 流量控制策略
流量控制策略








 本文探讨了四种主流的流量控制算法:计数器法、滑动窗口、漏桶算法及令牌桶算法。介绍了各种算法的工作原理、优缺点及应用场景,并提供了部分示例代码。
本文探讨了四种主流的流量控制算法:计数器法、滑动窗口、漏桶算法及令牌桶算法。介绍了各种算法的工作原理、优缺点及应用场景,并提供了部分示例代码。
文章目录
在一个高并发系统中对流量的把控是非常重要的,当巨大的流量直接请求到我们的服务器上没多久就可能造成接口不可用,不处理的话甚至会造成服务雪崩,进而导致整个应用系统瘫痪。
当然在现在的分布式架构下,我们可以通过服务的快速熔断,降级,隔离,限流等方式来应对单个微服务崩溃而导致整个服务不可用的情况,如果你使用的是SpringCloud,你可以使用Hystrix,如果你使用的是SpringCloud-alibaba,那么你可以使用Sentinel来帮助你实现接口的限流,但是,如果我们不依赖于其它组件,那该如何去实现接口的限流呢?
实现接口限流的方法有很多,我大概带着大家一起探讨一下。
1.计数器法
计数器法是限流算法里最简单也是最容易实现的一种算法。
比如我们规定,对于 A 接口来说,我们 1 分钟的访问次数不能超过 100 个。那么我们可以这么做:在一开始的时候,我们可以设置一个计数器 counter,每当一个请求过来的时候,counter 就加 1,如果 counter 的值大于 100 并且该请求与第一个请求的间隔时间还在 1 分钟之内,那么说明请求数过多;如果该请求与第一个请求的间隔时间大于 1 分钟,且 counter 的值还在限流范围内,那么就重置 counter,具体算法的示意图如下:

实现代码如下:(PS:代码为伪代码,防止因为语言不通的原因导致大家理解起来有差异)
/**
* 计数器限流法
*/
public class CounterDemo {
public Long timestamp = System.currentTimeMillis();
public int reqCount = 0;
public final int limit = 100;//时间窗口内的最大请求数
public final Long interval = 60 * 1000l;//时间窗口60s
public boolean grant() {
long now = System.currentTimeMillis();
if (now < timestamp + interval) {//说明在时间窗口内
reqCount++;
return reqCount <= limit;//判断是否超出了限制
} else {//说明已经过了时间窗口,重置数据
timestamp = now;
reqCount = 1;
return true;
}
}
}
是不是相当简单,当然你如果要实现每个ip在指定时间段内的访问次数,你只需要把reqCount和ip绑定即可,代码大致如下所示:
/**
* 计数器限流法
*/
public class CounterDemo {
public final int limit = 100;//时间窗口内的最大请求数
public final Long interval = 60 * 1000l;//时间窗口60s
//key:表示ip,value:是一个Long数组
//其中0:表示该ip的访问次数
//1:时间窗口内第一次访问的时间
public Map<String, Long[]> countMap;
public boolean grant(String ip) {
Long[] values = countMap.get(ip);
Long count = values[0];
Long time = values[1];
long now = System.currentTimeMillis();
if (now < time + interval) {//说明在时间窗口内
count++;
return count <= limit;//判断是否超出了限制
} else {//说明已经过了时间窗口,重置数据
time = now;
count = 1l;
values[0] = count;
values[1] = time;
countMap.put(ip, values);
return true;
}
}
}
是不是很简单,但是不知道大家想过没有,这个算法有个致命的问题:
临界问题

从上图中我们可以看到,假设有一个恶意用户,他在 0:59 时,瞬间发送了 100 个请求,并且 1:00 又瞬间发送了 100 个请求,那么其实这个用户在 1 秒里面,瞬间发送了 200 个请求。我们刚才规定的是 1 分钟最多 100 个请求,也就是每秒钟最多 1.7 个请求,用户通过在时间窗口的重置节点处突发请求,可以瞬间超过我们的速率限制。用户有可能通过算法的这个漏洞,瞬间压垮我们的应用。
这个算法之所以有这个漏洞,其本质就是因为我们统计的精度太低。
那么如何很好地处理这个问题呢?或者说,如何将临界问题的影响降低呢?我们可以看下面的滑动窗口算法。
2.滑动窗口
如果学过 TCP 网络协议的话,那么一定对滑动窗口这个名词不会陌生。
说到了TCP,可能大家脑子里想到的第一个知识点不一定是其定义和概念,而是UDP
相较于UDP,TCP有以下区别:
1、可靠传输
2、流量控制
这两个功能都是依靠滑动窗口来实现的
TCP实现可靠传输依靠的有 序列号、自动重传、滑动窗口、确认应答等机制。如果不存在发送窗口的话,TCP发送一个数据包后会等待ACK包,因为必须要保存对应的数据包,数据包很有可能需要重新发送。
这样的话发送效率会很慢。大部分时间都在等待。
下面这张图,很好地解释了滑动窗口算法:

