



此处为本章学习视频连接:
内容出处:若泽数据 http://www.ruozedata.com/
有一起学习的也可以联系下我QQ:2032677340
链接:https://pan.baidu.com/s/1_sBNxfOCp0RdZC3hoGUWuQ
提取码:0css
一、上次课回顾
- https://mp.youkuaiyun.com/mdeditor/90575957#
面试题:
1、RDD是什么?为什么是分布式?为什么是弹性?
谈一下你对RDD的理解?根据官方源码来理解==>RDDSCALA
RDD五大特性跟源码中那些方法对应。
RDD是一个抽象类,它是没有办法直接使用,只能通过子类访问;以JdbcRDD来看,通过Jdbc去访问数据,hadoopRDD:通过recordreader去获取hdfs上的split,一个文件先拿到split,进行key-value读取出来。
- 图解RDD要进行回顾
5~8min的口述内容准备。
二、SparkContext&SparkConf
The first thing a spark program must do is to create a SparkContext object ,
which tells spark how to access a cluster.
To create a SparkContext you first need to build a Sparkconf object
that contains information about your application
1)、常用的context有哪些?
ServletContext
StrutsContext
jbpmContext(工作流的上下文)
SpringContext ==> SpringBoot(构建rest服务使用springboot非常方便)
如何理解Context?
- context是一个框,也可以理解为它是一个容器,我们使用spark的时候首先就需要构建一个SparkContext。
2)、 SparkContext的作用:tells Spark how to access a cluster
如下这些都是通过SparkContext设置进去的:
local
standalone
yarn
mesos
3) 、the first thing a Spark program must do is to create a SparkContext objext,which tells Spark how to access a cluster, To create a sparkcontext you first need to build a SparkConf object information about your application.
- spark程序首先要创建一个SparkContext,它告诉了spark如何去连接集群;
- 创建SparkContext前首先要构建SparkConf对象(包含一些应用程序信息:application name、core、memory)。
4) 、官方对于SparkConf的描述:
- http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.SparkConf
4.1、Used to set various Spark parameters as key-value pairs (以键值对的方式)
4.2、you would create a SparkConf object with new SparkConf(), whcih will load values from any spark.* Java system properties set in your application as well. in this case, parameters you set directly on the SpakConf object take pripority over system properties.
- 使用SparkConf对象通过new SparkConf的方式,会去加载值从spark.*当中
4.3、All setter methods in this class support chaining(链式),eg:you can write 如下: new SparkConf().setMaster(“local”).setAppName(“My App”)
- 所有的set方法在这个类中都是支持链式的;new一个SparkConf之后可以设置很多东西,setMaster、setAppName
4.4、Only one SparkContext may be active per JVM. You must stop() the active SparkContext before creating a new one.
译:仅仅只有一个SparkContext在进程中是active状态的,如果我们要创建一个新的SparkContext的时候一定要先把旧的关掉。
val conf = new SparkConf().setAppName("appname").setMaster("master")
new Sparkcontext(conf)
能够运行我们的Spark使用线程的方式,local[2]:线程数量只要大于2就行了。

The appName parameter is a name for your application to show on the cluster UI. master is a Spark, Mesos or YARN cluster URL, or a special “local” string to run in local mode.
最佳实践:
- In practice, when running on a cluster, you will not want to hardcode(你不要在代码中采用硬编码的方式) master in the program, but rather launch the application with spark-submit and receive it there.(启动应用程序使用spark-submit的方法来使用) However, for local testing and unit tests, you can pass “local” to run Spark in-process.
