




 本文详细介绍了NLP中卷积神经网络(CNN)在文本处理中的应用,涉及词嵌入、卷积层、池化操作和模型实现过程。通过实例展示了如何构建一个TextCNN模型,从输入处理到特征提取再到最终的分类预测,包括参数设置和关键代码段。
本文详细介绍了NLP中卷积神经网络(CNN)在文本处理中的应用,涉及词嵌入、卷积层、池化操作和模型实现过程。通过实例展示了如何构建一个TextCNN模型,从输入处理到特征提取再到最终的分类预测,包括参数设置和关键代码段。
1、NLP中的CNN
不同于CV输入的图像像素,NLP的输入是一个个句子或者文档,句子或文档在输入时经过embedding(word2vec或者Glove)会被表示成向量矩阵,其中每一行表示一个词语,行的总数是句子的长度,列的总数就是维度。例如一个包含十个词语的句子,使用了100维的embedding,最后我们就有一个输入为10*100的矩阵。
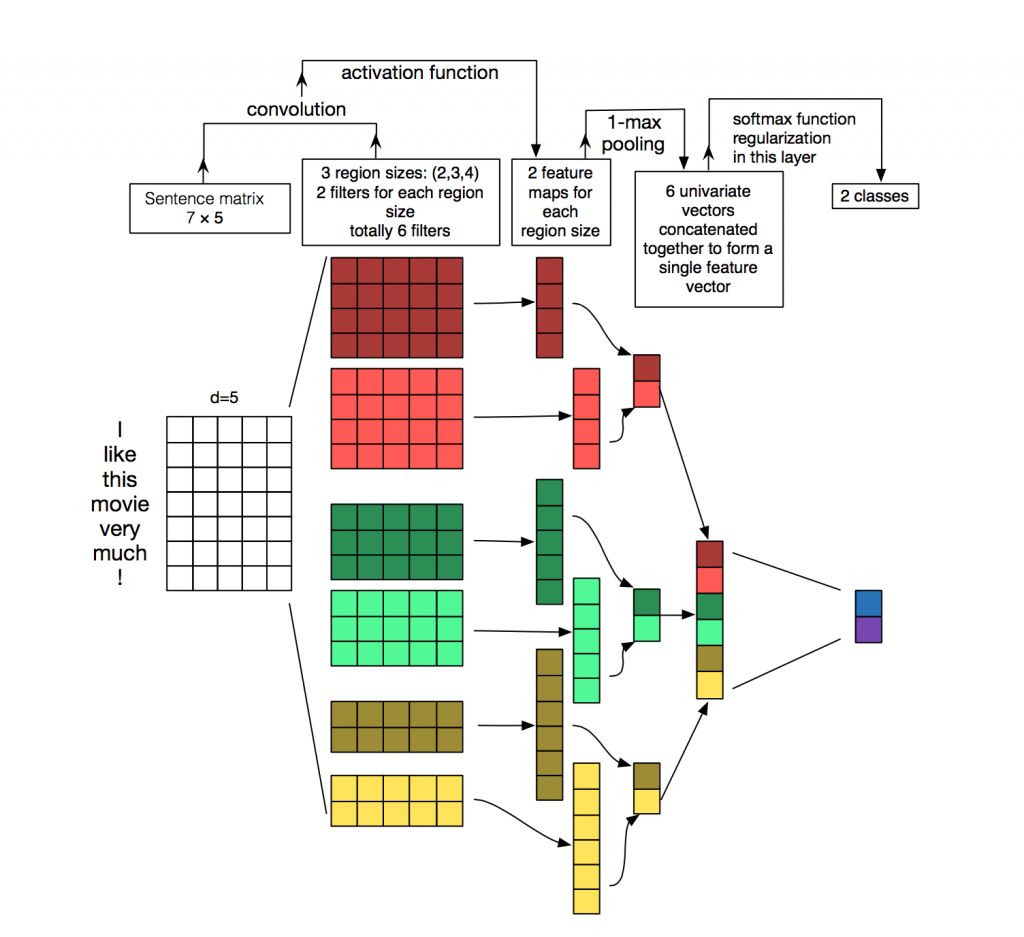
在CV中,filter是以一个patch(任意长度,任意宽度)的形式滑过遍历整个图像,但是在NLP中,filters会覆盖到所有的维度,也就是形状为[filter_size,embed_size].更为具体的理解可以看下图,输入为一个7x5的矩阵,filters的高度分别是2,3,4,宽度和输入矩阵一样为5.每个filter对输入矩阵进行卷积操作得到中间特征,然后通过pooling提取最大值,最终得到一个包含6个值的特征向量。
更直接的解释
输入层:对于文本任务,输入层使用了word embedding来做input
卷积层:在图像处理中经常看到的卷积核都是正方形的,比如4x4,然后在整张图片上沿宽和高逐步进行卷积操作。但是在NLP中输入的”image“是一个词矩阵,比如n个words,每个word用200维的向量表示的话,这个”image"就是nx200的矩阵,卷积核只在高度上进行滑动,在宽度上和word vector保持一致就可以,也就是说每次窗口滑动过的位置都是完成单词,不会将几个单词的一部分“vecor”进行军妓,这也保证了word作为语言中最小颗粒的合理性。
pooling层,这里选用最大池化,由于卷积核和word embedding的宽度一致,一个卷积核对应一个sentence,卷积后得到的结果是一个vector,shape=(sentence_len-filter_window+1,1),那么,在max-pooling后得到的就是一个scaler。
由于max-pooling后得到一个scaler,在nlp中,会有多个filter_window_size(比如3,4,5的宽度分别作为卷积的窗口大小),每个window_size又有num_filters个(比如64个)卷积核。一个卷积核得到的只有一个scaler,将相同window_size卷积出来的num_filter个scaler组合在一起,组成这个window_size下的feature_vector.
softmax层,最后将所有window_size下的feature_vector也组合成一个single_vector,作为最后一层softmax的输入
