






 本文介绍了一个自动抓取微博数据的脚本开发过程,从搜索目标人物到获取微博评论,通过解析网页源码和API调用,实现了自动化数据抓取。
本文介绍了一个自动抓取微博数据的脚本开发过程,从搜索目标人物到获取微博评论,通过解析网页源码和API调用,实现了自动化数据抓取。
今天呢,继续撸微博,希望新浪的大神们不在啊啊啊。
缘起
昨天写了一篇文章,主要是有感于文章马伊琍的婚姻,才爬了下他们微博下的评论,结果有位老哥说

这还了得,我这小暴脾气不能忍啊,果断准备再次出手,拿下姐姐的微博评论。但是当我把瓜子都买好的时候。。。
正当我准备再次 F12 查 ID,造 URL 的时候,作为一名非专业码农的惰性就体现出来了,每次都这么搞,是不是有点太繁琐了。于是,作为各类轮子的深度依赖者,这次我准备自己造个轮子。
设想
-
最起码是一个自动抓取的脚本,嗯,这是底线!
-
有个入口输入要爬取的人物(当前设定为大 V,和搜索到的第一个人)
-
之后,就交给程序,坐等数据
思路
于是乎,在上述设想的指引下,我开始了轮子之旅
抓取入口
首先想到的就是利用微博的搜索功能,然后再看看能得到些啥
这个搜索 URL:
https://s.weibo.com/user?q=林志玲
可以直接调,爽的飞起!
具体分析过程就不详细写了,从中我们可以拿到用户的 UID,很重要。
import requests
from bs4 import BeautifulSoup
url = 'https://s.weibo.com/user?q=林志玲'
res = requests.get(url).text
content = BeautifulSoup(res, 'html.parser')
user = content.find('div', attrs={'class': 'card card-user-b s-pg16 s-brt1'})
user_info = user.find('div', attrs={'class': 'info'}).find('div')
href_list = user_info.find_all('a')
if len(href_list) == 3:
title = href_list[1].get('title')
if title == '微博个人认证':
uid = href_list[2].get('uid')
print(uid)
else:
print("this is not a big VIP")
因为这种搜索,可能会搜索出很多结果,张三、李四啥的都出来了,我们只关心大 V ,对于非大 V,就取第一个喽。
两次调用
下面要隆重解释一个 URL
https://m.weibo.cn/api/container/getIndex
这个地址可以在微博的 m 站上找到,有时候,爬 m 站的地址要更容易些哦。
这个地址,我们主要有两个作用,使用不同的参数,调用两次
调用一
首先我们这样调用该 URL
https://m.weibo.cn/api/container/getIndex?type=uid&value=1312412824
value 为上面拿到的用户 UID
看 Postman

能得到该用户的用户信息,这里面有一个很重要的信息,containerid,保存下来,一会用。
调用二
接着我们再这样调用该 URL
https://m.weibo.cn/api/container/getIndex?containerid=1076031312412824&page=0
containerid 就是上一步得到的 ID
继续看 Postman

得到的就是 blog 信息了,返回的是 json 数据,很棒。
最后,我们可以再结合前面文章的获取评论的方法,那么该用户下的博客和评论内容就都到手喽。
开搞
此处先省去菜鸟被虐的一万点伤害值

其中的千辛万苦,谁能知之。
一、配置文件
先来个配置文件,毕竟大型项目都是这么玩的,我这也是大型项目

config.py 文件
sleep_time = 5 # 延迟时间,建议配置5-10s
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36",
"Cookie": "your cookie"
}
day = 60 # 最久抓取的微博时间,60即为只抓取两个月前到现在的微博
二、工具箱
抽象出一些公共的函数,不能把代码写的太丑了
tools.py 文件
def checkTime(inputtime, day):
try:
intime = datetime.datetime.strptime("2019-" + inputtime, '%Y-%m-%d')
except:
return "时间转换失败"
now = datetime.datetime.now()
n_days = now - intime
days = n_days.days
if days < day:
return True
else:
return False
这个是用来检查时间间隔的,后面在抓取微博时,如果时间太久远的,就不抓了。
还有一个函数是用来解析 blog 数据的,因为是 json 数据,解析起来很简单,就不多说了
def get_blog_info(cards, i, name, page):
...
三、主逻辑
定义一个 WeiBo 类
class WeiBo(object):
def __init__(self, name, headers):
self.name = name
self.headers = headers
后面所有的操作,都是基于该类来的
类中的方法
def get_uid(self): # 获取用户的 UID
...
def get_userinfo(self, uid): # 获取用户信息,包括 containerid
...
def get_blog_by_page(self, containerid, page, name): # 获取 page 页的微博信息
...
def get_blog_by_text(self, containerid, blog_text, name): # 一个简单的搜索功能,根据输入的内容查找对应的微博
...
def get_comment(self, mblog_id, page): # 与上个函数配合使用,用于获取某个微博的评论
...
def download_comment(self, comment): # 下载评论
...
def download_pic(self): # 灵感来源于“胖虎”哥的“营养快线”文章,暂未实现
pass
四、运行函数
这里个人感觉逻辑写的还是有点臃肿,没办法,菜!各位大神如果路过,还请不要嫌弃。
主要就是配合 input 函数,来获取用户的输入,然后根据不同情况调取 WeiBo 类里的方法。
至此,一个勉强可用的轮子基本完成了,可把我累(牛)坏(逼)了(坏)啦(了)

