







1、概述
Python是一门广泛使用的解释型、高级和通用的编程语言,由荷兰数学和计算机科学研究学会的Guido van Rossum创造,第一版发布于1991年,版本号为0.9.0。Python的创造者在设计Python时,受到了ABC语言和C++等语言的影响,并试图克服它们的某些限制。他希望创建一种既能够用于教学,又能够用于实际开发的编程语言,既能够像C++那样强大和灵活,又能够像ABC那样易于学习和使用。因此,Python的设计哲学强调代码的可读性和简洁性,使其成为一种易于学习、易于阅读和易于维护的编程语言。
Python语言经历过三次大版本的迭代:
- Python 1.0(1994年):这是Python的第一个正式版本,标志着Python语言从原型阶段进入了实际应用阶段。这个版本主要关注语言的稳定性和基本功能的完善。
- Python 2.0(2000年):Python 2.0是Python语言的第二个重要版本,引入了许多新特性和改进,如内存管理优化、循环和列表推导式的改进等。这个版本也是Python语言开始广泛应用的起点。
- Python 3.0(2008年):Python 3.0是Python语言的一个重要里程碑,它引入了许多重要的语言改进和新特性,如使用Unicode作为默认字符串类型、改进了整数除法运算等。然而,由于Python 2和Python 3之间存在较大的不兼容性,这个版本在发布初期引起了一些争议和困惑。
目前Python 2.x和Python 3.x都被广泛的使用中,Python 3.x已经逐渐成为了主流,新手入门建议直接从Python 3.x开始。
Python开发语言的应用领域非常广泛,可以大致分为三个领域:
- Web开发:Python具有强大的Web开发能力,可以用于开发Web应用、网络爬虫、网络服务器等。著名的Web框架如Django和Flask都是基于Python开发的。对于一些中小型企业,没有高并发、高效率需求的企业,选择Python作为开发语言是完全可行的。因为Python语言对程序员的要求比较低,且开发效率还高。
- 数据科学与人工智能:Python在数据科学和人工智能领域非常受欢迎。它提供了丰富的数据处理、分析和可视化工具,如NumPy、Pandas和Matplotlib。Python也是许多机器学习和深度学习框架的首选语言,如TensorFlow和PyTorch。这个领域的使用者主要是科研院所和高科技公司,Python语言在这里具有极大的优势,甚至超越了老牌专业软件Matlab,除此以外其他语言完全无法与Python竞争。
- 服务器开发:Python语言是可以用来开发服务器软件的,但这并不是Python语言的优势领域,因为Python语言在高并发、高性能等方面与C++、Go、Java等语言还是有一定的差距。不过即使不能成为首选服务器开发语言,作为第二梯队服务器开发语言还是完全没问题的。例如:Python游戏开发,Pygame是一个基于Python的游戏开发库,提供了丰富的游戏开发功能和工具。
随着人工智能时代的到来,一些开发语言都陆续提供了支持,但都没法与Python语言媲美。Python在人工智能领域具有广泛的应用,主要原因是其语法简洁、易读性强,拥有丰富的第三方库和工具,以及庞大的用户社区。这些特点使得Python成为构建和训练机器学习模型、处理和分析数据、进行自然语言处理等任务的理想选择。根据多个数据来源和调查报告,Python在人工智能领域的使用率非常高,是数据科学家和人工智能从业者使用最多的语言。
本文主要介绍一些人工智能领域Python常用的开发库,及个人使用的经验之谈,与广大开发者共勉。
2、常用python库
NumPy(必选)
这是Python的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。NumPy底层使用C语言编写,数组中直接存储对象,而不是存储对象指针,因此其运算效率远高于纯Python代码。
以下是 NumPy 的一些主要特点和功能:
- 多维数组(ndarray):NumPy 的核心数据结构是多维数组,可以表示一维、二维或更高维度的数据。数组的操作速度快,且提供了丰富的索引和切片操作,使得数据处理更加灵活。
- 数学函数和运算:NumPy 提供了一系列数学函数,如三角函数、指数函数、对数函数等,以及数组的运算,如加法、减法、乘法、除法等。这些函数可以对数组进行批量处理,大大提高了计算效率。
- 矩阵和向量操作:NumPy 支持矩阵和向量的运算,例如矩阵乘法、转置、求逆等。这对于线性代数和机器学习中的许多算法非常有用。
- 数据整形和广播:NumPy 提供了方便的数据整形功能,可以将不同形状的数组进行组合和运算。
- 高级索引和切片:通过使用高级索引和切片,你可以方便地选择和操作数组的特定元素或子数组,提供了更大的灵活性。
- 傅里叶变换和其他信号处理功能:NumPy 包含了一些用于信号处理和频域分析的函数,如傅里叶变换、卷积等。
人工智能运算中经常用到多维数组、矩阵运算、数组重组等操作,因此我们可以认为NumPy是人工智能最基础的一个工具库。
例1:NumPy平滑处理数组元素
下面这个例子是对一个一维数组进行平方处理,我们对比一下NumPy库处理的效果和Python原生数组处理的效果。
NumPy数据处理
import numpy as np
# 创建一个NumPy数组
numpy_array = np.array([1, 2, 3, 4, 5])
# 使用NumPy函数对数组进行操作
squared = np.square(numpy_array)
print("NumPy Array Squared:", squared)Python原生数据处理
# 创建一个Python原生列表
python_list = [1, 2, 3, 4, 5]
# 使用Python循环对列表进行操作
squared_list = []
for num in python_list:
squared_list.append(num ** 2)
print("Python List Squared:", squared_list)从这个例子我们可以看出NumPy库不但可以定义数组,而且可以对数据平滑的进行运算。而Python原生处理的过程中,数组的定义和处理过程是割裂的,需要定义中间变量才能完成。
例2:用NumPy库做矩阵运算
下面这个例子我们可以用NumPy库方便的进行矩阵乘法、矩阵转置、矩阵求逆三种运算。这个操作用Python原生数组实现是非常困难的。
import numpy as np
# 创建两个二维矩阵
matrix_a = np.array([[1, 2], [3, 4]])
matrix_b = np.array([[5, 6], [7, 8]])
# 矩阵乘法
result_multiply = np.dot(matrix_a, matrix_b)
print("Matrix Multiplication:")
print(result_multiply)
# 矩阵转置
result_transpose_a = matrix_a.T