在上图中,整个红色的矩形框表示一个时间窗口,在我们的例子中,一个时间窗口就是一分钟。然后我们将时间窗口进行划分,比如图中,我们就将滑动窗口划成了 6 格,所以每格代表的是 10 秒钟。每过 10 秒钟,我们的时间窗口就会往右滑动一格。每一个格子都有自己独立的计数器 counter,比如当一个请求在 0:35 秒的时候到达,那么 0:30~0:39 对应的 counter 就会加 1。
那么滑动窗口怎么解决刚才的临界问题的呢?我们可以看上图,0:59 到达的 100 个请求会落在灰色的格子中,而 1:00 到达的请求会落在橘黄色的格子中。当时间到达 1:00 时,我们的窗口会往右移动一格,那么此时时间窗口内的总请求数量一共是 200 个,超过了限定的 100 个,所以此时就能够检测出来触发了限流。
我再来回顾一下刚才的计数器算法,我们可以发现,计数器算法其实就是滑动窗口算法。只是它没有对时间窗口做进一步地划分,为 60s。
由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
我们下面总结一下:滑动窗口的出现是为了解决临界点高流量涌入的情况,即在01:59s-02:00s之间被请求1000次,02:00s-02:01s之间被请求了1000次,这种情况下01:59s-02:01s间隔0.02s之间被请求2000次

2.1 解决方案
指定时间T内,只允许发生N次。我们可以将这个指定时间T,看成一个滑动时间窗口(定宽)。我们采用Redis的zset基本数据类型的score来圈出这个滑动时间窗口。在实际操作zset的过程中,我们只需要保留在这个滑动时间窗口以内的数据,其他的数据不处理即可。
- 每个用户的行为采用一个zset存储,score为毫秒时间戳,value也使用毫秒时间戳(ps:采用时间戳比UUID更加节省内存)
- 只保留滑动窗口时间内的行为记录,如果zset为空,则移除zset,不再占用内存(节省内存)