成果展示
扯了这么多,终于到了见成果的时候了,先来看个动图
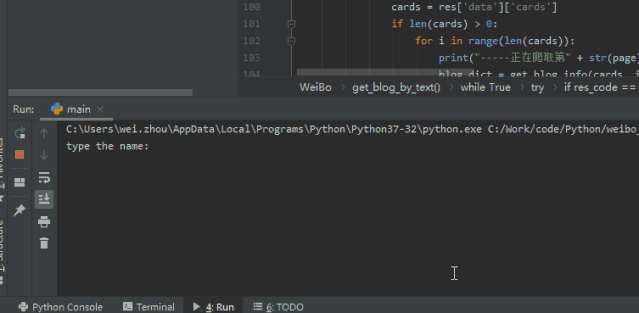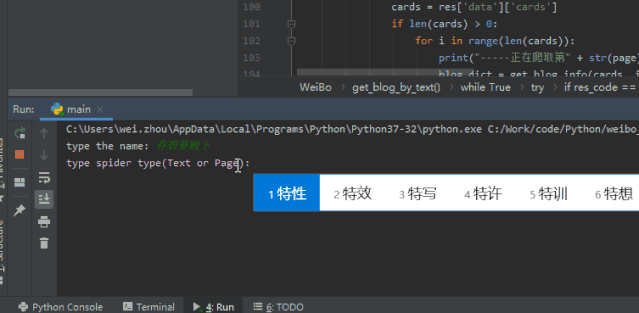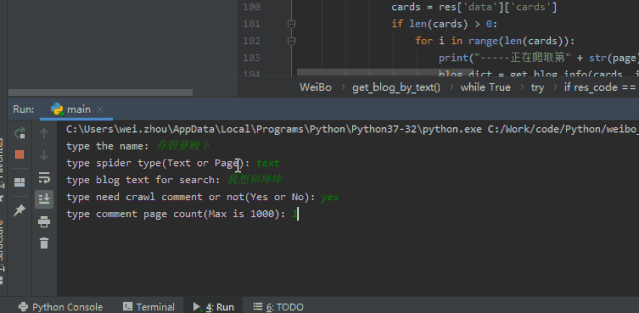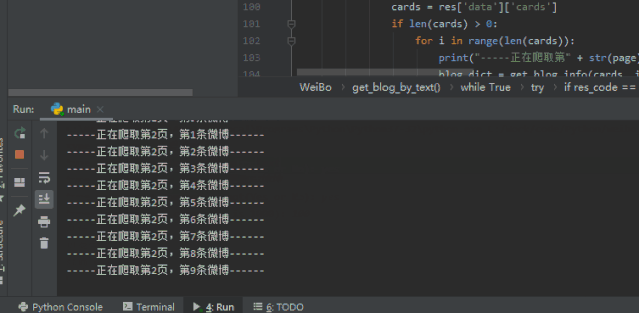
网络上爆炸的“乔碧萝殿下”,成为了我检(祭)验(刀)的第一人

那么最后还是要扣题呀,把那段缘结束掉。看看志玲姐姐微博下的评论,到底是咋样
其实拿到评论数据之后,简单浏览了下,确实有很多难以启齿的评论,但是呢,这个事情我觉得还是没有必要太上纲上线了,哈哈哈,总之祝福吧

(此处请自动过滤掉一些些不和谐因素)
下面,
前方,
高能,

前方是大型认亲现场,怕引起不适的请跳过。

持续发酵的事件背后,产生了各种赢家,斗鱼平台、主播晴子,当然还有 CXK 喽,不能说了

最后的最后,献上代码:
https://github.com/zhouwei713/weibo_spider
完!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