2、模型实现
模型结构如下
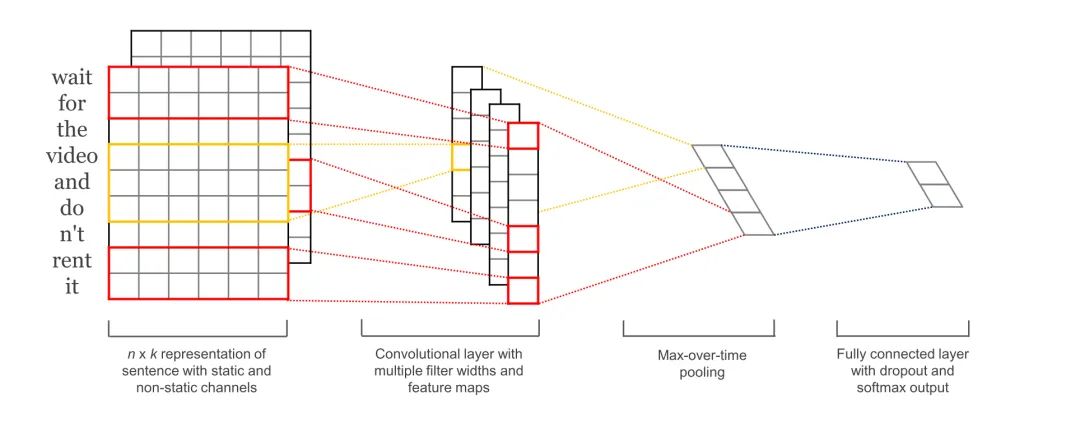
其中第一层为embedding layer,用于把单词映射到一组向量表示,。接下去是一层卷积层,使用多个filters,这里有3,4,5个单词一次遍历。接着是一层max-pooling-layer 得到一列长度特征向量,然后在dropout之后使用softmax得出每一类的概率。
在一个CNN类中实现上述模型
import tensorflow as tf import numpy as np class TextCNN(object): def __init__(self,sequence_length,num_classes,vocab_size,embedding_size,filter_sizes,num_filters,l2_reg_lambda=0.0): """ :param sequence_length: 句子长度 :param num_classes: 类别数目 :param vocab_size: 单词个数 :param embedding_size: 向量维度 :param filter_sizes: filter每次处理几个单词 :param num_filters: 每个尺寸处理几个filter :param l2_reg_lambda: """
filter_sizes是指filter每次处理几个单词,number_filters是指每个尺寸处理几个filter
1、Input placeholder
tf.placeholder是tensorflow的占位符,与feed_dict同时使用。在训练或者测试阶段,我们可以通过feed_dict来喂入输入变量。
# 给变量提供占位符 self.input_x = tf.placeholder(tf.int32, [None, sequence_length], name='input_x') self.input_y = tf.placeholder(tf.float32, [None, num_classes], name='input_y') self.dropout_keep_prob = tf.placeholder(tf.float32, name='dropout_keep_prob')
tf.placeholder函数第一个参数量是变量类型,第二个参数是变量shape,其中None表示sample的个数,第三个name参数用来指定名字。
dropout_keep_prob变量是在dropout阶段使用的,我们在训练的时候选取50%的dropout,在测试时不适用dropout。
2、Embedding layer
我们需要定义的第一个层是embedding layer,用于将词语转变成一组向量表示。
with tf.name_scope('embedding'):
self.W = tf.Variable(tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0), name='weight')