result_transpose_b = np.transpose(matrix_b)
print("\nMatrix A Transpose:")
print(result_transpose_a)
print("\nMatrix B Transpose:")
print(result_transpose_b)
# 矩阵求逆(需要矩阵是可逆的)
result_inverse_a = np.linalg.inv(matrix_a)
print("\nMatrix A Inverse:")
print(result_inverse_a) 例3:用NumPy库对二维数组进行重组
下面这个例子中我们定义了一个一维数组,然后将其重组为3*3数组。这样的操作在人工智能运算中是常有的事,我们用NumPy库可以很方便的完成这样的操作。
import numpy as np
# 创建一个一维数组
original_array = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
# 将一维数组重组为二维数组(3x3矩阵)
reshaped_array = original_array.reshape(3, 3)
print("Reshaped Array (3x3 matrix):")
print(reshaped_array)
# 将二维数组重组为一维数组,并指定新数组的顺序(C顺序或F顺序)
# C顺序是按行读取元素,F顺序是按列读取元素
c_order_flattened = reshaped_array.flatten('C')
f_order_flattened = reshaped_array.flatten('F')
print("\nFlattened Array (C Order):")
print(c_order_flattened)
print("\nFlattened Array (F Order):")
print(f_order_flattened)
# 使用transpose()函数交换数组的轴
transposed_array = reshaped_array.transpose()
print("\nTransposed Array:")
print(transposed_array) Pandas(必选)
Pandas库是一个基于NumPy的开源Python库,它提供了高性能的数据结构(如Series和DataFrame)和数据分析工具,被广泛用于数据清洗、处理、分析和可视化等方面。Pandas最初被作为金融数据分析工具而开发出来,因此它对时间序列分析提供了很好的支持。Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)的组合。
Pandas和NumPy在功能上有一些重叠,特别是在数组处理和矩阵处理方面。然而,尽管它们有共同的目标,但这两个库在设计和使用上有一些重要的区别,使得它们在数据科学和分析中各有优势。NumPy是用于处理数组和矩阵运算的基础包,主要优势在于其高效的数值计算能力和对大型数组和矩阵的处理能力。Pandas则是一个提供高性能、易于使用的数据结构和数据分析工具的库,提供了大量的函数和方法,用于数据导入、清洗、转换、分析和可视化。
以下是 Pandas 库的一些主要特点和功能:
- 数据结构:
- DataFrame:类似于电子表格的二维数据结构,包含了多行多列的数据,可以方便地对数据进行操作和分析。
- Series:一维标记数组,常用于表示一列数据。
- 数据读取和写入:支持多种数据格式的读取和写入,如 CSV、Excel、SQL 数据库等。提供了方便的函数和方法来加载、保存和处理数据。
- 数据选择和过滤:使用索引和标签来选择数据的特定行和列。支持基于条件的过滤和筛选操作。
- 数据清洗和预处理:提供了对缺失值、重复值的处理方法。可以进行数据类型转换、填充缺失值等操作。
- 数据聚合和分组:能够对数据进行聚合计算,如求和、平均值、计数等。支持根据特定列进行分组,并对每个组进行聚合操作。
- 数据连接和合并:可以将多个数据结构进行连接或合并,如按列或行进行合并。
- 时间序列处理:提供了专门的时间序列功能,如日期和时间的处理、时间间隔的计算等。
- 数据可视化:与其他可视化库(如 Matplotlib、Seaborn)集成,方便进行数据可视化。
- 数据分析和统计:提供了各种统计函数和指标的计算,如描述性统计、相关性分析等。
例1:用Pandas读取csv文件,并进行数据过滤
假设我们有一个名为data.csv的CSV文件,内容如下:
Name,Age,City
Alice,25,New York
Bob,30,Los Angeles
Charlie,35,Chicago
David,40,San Francisco下面我们用Pandas库来读取、处理数据。其实我们可以直接在代码中构造数据,但是为了演示文件读取功能,所以多了一个步骤。
import pandas as pd
# 读取CSV文件到DataFrame
df = pd.read_csv('data.csv')
# 查看前几行数据
print(df.head())
# 数据清洗:将'Age'列中的字符串转换为整数
df['Age'] = df['Age'].astype(int)
# 数据转换:添加一列'Is_Adult',判断年龄是否大于等于18
df['Is_Adult'] = df['Age'] >= 18
# 数据分析:计算每个城市的成年人数
adult_counts = df.groupby('City')['Is_Adult'].sum()
print(adult_counts)
# 数据分析:找出年龄最大的人
oldest_person = df.loc[df['Age'].idxmax()]
print(oldest_person)
# 数据分析:按年龄从大到小排序
sorted_df = df.sort_values('Age', ascending=False)
print(sorted_df)例2:用Pandas库做数据聚合和分组
这个例子我们构造了一个学生学科成绩的数组,然后用Pandas库聚合数据,最后按不同字段输出分组数据。
import pandas as pd
# 创建一个扩展后的学生成绩DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve', 'Frank', 'Grace', 'Henry'],
'Gender': ['F', 'M', 'M', 'M', 'F', 'M', 'F', 'M'],
'Subject': ['Math', 'Math', 'Math', 'Math', 'Science', 'Science', 'Science', 'Science'],
'Score': [85, 90, 78, 92, 88, 76, 95, 89]
}
df = pd.DataFrame(data)
print("原始数据:")
print(df)