意思是在代码中不要写一个local[2],而是应该在启动应用程序的时候使用spark-submit来指定local和master进行提交。
对于本地模式和单元测试来说,能够通过local模式来运行spark在一个进程里。
注意:
1):开发过程中不要在代码中写一个local[2],采用启动应用程序采用submit,在spark-submit中来指定master,对于本地测试或者单元测试,可以使用local模式。
2):在生产中,一定不要硬编码,而是通过spark-submit的方式把master提交上去;这样的话同一份代码可以跑在yarn、mesos、standalone这几个场景上且不用做代码的修改。
慕课网小伙伴问题:
- 开发过程使用local足够,怎样在本地写份代码设置master连接到standalone模式上去?连接不上去
三、使用idea创建Spark应用程序
可以参考如下博客:
- https://blog.youkuaiyun.com/zhikanjiani/article/details/90740153
-
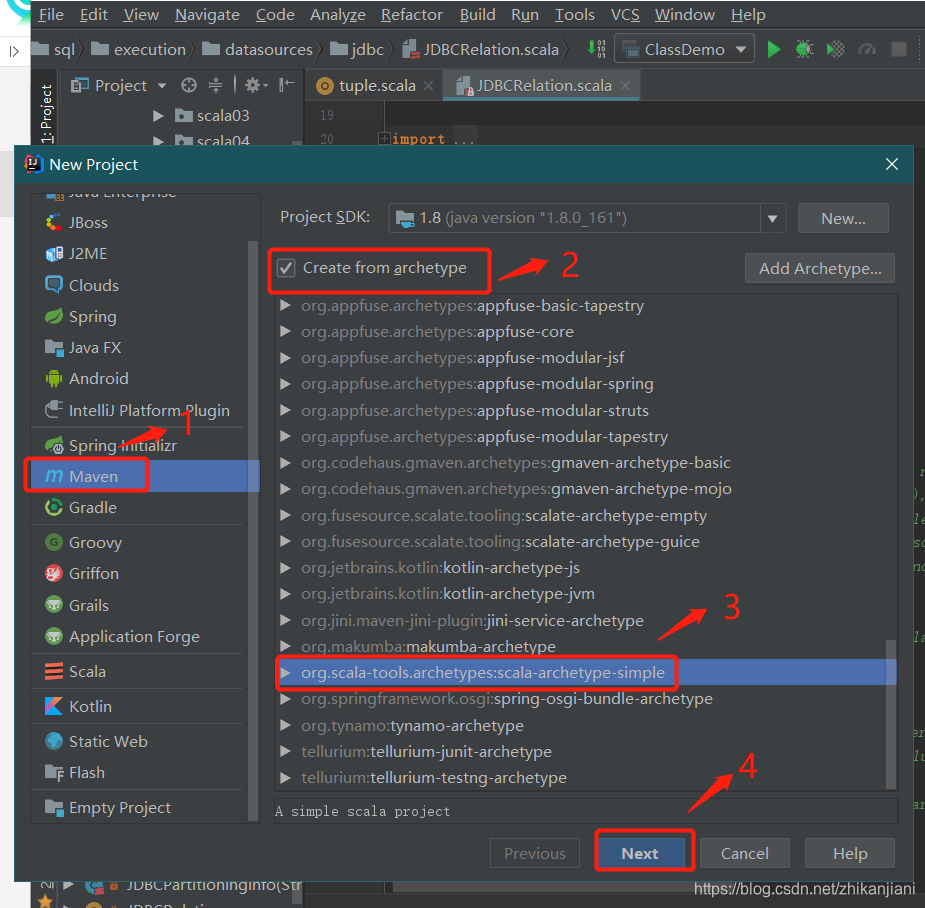
点击file->new->project,点击create from archetype;选择org.scala-tools.archetypes:scala-archetype-simple;
-
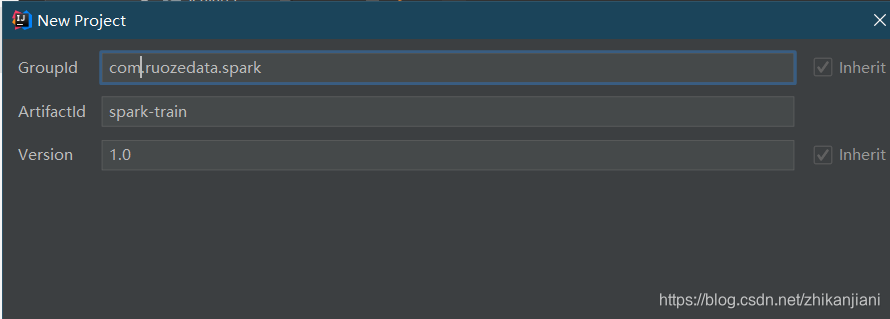
单机下一步GroupId:com.ruozedata.bigdata、ArtifactId:g6-spark;
-
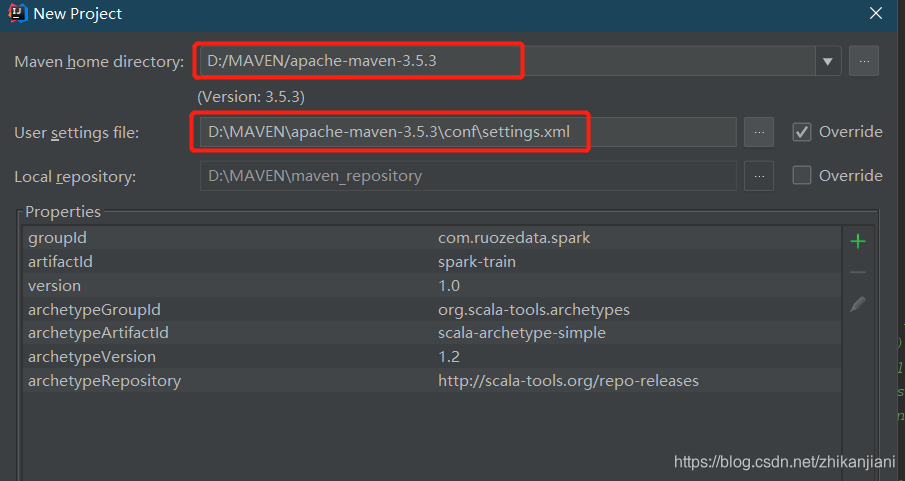
选定maven_home 目录、使用maven_home下的settings.xml、再选择local_repository(这个是settings.xml中加的自动识别出来的)。
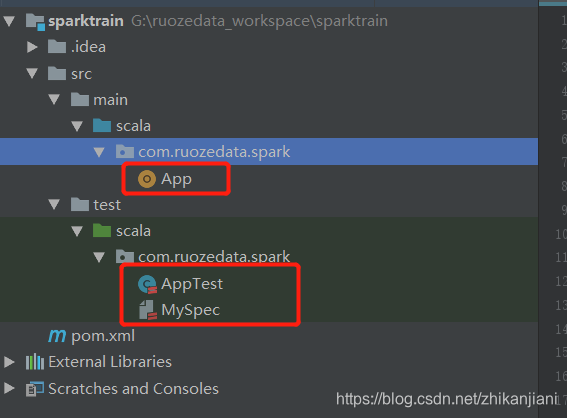
1、import changes导入常用包:删除不用的app、AppTest、MySpec
2、 删除不需要的junit和test依赖、点击enable-auto-import
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
3、 添加所需的spark-core依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.2</version>
</dependency>
4 、开始编码
package com.ruozedata.spark
import org.apache.spark.{SparkConf, SparkContext}
object SparkConfAPp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("appName").setMaster("Master")
//如上就是使用SparkConf的链式编程
val sc = new SparkContext() //Declaration is never used
//创建SparkContext之前首先要创建一个SparkConf
sc.stop()
//打开之后最好是要关掉
}
}
val conf = new SparkConf().setAppName(appName).setMaster(master)
new SparkContext(conf)
---------------------------------------------------------
appName parameter is a name for your application to show on the cluster UI.
master is a Spark,Mesos or YARN cluster URL
master URL:
local [2] 建议是大于1,Run Spark locally with K worker threads(ideally, set this to the number of cores on your machine)
扩充:HADOOP_CONF_DIR : /home/hadoop/app/hadoop/etc/hadoop
------------------------------------------------------------
in practise, when running on a cluster, you will not want to hardcode master in the program, but rather launch the application with spark-submit and receive it there. However, for local testing and unit tests, you can pass "local" to Run Spark in progress.