2.2 ZSET 的使用逻辑
步骤 1:存储请求时间戳
- 每个用户的限流记录存储为一个独立的 ZSET。
- Key:rate_limit:{userId}(根据用户 ID 区分)。
- Score:请求的毫秒时间戳(用于排序和范围查询)。
- Value:与 Score 相同的时间戳(节省内存,避免冗余存储)。
步骤 2:清理过期数据
- 计算当前时间窗口的起始时间戳:
long windowStart = System.currentTimeMillis() - T * 1000L;
- 使用 ZREMRANGEBYSCORE 删除窗口外的时间戳:
redisTemplate.opsForZSet().removeRangeByScore("rate_limit:{userId}", 0, windowStart);
步骤 3:统计当前窗口内的请求数
- 使用 ZCARD 获取当前 ZSET 中的元素数量(即窗口内的请求次数):
Long requestCount = redisTemplate.opsForZSet().zCard("rate_limit:{userId}");
步骤 4:判断是否允许请求
- 如果 requestCount < N:允许请求,并将当前时间戳插入 ZSET:
redisTemplate.opsForZSet().add("rate_limit:{userId}", currentTimestamp, currentTimestamp);
- 否则:拒绝请求。
步骤 5:内存优化
- 如果 ZSET 为空(无请求记录),删除对应的 Key:
if (requestCount == 0) {
redisTemplate.delete("rate_limit:{userId}");
}
2.3 为什么选择 ZSET?
动态维护窗口边界:
- ZSET 的有序性允许通过 ZREMRANGEBYSCORE 快速删除过期数据,无需手动维护固定窗口的切换问题。
高精度限流:
- 相比固定窗口算法,滑动窗口能精确控制任意时间段内的请求数量,避免窗口切换时的突增问题(如 1 秒末和下一秒初的请求叠加)。
内存高效:
- 使用时间戳作为 Score 和 Value,避免冗余存储(如 UUID),节省内存。
删除空的 ZSET 避免无效数据占用内存。
下面具体实战一下:还未集成redis?点击此处试试
package com.example.currentlimiting.service;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
import redis.clients.jedis.Response;
import java.util.List;
/**
* 通过zset实现滑动窗口的限流
*/
public class CouterByWindow {
private Jedis jedis;
public CouterByWindow() {
jedis = new Jedis("127.0.0.1");
jedis.auth("root");
}
/**
* 判断行为是否被允许
*
* @param userId 用户id
* @param actionKey 行为key
* @param period 限流周期
* @param maxCount 最大请求次数(滑动窗口大小)
* @return
*/
public boolean isActionAllowed(String userId, String actionKey, int period, int maxCount) {
String key = this.key(userId, actionKey);
long ts = System.currentTimeMillis();
Pipeline pipe = jedis.pipelined();//启动管道,这是发送大量命令并在完成发送后读取所有响应的一种非常有效的方式
pipe.multi();
//添加元素:ZADD key score member [[score member] [score member] …]
pipe.zadd(key, ts, String.valueOf(ts));
//移除元素:ZREM key member [member …]
pipe.zremrangeByScore(key, 0, ts - (period * 1000));
//zcard获取有序集合的成员数
//card统计key中存在的value的个数即是用户请求的次数
Response<Long> count = pipe.zcard(key);
// 设置行为的过期时间,如果数据为冷数据,zset将会删除以此节省内存空间
pipe.expire(key, period);
pipe.exec();
List<Object> list = pipe.syncAndReturnAll();
boolean sig = count.get() <= maxCount;
pipe.close();
return sig;
}
/**
* 限流key
*
* @param userId
* @param actionKey
* @return
*/
public static String key(String userId, String actionKey) {
return String.format("limit:%s:%s", userId, actionKey);
}
public static void main(String[] args) {
CouterByWindow couterByWindow = new CouterByWindow();
for (int i = 0; i < 20; i++) {
boolean actionAllowed = couterByWindow.isActionAllowed("ninesun", "view", 60, 5);
System.out.println("第" + (i + 1) + "次操作" + (actionAllowed ? "成功" : "失败"));
}
couterByWindow.jedis.close();
}
}
我们第一次运行会发现只有前五次成功,原因很简单,在1分钟内,访问次数已经大于最大访问次数。