# 按姓名和科目分组,计算每个组的平均分
grouped = df.groupby(['Name', 'Subject'])['Score'].mean()
# 将结果转换为DataFrame以便更好地显示
result = grouped.reset_index()
print("按姓名和科目分组后的平均分:")
print(result)
# 进一步分析:计算每个学生的平均成绩
student_avg_scores = df.groupby('Name')['Score'].mean()
print("\n每个学生的平均成绩:")
print(student_avg_scores)
# 进一步分析:计算每个科目的平均成绩
subject_avg_scores = df.groupby('Subject')['Score'].mean()
print("\n每个科目的平均成绩:")
print(subject_avg_scores)输出结果
按姓名和科目分组后的平均分:
Name Subject Score
0 Alice Math 85.0
1 Bob Math 90.0
2 Charlie Math 78.0
3 David Math 92.0
4 Eve Science 88.0
5 Frank Science 76.0
6 Grace Science 95.0
7 Henry Science 89.0
每个学生的平均成绩:
Name
Alice 85.0
Bob 90.0
Charlie 78.0
David 92.0
Eve 88.0
Frank 76.0
Grace 95.0
Henry 89.0
Name: Score, dtype: float64
每个科目的平均成绩:
Subject
Math 86.25
Science 87.00
Name: Score, dtype: float64例3:用Pandas库做数据可视化
这个例子中,我们构造了一个数据集,然后用Pandas库生成柱状图和折线图,然后用matplotlib库完成画图。
import pandas as pd
import matplotlib.pyplot as plt
# 创建一个简单的数据集
data = {
'Year': [2015, 2016, 2017, 2018, 2019, 2020],
'Sales': [100, 150, 70, 200, 180, 220],
'Profits': [50, 60, 40, 80, 70, 90]
}
# 将数据转换为Pandas DataFrame
df = pd.DataFrame(data)
# 绘制柱状图
df.plot(kind='bar', x='Year', y=['Sales', 'Profits'], legend=True, title='Sales and Profits Over Years')
plt.xlabel('Year')
plt.ylabel('Amount')
plt.show()
# 绘制折线图
df.plot(kind='line', x='Year', y=['Sales', 'Profits'], legend=True, title='Sales and Profits Over Years (Line Chart)')
plt.xlabel('Year')
plt.ylabel('Amount')
plt.show()输出结果
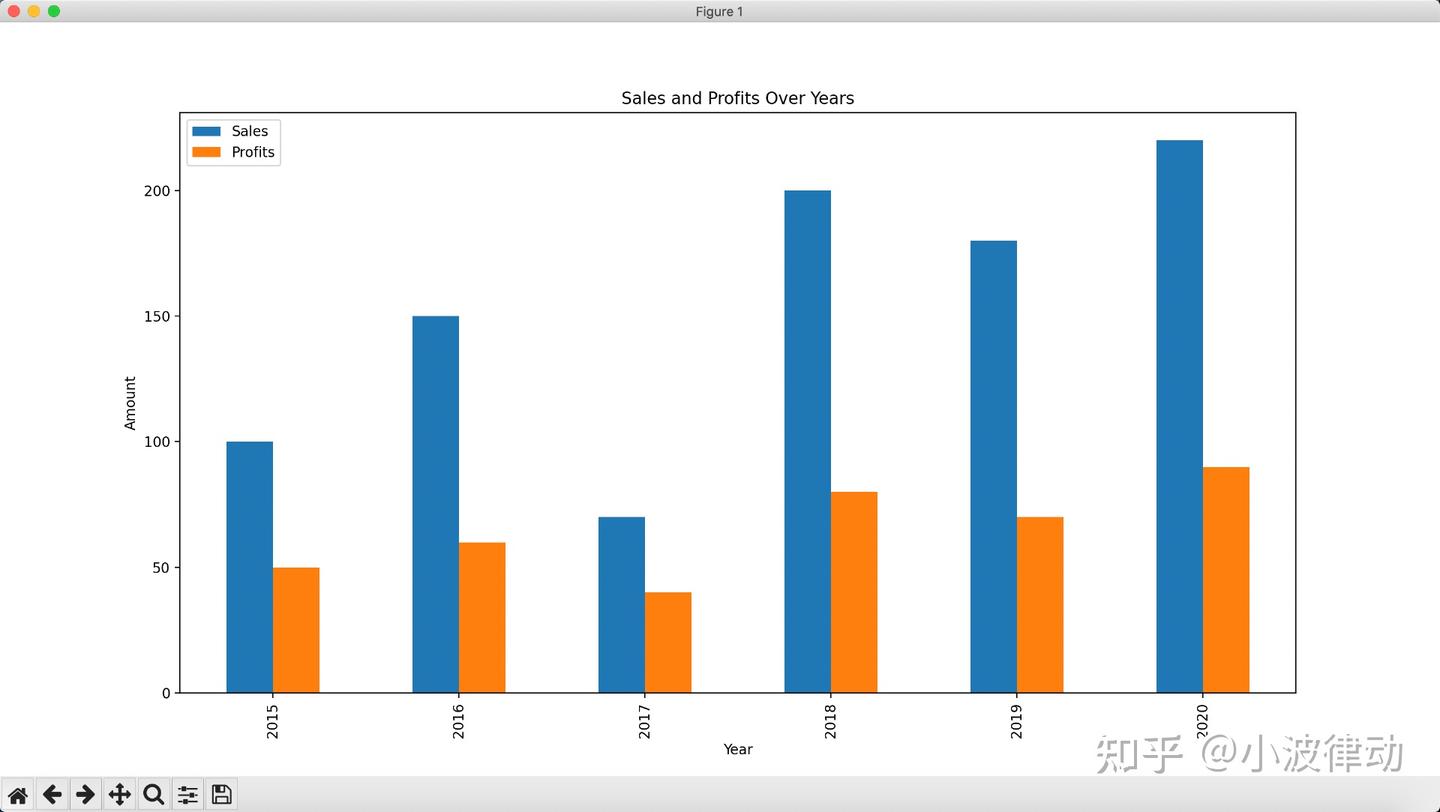
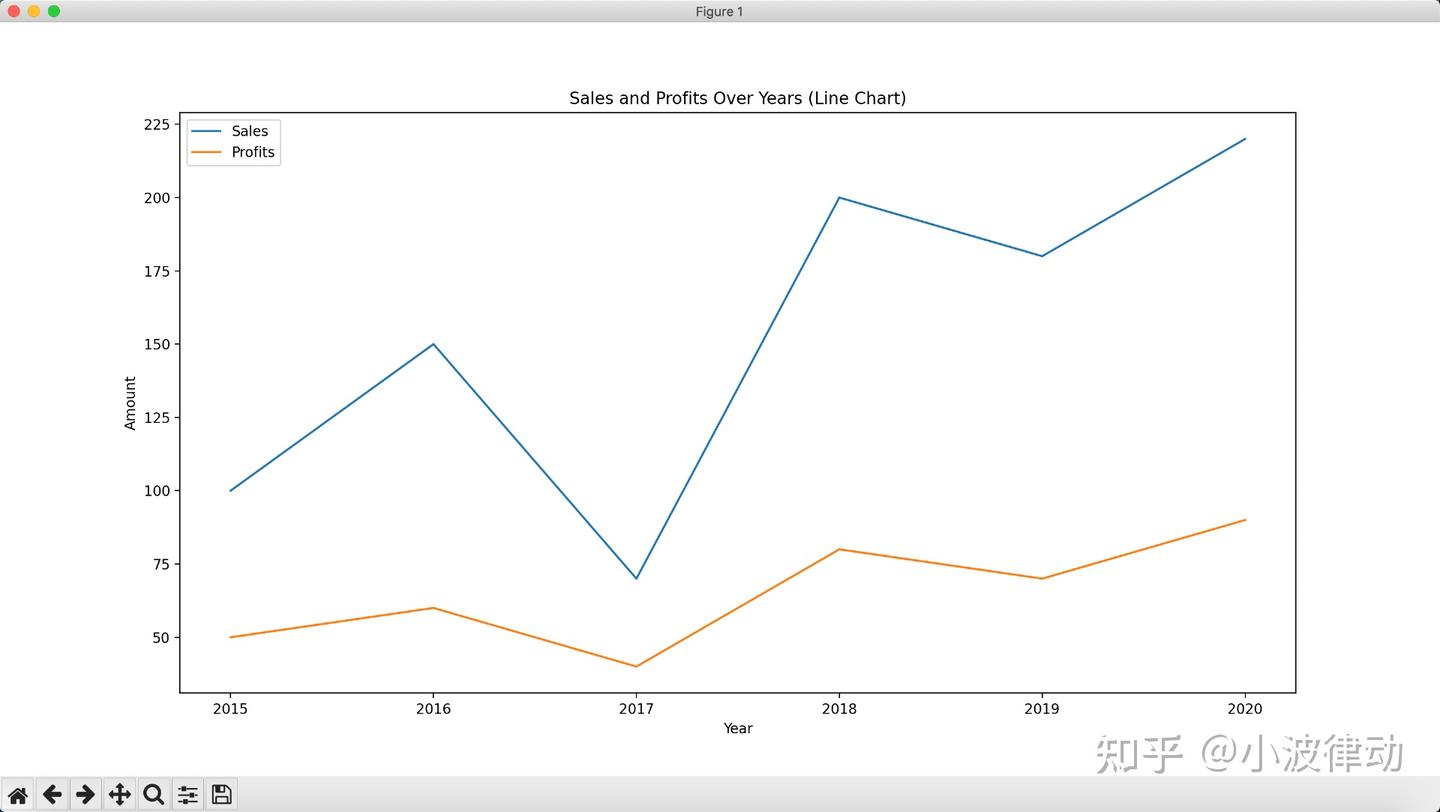
Matplotlib(必选)
Matplotlib 是一个用于创建数据可视化的 Python 库。它提供了广泛的绘图选项,包括线图、散点图、柱状图、饼图、直方图等等,可以用于数据分析、科学计算和统计可视化等领域。
以下是 Matplotlib 的一些主要特点和功能:
- 多样化的绘图类型:Matplotlib 支持多种类型的图形,如二维和三维图形,以及各种图表样式,使得用户可以根据数据特点选择合适的可视化方式。
- 灵活的坐标轴和刻度控制:用户可以自定义坐标轴范围、刻度标签、网格线等,以满足具体的可视化需求。
- 数据标注和图例:Matpltolib 允许用户添加文本标注、图例、标题等元素,以便更好地解释和说明图形。
- 颜色和样式设置:可以通过设置颜色、线条样式、标记等来美化图形,使其更具吸引力和可读性。
- 子图和布局:Matplotlib 支持在同一图形中创建多个子图,并可以灵活地控制子图的布局和排列方式。
- 数据交互:可以通过鼠标点击、悬停等交互方式获取图形上的数据信息,增强数据探索的能力。
- 导出图形:图形可以以多种格式导出,如 PNG、JPEG、SVG 等,方便与其他文档或报告进行集成。
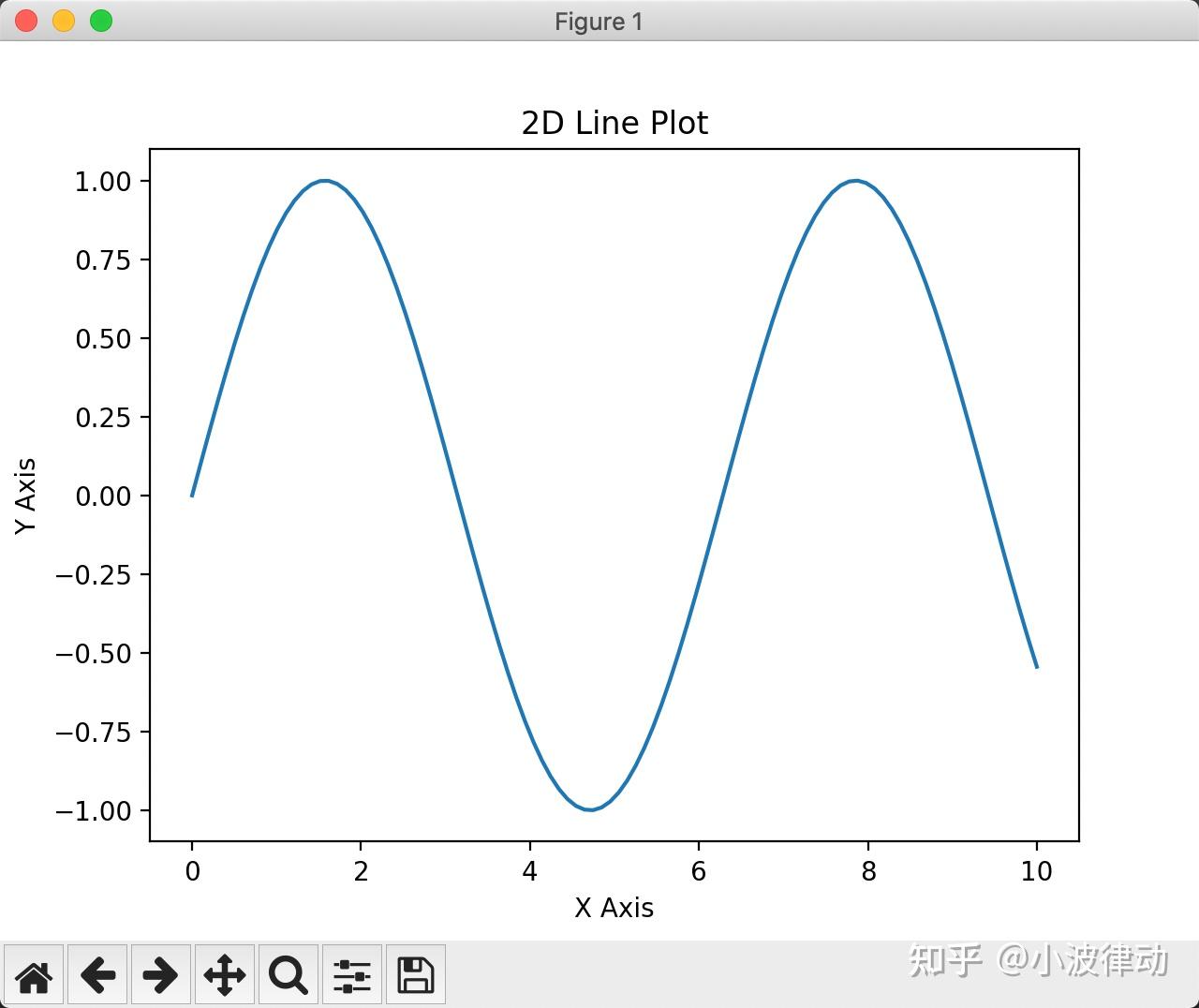
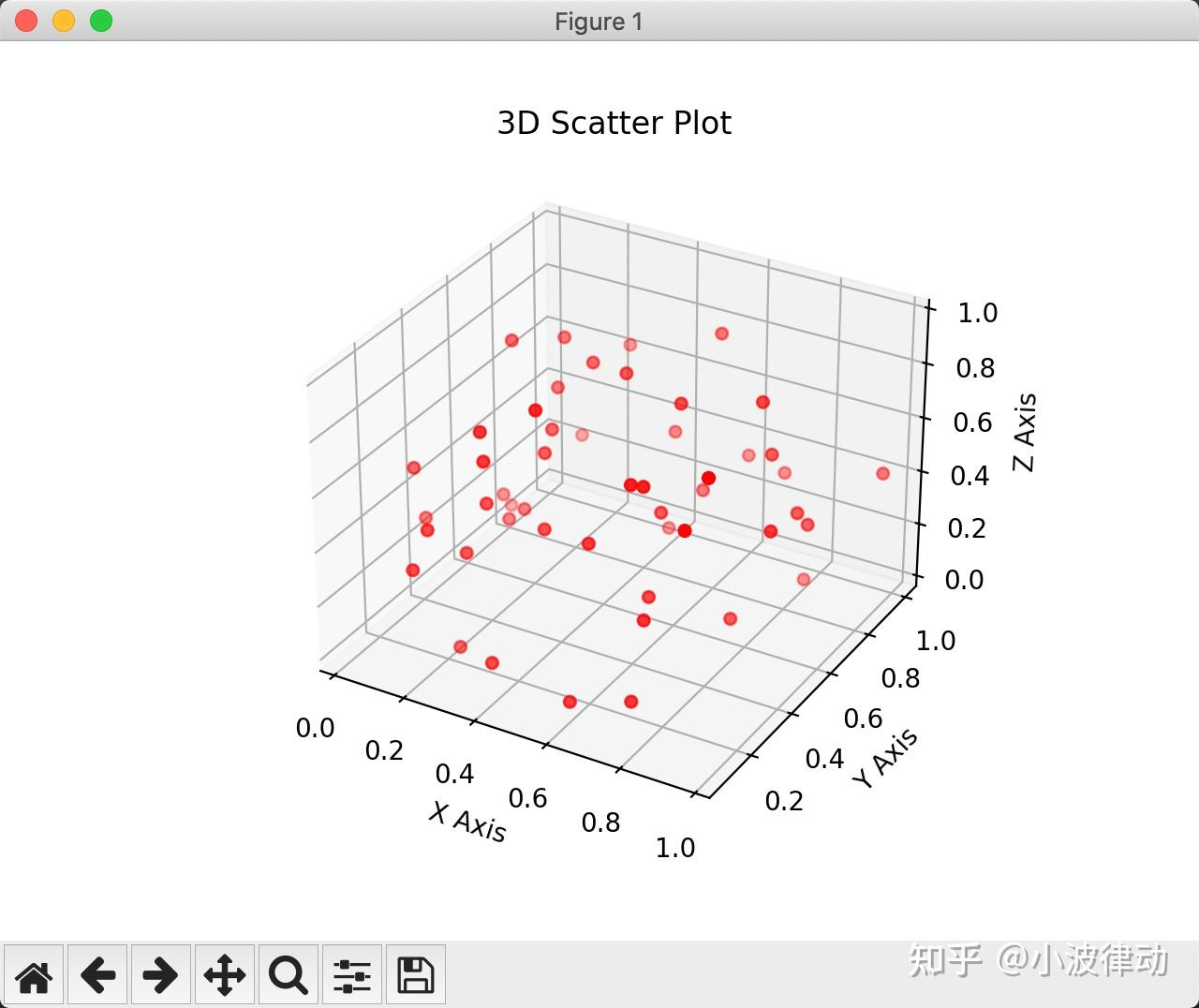
例1:用Matplotlib库画二维、三维图
这个例子中,我们简单画了一个二维正弦曲线,和一个三维散点图。
import matplotlib.pyplot as plt
import numpy as np
# 创建数据
x = np.linspace(0, 10, 100)
y = np.sin(x)
# 使用Matplotlib绘制线形图
plt.plot(x, y)
# 设置图表标题和坐标轴标签
plt.title('2D Line Plot')
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
# 显示图表
plt.show()
# 创建数据
x = np.random.rand(50)
y = np.random.rand(50)
z = np.random.rand(50)
# 创建一个3D坐标轴
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# 使用Matplotlib绘制三维散点图
ax.scatter(x, y, z, c='r', marker='o')
# 设置图表标题和坐标轴标签
ax.set_title('3D Scatter Plot')
ax.set_xlabel('X Axis')
ax.set_ylabel('Y Axis')
ax.set_zlabel('Z Axis')
# 显示图表
plt.show()输出结果:
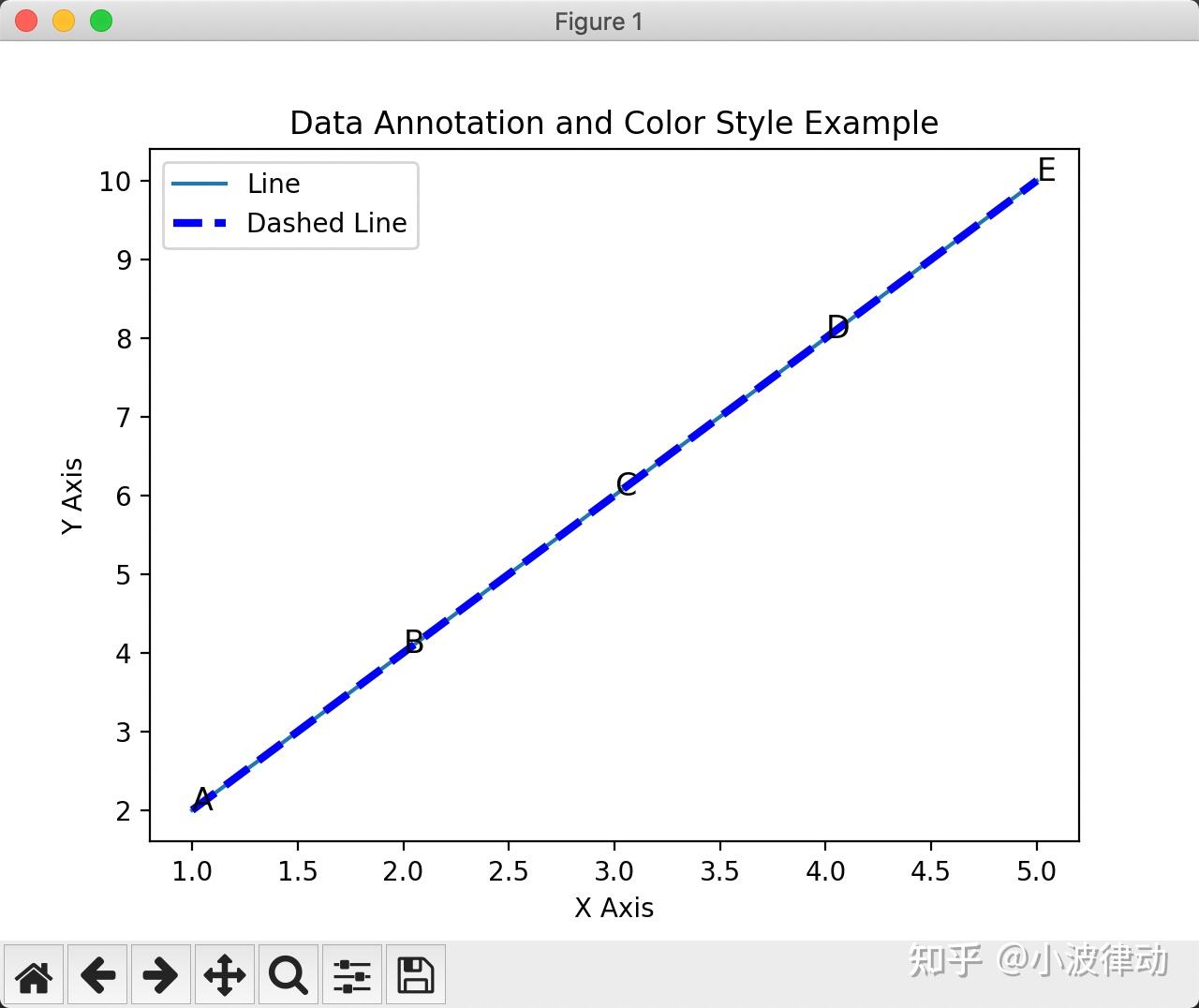
例2:用Matplotlib库画图、添加标注、设置颜色样式
这个例子中,我们画了两条直线,一条是普通直线,一条设置了颜色和线条样式,然后在线条上标注了五个点。
import matplotlib.pyplot as plt
# 示例数据
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
labels = ['A', 'B', 'C', 'D', 'E']
# 绘制线图
plt.plot(x, y, label='Line')