翻译:启动应用程序,使用spark-submit来提交,对于本地测试和单元测试,你要使用local模式来做测试,生产上一定不要硬编码。
总结:
1、初始化SparkContext,就必须先要new SparkConf,其实就两行:
object SparkConfApp{
def main(args: Array[String]){
val sparkconf = new SparkConf().setAppName("name").setMaster("local[2]")
val sc = SparkContext(sparkConf)
//TODO 业务逻辑代码
}
}
四、Spark-shell的使用
1、查看命令帮助
- 借助于./spark-shell --help
2、重要参数讲解:
2.1 --master ==> 不建议采用硬编码的方式指定master,要采用spark-submit的提交的时候指定master
2.2 --name ==> 指定application的名称的
2.3 --jars ==> 复数意味着能传入很多jar包 Comma-separated list of local jars to include on the driver and executor classpaths ==> 以逗号分隔的一系列的本地jar包
2.4 --conf PROP=VALUE Arbitrary Spark configuration property 指定配置的一些参数
2.5 --driver-memory
2.6 --executor-memory
2.7 --quene 生产上是以队列的方式来提交作业的,需要设置好
2.8 --executor-cores
spark-shell local[2]
spark-shell --master local[2]
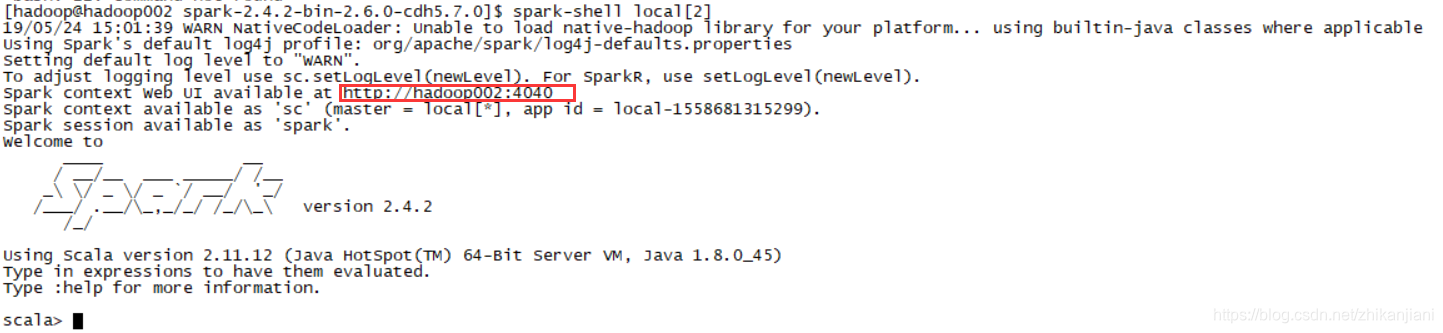
3)Spark context available as ‘sc’ (master = local[*], app id = local - 1558681315299)
Spark session available as ‘spark’
解释:
- 一个spark-shell就是一个应用程序,它创建了一个spark-context,他的别名是sc,它指向的master是local[2],它的id是 local - 15586813152。
- Environment(环境)
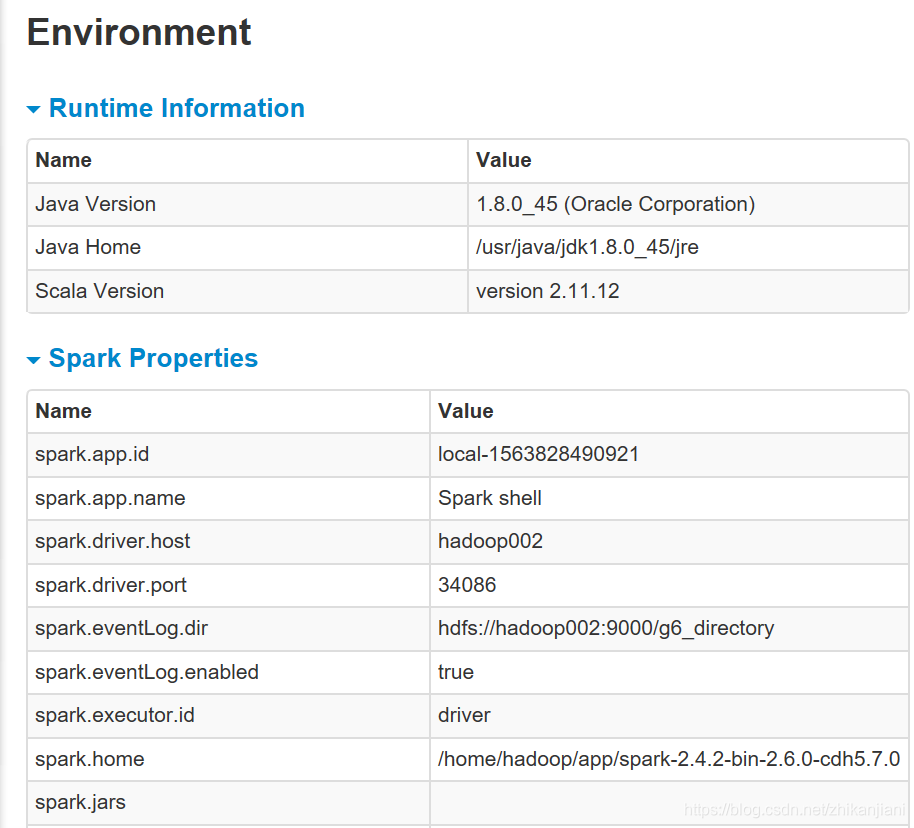
重要的调优点:
5)Classpath Entries(类路径条目):
它主要是在这两个目录下的信息:
$SPARK_HOME/conf/
$SPARK_HOME/jars/*.jar
spark1.X和spark2.X中jars目录下,spark1.x是打成一个包,spark2.X目录下是有很多jar包