然后再接着运行一次,发现一次都没成功,也很好理解,还没超过时间限制,仍然在限制范围

3.漏桶算法
漏桶算法,又叫 leaky bucket。

从图中我们可以看到,整个算法其实十分简单。首先,我们有一个固定容量的桶,有水流进来,也有水流出去。对于流进来的水来说,我们无法预计一共有多少水会流进来,也无法预计水流的速度。但是对于流出去的水来说,这个桶可以固定水流出的速率。而且,当桶满了之后,多余的水将会溢出。
我们只需要将算法中的水换成实际应用中的请求,我们可以看到漏桶算法天生就限制了请求的速度。当使用了漏桶算法,我们可以保证接口会以一个常速速率来处理请求。所以漏桶算法天生不会出现临界问题。
3.1 类比
想象一个底部有小孔的桶,水不断流入(请求),但水以固定速率从桶底流出(处理请求)。
- 桶容量:最大可容纳的请求数。
- 流出速率:单位时间内处理请求的固定速度(如每秒100个请求)。
- 溢出:当桶满时,新请求被丢弃(限流)。
3.2 漏桶算法的工作原理
步骤详解:
- 请求进入桶:
- 所有请求先进入桶中(队列),类似水流进桶。
- 固定速率处理:
- 桶以恒定速率(如每秒100个请求)处理请求,无论请求是否突发。
- 桶满则丢弃:
- 如果桶已满(容量达到上限),新请求直接被丢弃,避免系统过载。
具体的代码实现如下:
public class LeakyBucketRateLimiter {
private final int rate; // 每秒处理请求数(流出速率)
private final BlockingQueue<Request> bucket; // 请求队列
public LeakyBucketRateLimiter(int capacity, int rate) {
this.rate = rate;
this.bucket = new LinkedBlockingQueue<>(capacity);
startConsuming(); // 启动定时处理线程
}
// 添加请求到桶
public boolean addRequest(Request request) {
return bucket.offer(request); // 桶满则返回false(丢弃)
}
// 定时处理请求(每秒处理rate个)
private void startConsuming() {
ScheduledExecutorService executor = Executors.newScheduledThreadPool(1);
executor.scheduleAtFixedRate(() -> {
for (int i = 0; i < rate; i++) {
Request request = bucket.poll();
if (request != null) {
request.process(); // 处理请求
}
}
}, 0, 1, TimeUnit.SECONDS);
}
}
3.3 线程安全保证
这个漏桶算法,消费线程消费请求,消费完成之后桶的容量要恢复,如消费一个请求,桶的容量加1,新进一个请求,桶的容量减一,是怎么做到对于容量的控制保证线程安全的
我们需要针对桶的容量控制做到原子性操作,防止类似秒杀的超卖问题
1.使用线程安全的队列(如 BlockingQueue)
这种实现方式就是上面那段所示的内容
核心是一个固定容量的队列(如 LinkedBlockingQueue)。请求到达时尝试入队(offer()),若队列满则丢弃;消费线程定期从队列中取出请求处理(poll())。
BlockingQueue 的 offer() 和 poll() 方法本身是线程安全的,无需额外同步。
2.使用同步机制(如 synchronized 或 ReentrantLock)
private final int capacity;
private int currentWater = 0;
private final Object lock = new Object();
// 添加请求
public boolean addRequest(int incomingWater) {
synchronized (lock) {
// 允许请求进入
if (currentWater + incomingWater > capacity) {
return false; // 桶满,丢弃
}
currentWater += incomingWater;
return true;
}
}
// 消费请求
public void consumeRequest(int processedWater) {
synchronized (lock) {
currentWater -= processedWater; // 容量恢复
if (currentWater < 0) {
currentWater = 0;
}
}
}
3.利用原子类的CAS
通过原子类(如 AtomicInteger)的原子操作(getAndAdd()、compareAndSet())实现线程安全
private final AtomicInteger currentWater = new AtomicInteger(0);
private final int capacity;
// 添加请求
public boolean addRequest(int incomingWater) {
while (true) {
int current = currentWater.get();
if (current + incomingWater > capacity) {
return false; // 桶满,丢弃
}
if (currentWater.compareAndSet(current, current + incomingWater)) {
return true; // 成功添加
}
}
}
// 消费请求
public void consumeRequest(int processedWater) {
currentWater.getAndAdd(-processedWater);
}
4.令牌桶算法
令牌桶算法,又称 token bucket。为了理解该算法,我们再来看一下算法的示意图:

从图中我们可以看到,令牌桶算法比漏桶算法稍显复杂。
大概描述如下:
所有的请求在处理之前都需要拿到一个可用的令牌才会被处理;
获取不到令牌,则请求返回失败
根据限流大小,设置按照一定的速率往桶里添加令牌;
桶设置最大的放置令牌限制,当桶满时、新添加的令牌就被丢弃或者拒绝;
也就是说,我们有一个固定容量的桶,桶里存放着令牌(token)。桶一开始是空的,token 以一个固定的速率 r 往桶里填充,直到达到桶的容量,多余的令牌将会被丢弃。每当一个请求过来时,就会尝试从桶里移除一个令牌,如果没有令牌的话,请求无法通过。
我们整个过程在做两件事,两件事是并行的,即:
- 通过一定速率去生产令牌至令牌桶
- 请求过来以后并不会被直接处理,而是先去到令牌桶拿令牌,如果可以拿到令牌,就对该请求进行处理,否则不予处理
令牌桶控制的是平均流入速率,速率可高可低,允许有突发请求;
漏桶控制的是恒定的流出速率,从而平滑流入速率。
package com.example.currentlimiting.service;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class TokenLimiter {
private ArrayBlockingQueue<String> blockingQueue;
//容量大小
private int limit;
//令牌的产生间隔
private int period;
//令牌每次产生的个数
private int amount;
public TokenLimiter(int limit, int period, int amount) {
this.limit = limit;
this.period = period;
this.amount = amount;
blockingQueue = new ArrayBlockingQueue<>(limit);
}
private void init() {
for (int i = 0; i < limit; i++) {
blockingQueue.add("lp");
}
}
private void addToken(int amount) {
for (int i = 0; i < amount; i++) {
//溢出返回false
blockingQueue.offer("lp");
}
}
/**
* 获取令牌
*
* @return
*/
public boolean tryAcquire() {
//队首元素出队
return blockingQueue.poll() != null ? true : false;
}
/**
* 生产令牌
*/
private void start(Object lock) {
Executors.newScheduledThreadPool(1).scheduleAtFixedRate(() -> {
synchronized (lock) {
addToken(this.amount);
lock.notify();
}
}, 500, this.period, TimeUnit.MILLISECONDS);
}
/**
* 先生产2个令牌,减少4个令牌;再每500ms生产2个令牌,减少4个令牌
*/
public static void main(String[] args) throws InterruptedException {
int period = 500;
TokenLimiter limiter = new TokenLimiter(8, period, 2);
limiter.init();
Object lock = new Object();
limiter.start(lock);
//让线程先产生2个令牌(溢出)
synchronized (lock) {
lock.wait();
}
for (int i = 0; i < 8; i++) {
for (int j = 0; j < 4; j++) {
String s = i + "," + j + ":";
if (limiter.tryAcquire()) {
System.out.println(s + "拿到令牌");
} else {
System.out.println(s + "拒绝");
}
}
Thread.sleep(period);
}
}
}
当然啦,我们也可以直接使用对于令牌桶的代码实现,可以直接使用 Guava 包中的 RateLimiter。
添加依赖:
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>
//表示每秒产生两个令牌
private static RateLimiter rateLimiter = RateLimiter.create(10);
private static void handle(int i) {
System.out.println("获取到令牌:{" + i + "}");
}
public static void main(String[] args) {
for (int index = 0; index < 100; index++) {
if (rateLimiter.tryAcquire(190, TimeUnit.MILLISECONDS)) {
handle(index);
}
}
}
我大致给大家讲一下RateLimiter吧。
4.1 RateLimiter详解
RateLimiter和Java中的信号量(java.util.concurrent.Semaphore)类似,Semaphore通常用于限制并发量。
比如我们有很多任务需要执行,但是我们不希望每秒超过两个任务执行,那么我们就可以使用RateLimiter:
final RateLimiter rateLimiter = RateLimiter.create(2.0);
void submitTasks(List<Runnable> tasks, Executor executor) {
for (Runnable task : tasks) {
rateLimiter.acquire(); // may wait
executor.execute(task);
}
}
假如我们会产生一个数据流,然后我们想以每秒5kb的速度发送出去.我们可以每获取一个令牌(permit)就发送一个byte的数据,这样我们就可以通过一个每秒5000个令牌的RateLimiter来实现:(1kb=1000byte)
final RateLimiter rateLimiter = RateLimiter.create(5000.0);
void submitPacket(byte[] packet) {
rateLimiter.acquire(packet.length);
networkService.send(packet);
}
4.2 RateLimiter主要接口
RateLimiter其实是一个abstract类,但是它提供了几个static方法用于创建RateLimiter:
/**
* 创建一个稳定输出令牌的RateLimiter,保证了平均每秒不超过permitsPerSecond个请求
* 当请求到来的速度超过了permitsPerSecond,保证每秒只处理permitsPerSecond个请求
* 当这个RateLimiter使用不足(即请求到来速度小于permitsPerSecond),会囤积最多permitsPerSecond个请求
*/
public static RateLimiter create(double permitsPerSecond);
/**
* 创建一个稳定输出令牌的RateLimiter,保证了平均每秒不超过permitsPerSecond个请求
* 还包含一个热身期(warmup period),热身期内,RateLimiter会平滑的将其释放令牌的速率加大,直到起达到最大速率
* 同样,如果RateLimiter在热身期没有足够的请求(unused),则起速率会逐渐降低到冷却状态
*
* 设计这个的意图是为了满足那种资源提供方需要热身时间,而不是每次访问都能提供稳定速率的服务的情况(比如带缓存服务,需要定期刷新缓存的)
* 参数warmupPeriod和unit决定了其从冷却状态到达最大速率的时间
*/
public static RateLimiter create(double permitsPerSecond, long warmupPeriod, TimeUnit unit);
同时还提供了两个获取令牌的方法,不带参数表示获取一个令牌.如果没有令牌则一直等待,返回等待的时间(单位为秒),没有被限流则直接返回0.0:
public double acquire();
public double acquire(int permits);
尝试获取令牌,分为待超时时间和不带超时时间两种:
public boolean tryAcquire();
//尝试获取permits个令牌,立即返回
public boolean tryAcquire(int permits);
//在timeout时间内一直去尝试获取一个令牌
public boolean tryAcquire(long timeout, TimeUnit unit);
//尝试获取permits个令牌,带超时时间
public boolean tryAcquire(int permits, long timeout, TimeUnit unit);
RateLimiter的主要功能就是提供一个稳定的速率,实现方式就是通过限制请求流入的速度,比如计算请求等待合适的时间阈值。当然关于RateLimiter更多且复杂的说明和用法本文便不再赘述,若感兴趣的小伙伴,可以自行百度一下。
4.3 临界问题
我们再来考虑一下临界问题的场景。在 0:59 秒的时候,由于桶内积满了 100 个 token,所以这 100 个请求可以瞬间通过。但是由于 token 是以较低的速率填充的,所以在 1:00 的时候,桶内的 token 数量不可能达到 100 个,那么此时不可能再有 100 个请求通过。所以令牌桶算法可以很好地解决临界问题。虽然令牌桶算法允许突发速率,但是下一个突发速率必须要等桶内有足够的 token 后才能发生
5.计算阈值
在面试限流的基本回答里面,你已经主动提起了限流阈值难以确定。那么不出所料,面试官就会问你怎么确定阈值。又或者你使用了限流的不同案例,那么面试官也会问你限流的阈值是怎么确定的。总体上思路有四个:看服务的观测数据、压测、借鉴、手动计算。
如果你的公司都会有完善的监控机制,像这种:
如果没有,可以通过Skywalking接入链路跟踪,通过在请求中透传traceId,后端记录处理时间(如数据库查询、业务处理等),结合SkyWalking可视化界面定位耗时瓶颈

