_address=repeat( chr(int4(random()*26)+65),30),address=repeat( chr(int4(random()*26)+65),30) where sex='$a';" >>/dev/null
if [ $? == 0 ]
then
echo "$a is ok" >>update.log
else
echo "$a is close" >>update.err.log
exit 1;
fi
done
3.4 膨胀再现
由于我们表的基数是10000,autovacuum_vacuum_threshold是50 , autovacuum_vacuum_scale_factor 是 0.2,所以触发 auto_vacuumn 的阀值是 50 + 10000 * 0.2 = 2050。
10000条数据的更新,达到阀值,所以触发 auto vacuum。
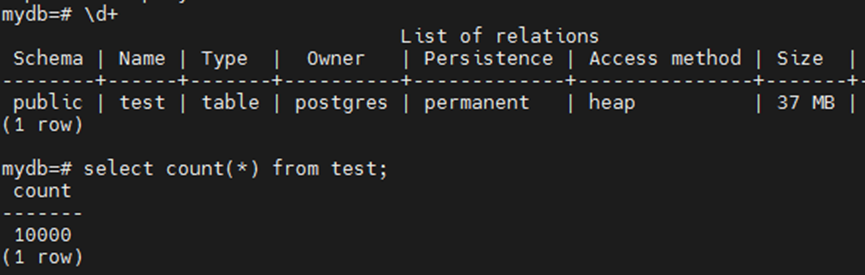
表数量没变,但是大小膨胀了几十倍。
3.5 pg_squeeze使用
mydb=# SELECT squeeze.squeeze_table('public', 'test', null, null, null);
squeeze_table
---------------
(1 row)


















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