self.embedded_chars = tf.nn.embedding_lookup(self.W, self.input_x)
# TensorFlow’s convolutional conv2d operation expects a 4-dimensional tensor
# with dimensions corresponding to batch, width, height and channel.
self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1)
W是在训练过程中学习到的参数矩阵,然后通过tf.nn.embedding_loopup来查找到与input_input_x相对应的向量表示。
tf.nn.embedding_lookup返回的结果是一个三维向量,[None,sequence_length,embedding_size].但是最后一层的卷积层要求输入为四维向量(batch,w,h,c).所以我们要将结果扩展一个维度,才能符合下一层的输入。
3、卷积层 和 最大池化层
在卷积层中最重要的就是filter。回顾本文的第一张图,我们一共有三种类型的filter,每种类型有两个。我们需要迭代每个filter去处理输入矩阵,将最终得到的所有结果合并成一个大的特征向量。
# conv + max-pooling for each filter
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope('conv-maxpool-%s' % filter_size):
# conv layer
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name='W')
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name='b')
conv = tf.nn.conv2d(self.embedded_chars_expanded, W, strides=[1,1,1,1],
padding='VALID', name='conv')
# activation
h = tf.nn.relu(tf.nn.bias_add(conv, b), name='relu')
# max pooling
pooled = tf.nn.max_pool(h, ksize=[1, sequence_length-filter_size + 1, 1, 1],
strides=[1,1,1,1], padding='VALID', name='pool')
pooled_outputs.append(pooled)
# combine all the pooled fratures
num_filters_total = num_filters * len(filter_sizes)
self.h_pool = tf.concat(pooled_outputs, 3) # why 3?