举个例子,你当前有个接口的QPS是1w,业务的高峰期的时候QPS是3WQPS,那么申请下游服务的限流阈值的时候就可以设置为3.5W÷机器实例数,如下游的业务有10台机器,那么限流阈值则可设置为3500QPS,注意:上游的接口是3W,还需要考虑转化率,即大概有多少流量能够走到下游这个接口,所以借鉴不是很准确,要想拿到相对靠谱的数据,只能靠压测,即便不能做全链路压测,也可以考虑模拟线上环境进行压测,再差也应该在测试环境做一个压力测试。
如果你们公司既没有可以借鉴的渠道,也没有压测,当然这个不可能,自己都可以使用JMeter针对部分场景手动测一下,如果实在没条件,就只能手动计算
举一个最简单的例子,假如说一个非常简单的服务,整个链路只有一次数据库查询,这是一个会回表的数据库查询,根据公司的平均数据这一次查询会耗时 10ms,那么再增加 10 ms 作为 CPU 计算耗时。也就是说这一个接口预期的响应时间是 20ms。如果一个实例是 4 核,那么就可以简单用 1000ms÷20ms×4=200 得到阈值
手动计算准确度是非常差的。比如说垃圾回收类型语言,还要刨除垃圾回收的开销,相当于 200 打个折扣。折扣多大又取决于你的垃圾回收频率和消耗。
并根据你们的业务是否允许瞬时流量,来选择不同的限流算法,像漏桶算法就不允许瞬时流量,只能根据固定频率消费,而滑动窗口或者令牌桶均可以接受一定程度的瞬时流程
6.总结
6.1 计数器 VS 滑动窗口
计数器算法是最简单的算法,可以看成是滑动窗口的低精度实现。滑动窗口由于需要存储多份的计数器(每一个格子存一份),所以滑动窗口在实现上需要更多的存储空间。也就是说,如果滑动窗口的精度越高,需要的存储空间就越大。
6.2 漏桶算法 VS 令牌桶算法
漏桶算法和令牌桶算法最明显的区别是令牌桶算法允许流量一定程度的突发。因为默认的令牌桶算法,取走 token 是不需要耗费时间的,也就是说,假设桶内有 100 个 token 时,那么可以瞬间允许 100 个请求通过。
令牌桶算法由于实现简单,且允许某些流量的突发,对用户友好,所以被业界采用地较多。当然我们需要具体情况具体分析,只有最合适的算法,没有最优的算法。
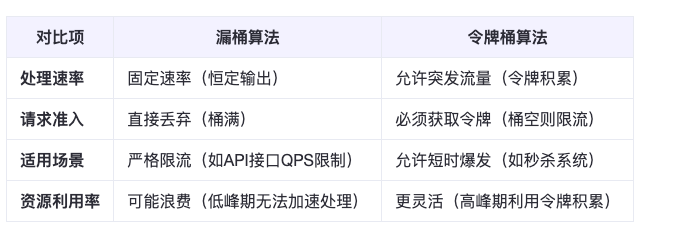
通俗类比:
- 漏桶:像“机器每秒只能做1杯奶茶”,无论多少人下单,只能匀速处理。
- 令牌桶:像“机器每秒放1个令牌”,用户拿令牌才能下单,空闲时令牌可积累,允许短时爆发。



















 85万+
85万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