# 设置颜色和线条样式
plt.plot(x, y, color='blue', linewidth=3, linestyle='--', label='Dashed Line')
# 添加数据标注
for i in range(len(x)):
plt.annotate(labels[i], (x[i], y[i]), fontsize=12)
# 添加图例
plt.legend()
# 添加标题和坐标轴标签
plt.title('Data Annotation and Color Style Example')
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
# 显示图形
plt.show()输出结果:
Scikit-learn(必选)
Scikit-learn是一个基于Python的开源机器学习库,它建立在NumPy、SciPy和matplotlib等基础工具包之上。Scikit-learn最初是由David Cournapeau在Google Summer of Code项目中开发的,后来由其他开发人员进行了重写和扩展。
Scikit-learn库提供了简单高效的数据挖掘和数据分析工具,可以在各种环境中重复使用。它包含众多顶级机器学习算法,主要有六大基本功能,分别是分类、回归、聚类、数据降维、模型选择和数据预处理。Scikit-learn具有非常活跃的用户社区,基本上其所有的功能都有非常详尽的文档供用户查阅。
以下是对 Scikit-learn 库的一些介绍:
- 丰富的算法和模型:Scikit-learn 包含了各种常见的机器学习算法,如线性回归、逻辑回归、决策树、随机森林、支持向量机、聚类、朴素贝叶斯等。这些算法可以用于分类、回归、聚类、异常检测等不同的任务。
- 数据预处理:Scikit-learn 提供了一系列的数据预处理功能,例如特征缩放、标准化、缺失值处理、特征选择等。这些工具可以帮助你对数据进行清洗和准备,以便更好地适应不同的机器学习算法。
- 模型评估和选择:该库包含了多种模型评估指标和方法,如准确率、召回率、F1 分数等。它还提供了交叉验证等技术来对模型进行评估和调优,帮助你选择最佳的模型和超参数。
- 易于使用的接口:Scikit-learn 的 API 设计简洁直观,使得使用各种算法变得相对容易。它的模型通常具有一致的接口和参数,方便进行快速实验和比较不同算法的效果。
- 扩展性和兼容性:Scikit-learn 可以与其他数据分析库和框架很好地集成,如 Pandas、NumPy 和 Matplotlib。它也支持多种编程语言,如 Python。
- 广泛的应用和社区支持:Scikit-learn 在学术界和工业界都得到了广泛的应用,有大量的文档、教程和案例可供参考。同时,社区也非常活跃,你可以在网上找到许多关于 Scikit-learn 的讨论和解决方案。
例1:用Scikit-learn库训练线性回归模型
在这个例子中,我们首先加载了一个乳腺癌数据集。然后,我们将数据集划分为训练集和测试集。接下来,我们创建了一个线性回归模型,并使用训练集数据对模型进行拟合。最后,我们使用模型对测试集进行预测,并计算预测结果与真实结果之间的均方误差。
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 加载数据集
breast_cancer = load_breast_cancer()
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(breast_cancer.data, breast_cancer.target, test_size=0.2, random_state=42)
# 创建线性回归模型
regression_model = LinearRegression()
# 拟合训练数据
regression_model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = regression_model.predict(X_test)
# 计算均方误差(MSE)作为评估指标
mse = mean_squared_error(y_test, y_pred)
print("均方误差:", mse)输出结果:
均方误差: 0.0641088624702944例2:用Scikit-learn库做数据预处理
这个例子展示了Scikit-learn库强大的数据处理能力。一般情况下,我们引入的原始数据集都是非标注的,为了能达到模型训练的要求,都必须进行数据预处理操作,本例对数据做了标准化和独热编码操作。
import numpy as np
from sklearn.preprocessing import OneHotEncoder,StandardScaler
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
category_feature = ['A', 'B', 'C']
# 进行特征标准化和独热编码
scaler = StandardScaler()
encoder = OneHotEncoder(sparse=False)
data_scaled = scaler.fit_transform(data)
category_feature = np.array(category_feature)
encoded_category_feature = encoder.fit_transform(category_feature.reshape(-1, 1))
# 组合标准化和独热编码的结果
preprocessed_data = np.hstack((data_scaled, encoded_category_feature))
print(preprocessed_data)输出结果:
[[-1.22474487 -1.22474487 -1.22474487 1. 0. 0. ]
[ 0. 0. 0. 0. 1. 0. ]
[ 1.22474487 1.22474487 1.22474487 0. 0. 1. ]]例3:用Scikit-learn库训练模型并评估模型
在这个例子中,我们首先加载了鸢尾花数据集,并将其划分为训练集和测试集。然后,我们对数据进行了标准化处理,以消除特征之间的量纲差异。接下来,我们创建了一个SVM分类器,并用训练数据对其进行训练。
训练完成后,我们使用测试集对模型进行评估。评估指标包括准确率(accuracy)、混淆矩阵(confusion matrix)和分类报告(classification report)。这些指标提供了关于模型性能的不同方面的信息。
最后,我们使用交叉验证(cross-validation)来进一步评估模型的性能。交叉验证将数据集划分为多个子集,并在这些子集上多次训练和测试模型,以得到更可靠的评估结果。在这个例子中,我们使用了5折交叉验证(cv=5),并输出了每次迭代的分数以及平均分数。
通过不同维度的模型评估,我们可以看出Scikit-learn库有多么强大!