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])
这里W就是filter矩阵,tf.nn.conv2d是TensorFlow的卷积操作函数,其中几个参数包括:
-
strides表示每一次filter滑动的距离,它是一个四维向量,而且首位和末尾必定是1,
[1, width, height, 1]。 -
padding有两种取值,VALID和SAME。
-
valid是指不在输入矩阵周围填充为0,最后得到的欧普特的尺寸小于input
-
same是指在输入矩阵周围填充为0,最后得到的output的尺寸和input一样
-
这里我们使用的是“VALID”,所以output的尺寸为[1, sequence_length - filter_size + 1, 1, 1]。
接下去是一层max-pooling,pooling很好理解,就是选出其中最大的一个,经过这一层的经过这一层的output尺寸为 [batch_size, 1, 1, num_filters]。
4、Dropout layer
这个比较好理解,就是为了防止过拟合,设置一个神经元激活的概率。每次在dropout层设置一定概率使部分神经元失效,每次失效的神经元都不一样,所以也可以认为是一种bagging的效果。
# dropout
with tf.name_scope('dropout'):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)
5、scores and predictions
我们可以通过对上述得到的特征进行运算得到每个分类的分数score,并且可以通过softmax将score转化成概率分布,选取其中概率最大的一个作为最后的prediction
#score and prediction
with tf.name_scope("output"):
W = tf.get_variable('W', shape=[num_filters_total, num_classes],
initializer = tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name='b')
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
self.score = tf.nn.xw_plus_b(self.h_drop, W, b, name='scores')
self.prediction = tf.argmax(self.score, 1, name='prediction')
6. Loss and Accuracy
通过score我们可以计算得出模型的loss,而我们训练的目的就是最小化这个loss。对于分类问题,最常用的损失函数是cross-entropy 损失
# mean cross-entropy loss
with tf.name_scope('loss'):
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.score, labels=self.input_y)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss
为了在训练过程中实时观测训练情况,我们可以定义一个准确率
# accuracy
with tf.name_scope('accuracy'):
correct_predictions = tf.equal(self.prediction, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, 'float'), name='accuracy')
至此,模型框架已经搭建完成。
完整代码如下
import tensorflow as tf
import numpy as np
class TextCNN(object):
def __init__(self,sequence_length,num_classes,vocab_size,embedding_size,filter_sizes,num_filters,l2_reg_lambda=0.0):
"""
:param sequence_length: 句子长度
:param num_classes: 类别数目
:param vocab_size: 单词个数
:param embedding_size: 向量维度
:param filter_sizes: filter每次处理几个单词
:param num_filters: 每个尺寸处理几个filter
:param l2_reg_lambda:
"""
#设置变量占位符
self.input_x = tf.placeholder(tf.int32,[None,sequence_length],name='input_x')
self.input_y = tf.placeholder(tf.float32,[None,num_classes],name='input_y')
self.dropout_keep_prob = tf.placeholder(tf.float32, name='dropout_keep_prob')
#l2 正则损失
l2_loss = tf.constant(0.0)
#embedding layer
with tf.name_scope('embdding'):
self.W = tf.Variable(tf.random_uniform([vocab_size,embedding_size],-1.0,1.0),name='weight')
self.embedded_chars = tf.nn.embedding_lookup(self.W,self.input_x)
#卷积层希望输入一个4维向量,(batch,width,height,channel)
self.embedded_chars_expands = tf.expand_dims(self.embedded_chars,-1)
#卷积层和最大池化层
pooled_outputs = []
for i,filter_size in enumerate(filter_sizes):
with tf.name_scope('conv-maxpool-%s'%filter_size):
#卷积层
filter_shape = [filter_size,embedding_size,1,num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name='W')
b = tf.Variable(tf.constant(0.1,shape=[num_filters]),name='b')
conv = tf.nn.conv2d(self.embedded_chars_expands,W,strides=[1,1,1,1],padding="VALID",name='conv')
#激活函数
h = tf.nn.relu(tf.nn.bias_add(conv,b),name='relu')
#最大池化
pooled = tf.nn.max_pool(h, ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1], padding='VALID', name='pool')
pooled_outputs.append(pooled)
#拼接所有的池化特征
num_filters_total = num_filters*len(filter_sizes)
self.h_pool = tf.concat(pooled_outputs,3)
self.h_pool_flat = tf.reshape(self.h_pool,[-1,num_filters_total])
#dropout
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat,self.dropout_keep_prob)
#score和预测
with tf.name_scope("output"):
W = tf.get_variable('W', shape=[num_filters_total, num_classes],
initializer=tf.contrib.layers.xavier_initializer()) #这里权重初始化选用xavier,后面可以深入研究
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name='b')
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
self.score = tf.nn.xw_plus_b(self.h_drop, W, b, name='scores')
self.prediction = tf.argmax(self.score, 1, name='prediction')
# 平均损失函数
with tf.name_scope('loss'):
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.score, labels=self.input_y)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss
# 准确率
with tf.name_scope('accuracy'):
correct_predictions = tf.equal(self.prediction, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, 'float'), name='accuracy')
参考
用Tensorflow实现CNN文本分类(详细解释及TextCNN代码解释)_ch的专栏-优快云博客_textcnn文本分类代码

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