生产调优点:如果是以spark on yarn的模式运行,这些包每次都要上传对于作业开销是非常大的
For a complete list of options, run spark-shell --help. Behind the scenes, spark-shell invokes(调用) the more general spark-submit script.
总结:
进行RDD的操作前必须构建SparkContext,构建SparkContext前要先构建SparkConf,直接通过spark-shell的方式创建一个应用程序,应用程序默认给我们创建了SparkContext,它的别名是sc。
本次课程作业:
作业题目1:4040UI界面上,Spark shell application UI在源码中的来源???
https://github.com/apache/spark/blob/master/bin/spark-shell
我们通过spark-shell脚本,我们可以发现spark-shell的由来,底层也是调用spark-submit进行作业的提交的。
function main() {
"${SPARK_HOME}"/bin/spark-submit --class org.apache.spark.repl.Main --name "Spark shell" "$@"
stty icanon echo > /dev/null 2>&1
else
export SPARK_SUBMIT_OPTS
"${SPARK_HOME}"/bin/spark-submit --class org.apache.spark.repl.Main --name "Spark shell" "$@"
fi
}
UI界面上的Environment:
作业题目2:spark.app.id local-1563828490921 的来源
作业题目3:为什么spark.app.name = Spark-shell ?
作业题目4:Name:java.io.tmpdir Value:/tmp,参数调整,linux目录下定期对/tmp目录删除
- 原因是linux会定期对/tmp目录进行清理.
作业题目5:在spark-shell中,如果你自己再构建一个SparkContext,它是不能工作的?
- 自行测试
作业题目6:shell脚本中 @ 和 @和 @和#的区别?
[hadoop@hadoop002 data]$ cat test.sh
#!/bin/bash
echo $# //参数个数
echo $@ //输入的所有参数
[hadoop@hadoop002 data]$ sh test.sh john ron fox
3
john ron fox

















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