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 创建SVM分类器
clf = SVC(kernel='linear', C=1, random_state=42)
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
# 输出混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print(f"Confusion Matrix:\n{cm}")
# 输出分类报告
report = classification_report(y_test, y_pred)
print(f"Classification Report:\n{report}")
# 交叉验证评估模型
scores = cross_val_score(clf, X, y, cv=5)
print(f"Cross-validation scores: {scores}")
print(f"Cross-validation mean score: {np.mean(scores)}")输出结果:
Accuracy: 0.9777777777777777
Confusion Matrix:
[[19 0 0]
[ 0 12 1]
[ 0 0 13]]
Classification Report:
precision recall f1-score support
0 1.00 1.00 1.00 19
1 1.00 0.92 0.96 13
2 0.93 1.00 0.96 13
accuracy 0.98 45
macro avg 0.98 0.97 0.97 45
weighted avg 0.98 0.98 0.98 45
Cross-validation scores: [0.96666667 1. 0.96666667 0.96666667 1. ]
Cross-validation mean score: 0.9800000000000001TensorFlow(必选)
TensorFlow是由Google Brain团队开发的一个开源软件库,主要用于机器学习和深度学习任务。TensorFlow的名字来自于张量(Tensor)和流(Flow),代表了一个数据流图中的数学运算操作,以及数据在这些操作之间的流动。
TensorFlow的基本概念包括:
- 张量(Tensor):TensorFlow的基本数据类型,类似于多维数组。在TensorFlow中,所有的数据都通过张量来表示,包括输入、输出、权重等。
- 计算图(Graph):定义了数据流图中的所有操作和数据依赖关系。它包括节点(Node)和边(Edge),节点代表了一种操作(如加法、乘法),边代表了数据流(如张量)。
- 会话(Session):是TensorFlow执行计算图的环境,通过会话可以对计算图中的操作进行执行和求值。
TensorFlow的使用场景包括:
- 图像识别:TensorFlow提供了卷积神经网络(CNN)等深度学习模型,可用于图像识别、目标检测等任务。
- 自然语言处理:TensorFlow提供了循环神经网络(RNN)等模型,可用于语音识别、机器翻译等自然语言处理任务。
- 数据分析:TensorFlow提供了各种机器学习算法,可用于数据分析、预测建模等任务。
- 强化学习:TensorFlow提供了强化学习算法,可用于各种智能决策场景,如游戏AI、机器人控制等。
TensorFlow编程接口支持Python和C++。随着1.0版本的公布,相继支持了Java、Go、R和Haskell API的alpha版本。2.0版本又把Keras的相关API都嵌入到tf中,使得其功能更加强大。但由于版本变动过大,因此1.0版本的代码在2.0版本好多都报错,造成版本升级迭代困难。新入行的人建议直接从2.0版本开始。
在2017年,Tensorflow独占鳌头,处于深度学习框架的领先地位,尤其是工业级应用领域。;但截至目前已经和Pytorch不争上下,甚至略输于Pytorch。
这里需要强调一下,我们上面介绍了Scikit-learn库,但是TensorFlow 和 Scikit-learn 在某些方面是有一定功能重合的,比如线性回归等传统机器学习算法,但他们应用场景还是有很大差别的。
- TensorFlow 主要专注于深度学习和神经网络的开发与训练。它提供了更底层的工具和灵活性,允许用户构建复杂的模型结构,并支持分布式训练等高级特性。TensorFlow 适用于大规模数据处理和复杂模型的构建。
- 而 Scikit-learn 则更侧重于传统的机器学习算法和数据预处理。它提供了一系列易于使用的接口和工具,例如分类、回归、聚类、特征工程等。Scikit-learn 旨在帮助用户快速应用和比较不同的机器学习算法。
总结一下:TensorFlow 更适合深度学习和神经网络的研究与开发,而 Scikit-learn 更适合传统机器学习任务和数据预处理。
例1:TensorFlow神经元网络训练演示
本例中,我们首先加载了鸢尾花数据集,并将类别标签进行独热编码。然后,我们使用TensorFlow 的 Keras API 构建了一个简单的神经网络模型,包括两个密集连接层。通过划分训练集和测试集,我们可以训练模型并在测试集上进行评估。最后,打印出测试集上的损失和准确率。这个神经元网络比较简单,仅适合演示。
import tensorflow as tf
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将类别进行独热编码
encoder = OneHotEncoder(sparse=False)
y_encoded = encoder.fit_transform(y.reshape(-1, 1))
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, test_size=0.2, random_state=42)
# 定义模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(4,)),
tf.keras.layers.Dense(3, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=50, validation_split=0.1)
# 在测试集上进行评估
test_loss, test_accuracy = model.evaluate(X_test, y_test)
print("Test Loss:", test_loss)
print("Test Accuracy:", test_accuracy)输出结果:
Test Loss: 0.4498146176338196
Test Accuracy: 0.8999999761581421例2:用TensorFlow训练RNN神经元网络
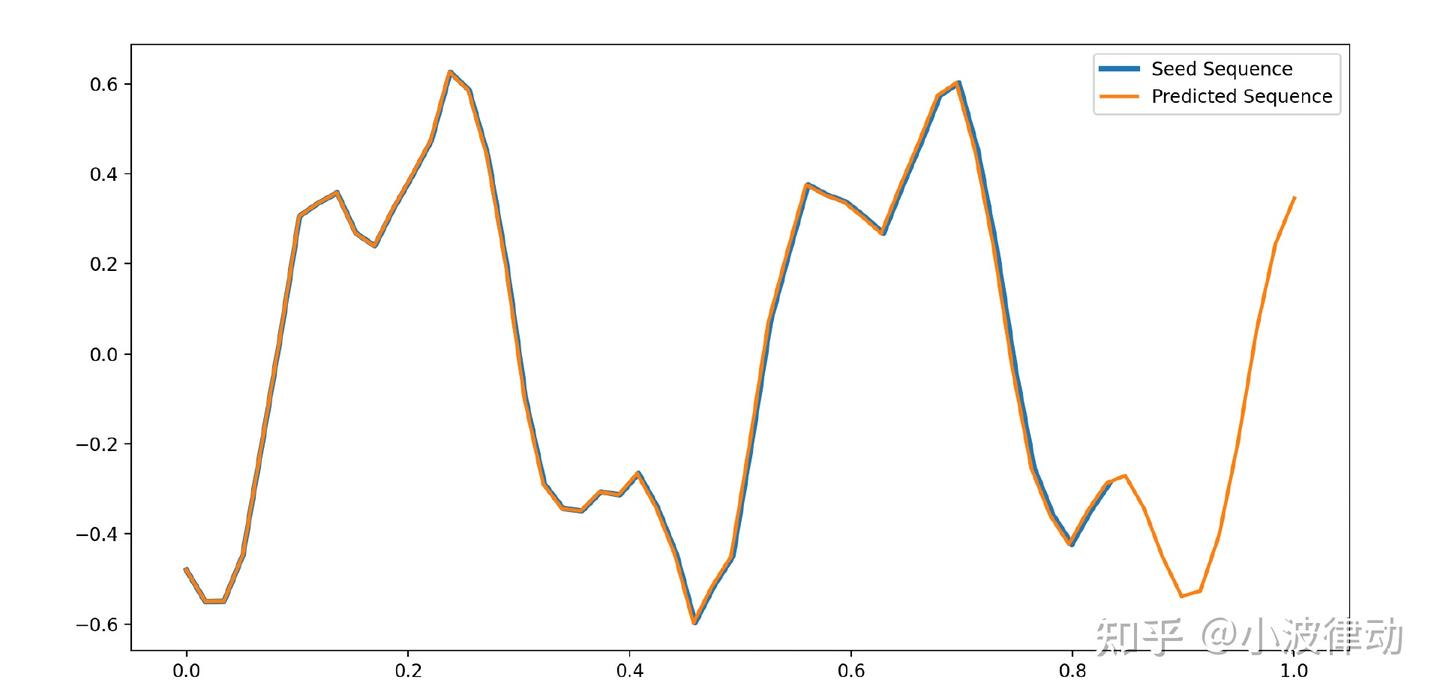
本例演示TensorFLow训练复杂的RNN神经网络,为了充分展示RNN的记忆性特点,我们构建一个正弦曲线序列。在这个任务中,模型需要学习预测一个序列的下一个元素,该元素依赖于前面的几个元素。我们使用Keras构建的简单RNN模型的示例,用于预测正弦波序列中的下一个点。本例中,RNN模型将会学习识别正弦波的模式,并使用它的“记忆”来预测序列的下一个点。
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense
# 生成正弦波数据
def generate_sine_wave(batch_size, n_steps):
freq1, freq2, offsets1, offsets2 = np.random.rand(4, batch_size, 1)
time = np.linspace(0, 1, n_steps)
series = 0.5 * np.sin((time - offsets1) * (freq1 * 10 + 10))
series += 0.2 * np.sin((time - offsets2) * (freq2 * 20 + 20))
series += 0.1 * (np.random.rand(batch_size, n_steps) - 0.5)
return series[..., np.newaxis].astype(np.float32)
# 超参数
batch_size = 10000
n_steps = 50
n_features = 1
# 生成训练数据
X_train, y_train = [], []
for _ in range(batch_size):
x = generate_sine_wave(1, n_steps + 1)[0]
X_train.append(x[:n_steps, :])
y_train.append(x[n_steps, :])
X_train, y_train = np.array(X_train), np.array(y_train)
print(X_train.shape)
# 构建RNN模型
model = Sequential([
SimpleRNN(50, return_sequences=True, input_shape=[X_train.shape[1], X_train.shape[2]]),
SimpleRNN(50),
Dense(n_features)
])
# 编译模型
model.compile(optimizer='adam', loss='mse')
# 训练模型
history = model.fit(X_train, y_train, epochs=100, verbose=1, validation_split=0.2)
# 评估模型
loss = model.evaluate(X_train, y_train, verbose=0)
print('Train loss:', loss)
# 使用模型进行预测
def predict_sequence(model, seed_sequence):
n_predict = 10 # 预测接下来的10个点
x = seed_sequence
for _ in range(n_predict):
x_pred = model.predict(x.reshape((1, x.shape[0], x.shape[1])))
x = np.concatenate([x, x_pred], axis=0)
return x
# 可视化预测结果
seed_sequence = generate_sine_wave(1, n_steps)[0]
predicted_sequence = predict_sequence(model, seed_sequence)
plt.figure(figsize=(12, 6))
plt.plot(np.linspace(0, 1 - 1/6, n_steps), seed_sequence.flatten(), label='Seed Sequence', linewidth=3)
plt.plot(np.linspace(0, 1, n_steps + 10), predicted_sequence.flatten(), label='Predicted Sequence', linewidth=2)
plt.legend()
plt.show()输出结果:从输出结果可见,右侧橙色曲线基本符合正确的走势。注:本例图形和正弦曲线稍微有些差距,但我们的目的不是为了完全拟合正弦曲线。
PyTorch(必选)
PyTorch是由Facebook人工智能研究院(FAIR)于2017年1月推出的一个开源的Python机器学习库,主要用于深度学习领域。它的前身是Torch,一个由Lua语言编写的科学计算框架,用于支持大量的机器学习算法。然而,由于Lua语言相对小众,Torch的流行度受到限制,于是FAIR决定使用更普及的Python语言重新开发Torch,从而诞生了PyTorch。
PyTorch继承了Torch的底层架构,但提供了Python接口,使其更加易于使用。它基于动态计算图,这意味着在构建和训练神经网络时,开发者可以像编写普通的Python程序一样进行调试和修改。这种灵活性使得PyTorch在研究和原型设计方面非常受欢迎。
PyTorch提供了两个主要的高级功能:一是具有强大的GPU加速的张量计算,类似于NumPy;二是包含自动求导系统的深度神经网络。这使得PyTorch在深度学习领域具有独特的优势,可以快速实现和优化复杂的神经网络模型。
PyTorch的主要特点包括:
- 动态图:PyTorch使用动态计算图,这意味着你可以在构建神经网络时像编写普通Python程序一样进行调试和修改。这种灵活性使得PyTorch在研究和原型设计方面非常受欢迎。
- 张量计算:PyTorch提供了多维数组对象(称为张量),支持各种张量操作,包括数学运算、线性代数、矩阵运算等。这些操作可以在GPU上高效执行,加速深度学习模型的训练。
- 自动微分:PyTorch具有自动微分功能,可以自动计算神经网络中的梯度。这使得在训练过程中反向传播算法的实现变得非常简单。
- 深度学习框架:PyTorch提供了丰富的深度学习框架,包括卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)等。这些框架可以方便地用于图像识别、自然语言处理、语音识别等任务。
- 社区支持:PyTorch有一个庞大的社区,提供了许多有用的资源和工具,如教程、示例代码、预训练模型等。这使得PyTorch成为深度学习领域的热门选择之一。
PyTorch与TensorFLow都是强大的机器学习库,被广泛用于神经元网络及大模型训练。这两个库二选一即可,从目前的趋势来看PyTorch逐渐略胜出一些。
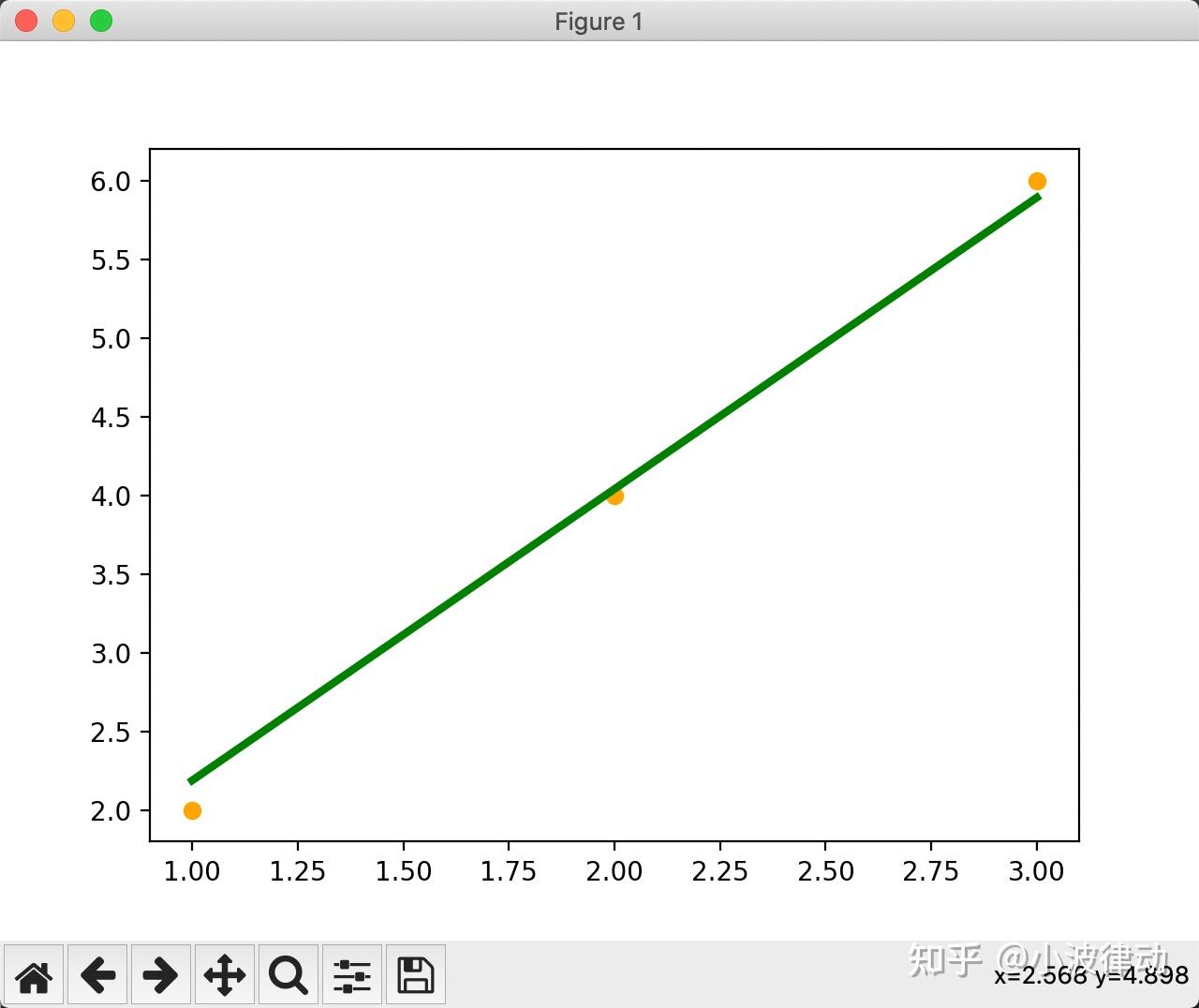
例1:PyTorch训练线性回归模型
这个例子中,我们首先创建了一个简单的线性数据集,然后定义了一个线性回归模型。我们使用均方误差(MSE)作为损失函数,并使用随机梯度下降(SGD)作为优化器。接着,我们对模型进行了100轮的训练,并在每10轮输出一次损失值。最后,我们使用训练好的模型对输入数据进行预测,并将结果可视化。
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# 创建一个简单的线性数据集
x_data = torch.tensor([[1.0], [2.0], [3.0]], dtype=torch.float32)
y_data = torch.tensor([[2.0], [4.0], [6.0]], dtype=torch.float32)
# 定义线性模型
linear_model = nn.Linear(1, 1)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(linear_model.parameters(), lr=0.01)
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
# 前向传播
y_pred = linear_model(x_data)
# 计算损失
loss = criterion(y_pred, y_data)
# 反向传播
optimizer.zero_grad()
loss.backward()
# 更新权重
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 测试模型
with torch.no_grad():
y_pred = linear_model(x_data)
print(y_pred)
# 可视化结果
plt.scatter(x_data.numpy(), y_data.numpy(), color="orange")
plt.plot(x_data.numpy(), y_pred.numpy(), 'g-', lw=3)
plt.text(0.5, 0, 'Loss=%.4f' % loss.item(), fontdict={'size': 20, 'color': 'red'})
plt.show()输出结果:
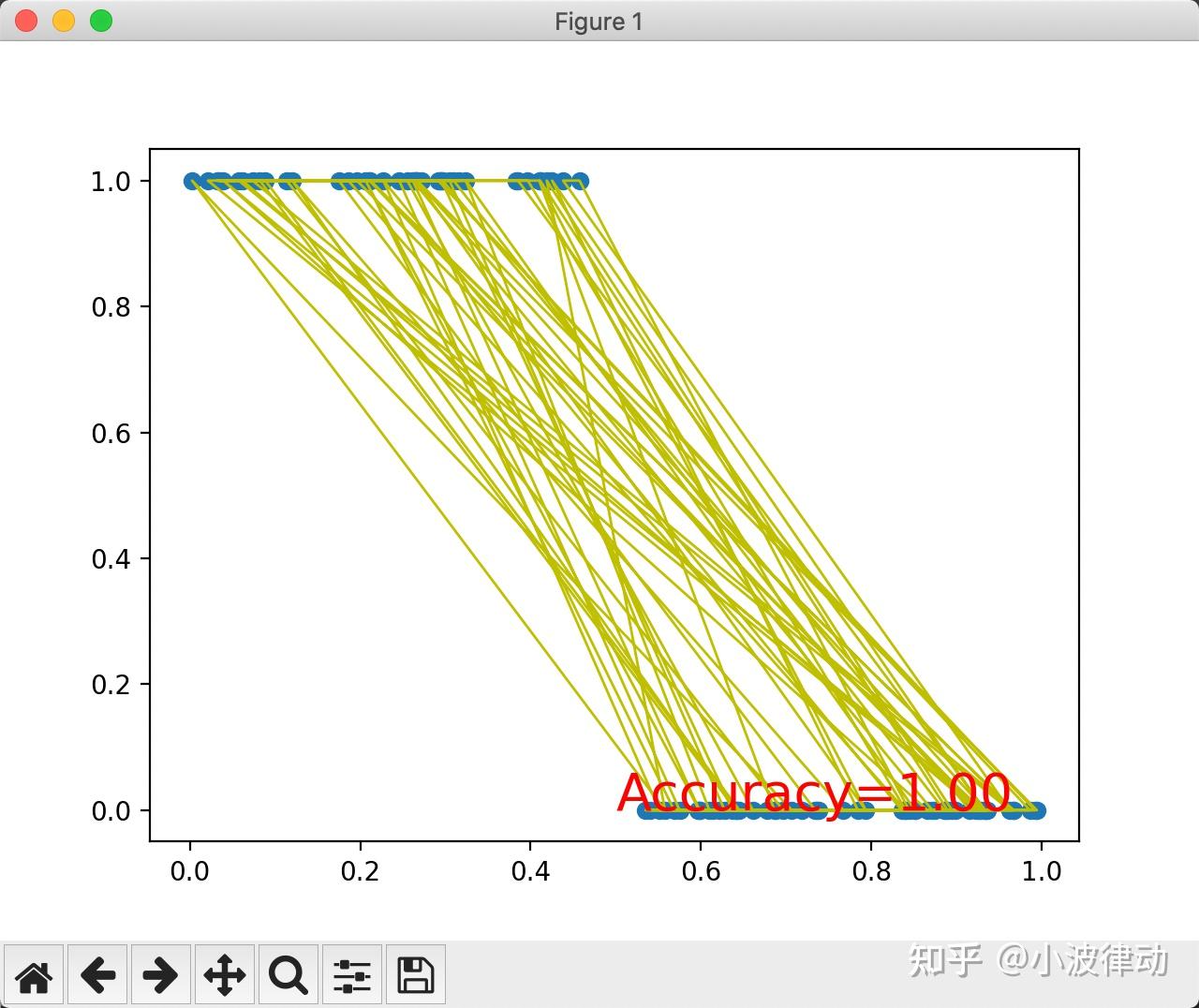
例2:PyTorch训练神经元网络模型
在这个例子中,我们首先生成了一个简单的二分类数据集,其中x_data是随机生成的输入数据,y_data是根据x_data的值生成的标签(0或1)。
然后,我们定义了一个名为SimpleNeuralNetwork的神经元网络类,它包含一个输入层到隐藏层的全连接层(fc1),一个ReLU激活函数,一个隐藏层到输出层的全连接层(fc2),以及一个Sigmoid激活函数用于将输出压缩到0和1之间。
接着,我们实例化了这个网络,并定义了二分类交叉熵损失函数(BCELoss)和随机梯度下降优化器(SGD)。
在训练循环中,我们进行了前向传播、损失计算、反向传播和权重更新。每100个epoch打印一次当前的损失值。
最后,我们测试了网络的准确性,并绘制了数据点和网络预测结果的图表。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
# 生成一个简单的二分类数据集
x_data = torch.tensor(np.random.rand(100, 1), dtype=torch.float32)
y_data = torch.tensor(x_data.numpy() < 0.5, dtype=torch.float32) # 0 for x < 0.5, 1 for x >= 0.5
# 定义神经元网络
class SimpleNeuralNetwork(nn.Module):
def __init__(self):
super(SimpleNeuralNetwork, self).__init__()
self.fc1 = nn.Linear(1, 10) # 输入层到隐藏层,10个神经元
self.relu = nn.ReLU()
self.fc2 = nn.Linear(10, 1) # 隐藏层到输出层
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
return out
# 实例化网络
model = SimpleNeuralNetwork()
# 定义损失函数和优化器
criterion = nn.BCELoss() # 二分类交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 训练网络
num_epochs = 1000
for epoch in range(num_epochs):
# 前向传播
outputs = model(x_data)
# 计算损失
loss = criterion(outputs, y_data)
# 反向传播
optimizer.zero_grad()
loss.backward()
# 更新权重
optimizer.step()
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item()}')
# 测试网络
with torch.no_grad():
predictions = model(x_data)
predictions_cls = predictions.round() # 将输出四舍五入为0或1
correct = (predictions_cls == y_data).sum().item()
print(f'Accuracy: {correct / len(y_data)}')
# 可视化结果
plt.scatter(x_data.numpy(), y_data.numpy())
plt.plot(x_data.numpy(), predictions_cls.numpy(), 'y-', lw=1)
plt.text(0.5, 0, 'Accuracy=%.2f' % (correct / len(y_data)), fontdict={'size': 20, 'color': 'red'})
plt.show()输出结果:
Keras(可选)
Keras是一个高级神经网络API,用Python编写,能够在TensorFlow、CNTK或Theano之上运行。它旨在使得构建和训练深度学习模型变得简单、快速和可靠。
以下是Keras库的主要功能:
- 构建模型:Keras允许用户通过简单的API构建神经网络模型。用户可以使用顺序模型(Sequential)或者函数式API(Functional API)来创建模型。顺序模型适合简单的线性堆叠模型,而函数式API则提供了更大的灵活性,允许用户构建具有共享层、多输入或多输出的复杂模型。
- 层(Layers):Keras提供了丰富的层类型,包括全连接层(Dense)、卷积层(Conv2D、Conv1D)、池化层(MaxPooling2D、AveragePooling2D)、循环层(LSTM、GRU)、嵌入层(Embedding)、归一化层(BatchNormalization)等。这些层可以方便地添加到模型中,以实现不同的网络结构。
- 优化器(Optimizers):Keras内置了多种优化器,如SGD(随机梯度下降)、Adam、RMSprop等,用于调整模型参数以最小化损失函数。用户可以根据需要选择合适的优化器,并设置相应的学习率等参数。
- 损失函数(Loss Functions):Keras提供了多种损失函数,如均方误差(Mean Squared Error)、交叉熵(Categorical Crossentropy)、二元交叉熵(Binary Crossentropy)等,用于计算模型预测与实际标签之间的差异。用户可以根据任务类型选择合适的损失函数。
- 数据预处理和增强:Keras提供了数据预处理和增强的工具,如数据标准化(Standardization)、归一化(Normalization)、随机裁剪(Random Cropping)、随机翻转(Random Flipping)等,以提高模型的泛化能力。
- 回调(Callbacks):Keras的回调机制允许用户在训练过程中执行自定义操作,如模型保存(ModelCheckpoint)、早停(EarlyStopping)、学习率调整(LearningRateScheduler)等。这些回调可以在训练的不同阶段触发,以满足特定需求。
- 可视化:Keras支持训练过程中的可视化,包括损失函数和准确率的实时曲线、模型结构图等。这些可视化工具可以帮助用户更好地理解模型性能和调试模型。
TensorFlow 2.0及以后的版本已经内置了Keras,因此你不需要再单独安装Keras库。在TensorFlow 2.0及之后的版本中,Keras被整合为TensorFlow的高级API,你可以直接通过tensorflow.keras来使用它。
例1:用Keras库训练神经元网络
在这个例子中,我们创建了一个简单的三层神经网络模型,包括一个输入层、一个隐藏层和一个输出层。输入层有10个神经元(对应于10个特征),隐藏层有64个神经元,输出层有1个神经元(用于二分类问题)。我们使用了ReLU激活函数和Sigmoid激活函数,并选择了Adam优化器和二元交叉熵损失函数。
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
# 定义模型
model = Sequential()
model.add(Dense(units=64, activation='relu', input_shape=(10,))) # 输入层,10个特征,64个神经元,使用ReLU激活函数
model.add(Dense(units=64, activation='relu')) # 隐藏层,64个神经元,使用ReLU激活函数
model.add(Dense(units=1, activation='sigmoid')) # 输出层,1个神经元,使用Sigmoid激活函数(适用于二分类问题)
# 编译模型
model.compile(optimizer=Adam(), loss='binary_crossentropy', metrics=['accuracy'])
# 生成一些随机数据作为示例
import numpy as np
# 生成1000个样本,每个样本有10个特征
x_train = np.random.random((1000, 10))
# 生成对应的二分类标签
y_train = np.random.randint(2, size=(1000, 1))
# 训练模型
model.fit(x_train, y_train, epochs=100, batch_size=32)
# 评估模型
loss, accuracy = model.evaluate(x_train, y_train)
print(f'Loss: {loss}, Accuracy: {accuracy}')输出结果:
Loss: 0.44425880908966064, Accuracy: 0.8270000219345093Seaborn(可选)
Seaborn是一个基于Matplotlib的Python数据可视化库,它提供了一种高度交互式界面,使得制作各种有吸引力的统计图表变得简单容易。Seaborn在Matplotlib的基础上进行了更高级的API封装,从而使得作图更加便捷,能制作出更具有吸引力的图表。Seaborn应被视为Matplotlib的补充,而不是替代物。
Seaborn 库的主要特点包括:
- 美观的默认样式:Seaborn 具有一系列预设的美观样式和调色板,使得创建具有吸引力的图形变得更加容易,无需过多的自定义设置。
- 数据结构友好:Seaborn 与 pandas 的 DataFrame 结构紧密结合,使得数据的加载和可视化更加流畅。
- 丰富的图形类型:Seaborn 提供了多种常见图形的高级实现,如散点图、折线图、柱状图、箱线图、小提琴图等,并支持多种统计可视化。
- 函数式接口:Seaborn 的绘图函数采用了简洁的函数式接口,使得创建复杂的多图布局和组合图形变得更加简单。
- 灵活的调色板:Seaborn 提供了多种内置的调色板,可用于根据数据的分类或数值特征进行颜色映射。
- 图形Facet化:Seaborn 支持将数据分成多个子图进行可视化,有助于比较和分析不同分组的数据。
- 统计推断:一些 Seaborn 函数可以自动进行统计推断,如添加回归线、计算置信区间等。
- 与 Matplotlib 集成:尽管 Seaborn 提供了更高级的功能,但它仍然是基于 Matplotlib 的,因此可以继续使用 Matplotlib 的所有功能和自定义选项。
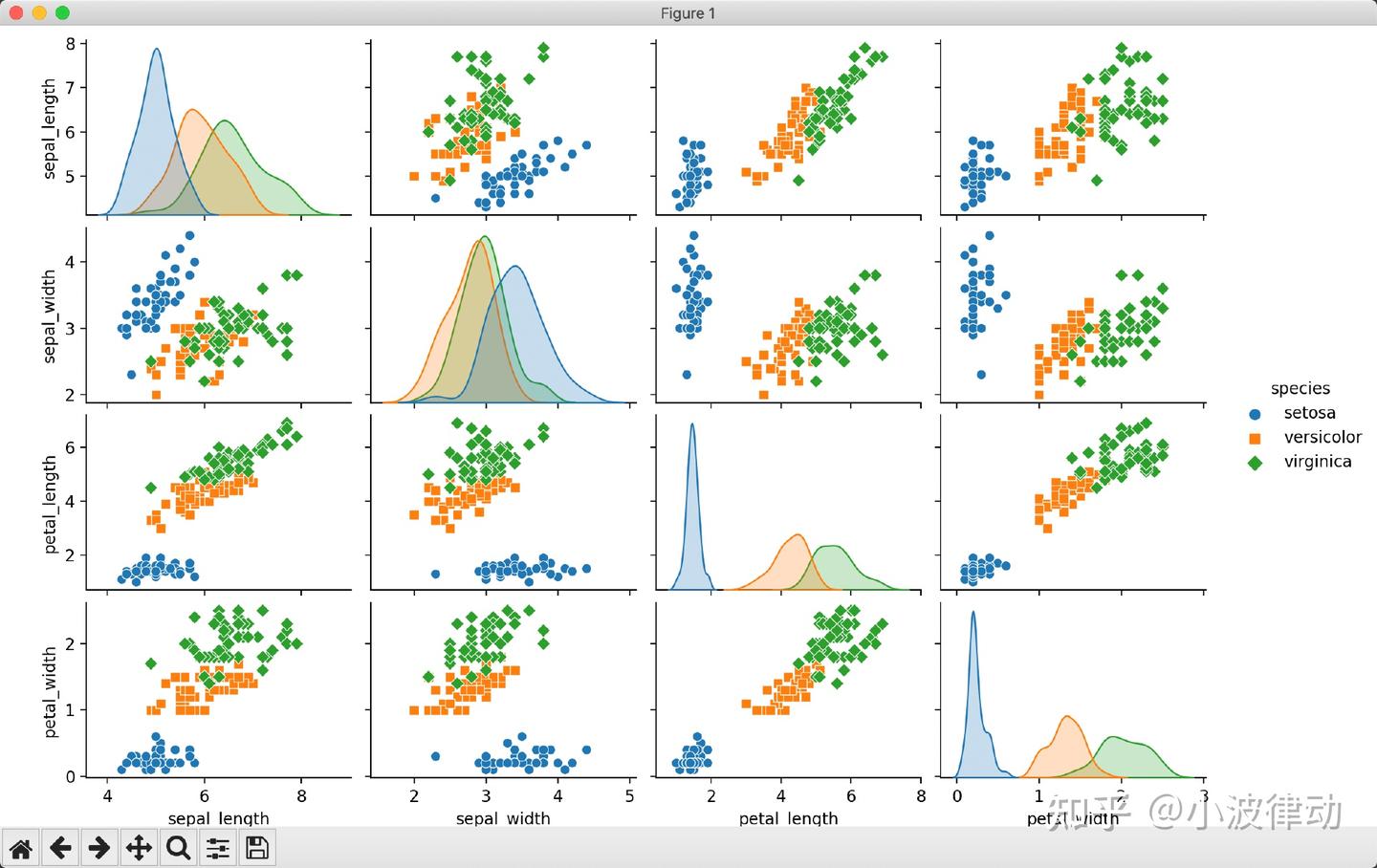
例1:用Seaborn画散点图
下面这个例子我们只用一行代码就画出了散点图。这是因为Seaborn相对于Matplotlib来说更高级,因为它能够自动处理多变量之间的关系,并且提供了美观的默认样式。不过这个例子也有一些问题,虽然Seaborn有很强的推测能力,但是有时候结果不一定是我想要的,我甚至都没想到它能画出这样的图。所以,要想用好Seaborn库,还是要多熟悉它的行为:)
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# 加载内置的Iris数据集
iris = sns.load_dataset("iris")
# 使用Seaborn的pairplot函数绘制散点图矩阵
sns.pairplot(iris, hue="species", markers=["o", "s", "D"])
# 显示图表
plt.show()输出结果:
其他(可选)
除了我们上面介绍的几个常用库外,还有一些更加垂直、更加专业的库,比如自然语言处理方面的库,机器视觉方面的库,网络爬虫方面的库,相关方向的人可以使用。
- NLTK:自然语言处理库,提供了文本处理、分词、词干提取等功能。
- Gensim:用于主题模型和文本相似性分析的库。
- OpenCV:用于计算机视觉的库,提供了图像和视频处理的功能。
- SpaCy:用于自然语言处理的工业级库,提供了词性标注、命名实体识别等功能。
- Scrapy:用于网络爬虫的框架,可从网站上抓取数据。
3、python环境搭建
虽然python拥有强大的开发库支持,但是在日常开发中却经常出现依赖库彼此不兼容的问题。有时候我们更新了其中一个库,可能会导致另外一个库出现了不兼容的问题,再继续更新下去有可能整个环境都报废了,需要花费大量时间重新安装环境。因此,在安装python环境的时候,最好能使用第三方软件来完成。第三方软件的价值是它已经帮你解决了依赖库彼此之间的兼容性问题,你只需要在第三方软件上安装依赖库即可。作者推荐使用Anaconda,操作简单,还可以同时单机支持多个开发环境。
Anaconda内置很多Python依赖库,但还是会有遗漏,有时候会遇到某个库不存在的情况,安装这个库又会依赖一个已经存在的库,且需要升级。这时候可以创建另外一个环境,在另外一个环境做测试,避免直接安装影响到正式环境。
Anaconda更详细的安装过程可以参考:MacBook上安装TensorFlow
4、总结
本文介绍了几个Python常用库,可能会有些不全,一些更垂直、更专业的库以后会陆续介绍。
Python这门语言还是推荐大家学习的,目前看Python应该算是最简单的编程语言了(Matlab除外)。从其简单易学性来看,它已经成为初学者的首选编程语言之一。其语法清晰、结构简洁,使得新手能够更快地掌握编程基础,并在短时间内开始实施项目。这一点对于培养新的开发者群体至关重要,从而保证了Python社区的持续壮大。
Python是一门跨平台的语言,其跨平台特性也为它赢得了大量的支持者。这种特性使得开发者可以在不同的操作系统上运行中间代码,进一步增加了Python的灵活性和普及度。随着技术的不断发展,这种跨平台特性在移动开发、嵌入式系统等领域也展现出了巨大的潜力。
在信号处理领域,使用最广的语言是Matlab,不过Python也不差。本人之前也写过一篇Python与Matlab的对比文章,同样的功能,Python代码比Matlab多一倍。感兴趣的人可以参考:信号处理领域python和matlab的对比

















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









