




目录
一 模板产生的原因
C语言中针对各种类型,即使是实现相同的功能,也要写很多个函数
C++可以用函数的重载来实现,一个但是如果又引入了其他类型,又要去增加对应的重载函数。这个过程很繁琐,无休无止。
这种大量重复的实现本质上是一个共同的函数功能。
这种情况,我们就可以采用泛型编程。对应的用模板实现。可以理解成活字印刷术。
二 模板使用
分类:函数模板和类模板。
由于模板一般被分成函数模板和类模板,所以分别从函数模板和类模板的角度来讲解模板
1 函数模板
Template<>与函数参数类似。但是模板参数对应的是类型 typename T(T是type的缩写)。当然我们可以随便取名字比如Ty K Val……赋予其他的意义。一般没有特殊意义就用T。但是不管怎样,对模板参数取得名字一般是大写字母或者单词首字母大写,代表的是一个模板类型(虚拟类型)。
typename和class基本上是没有区别的,也就是说目前,我们既可以使用template<class T> 也可以使用template<typename T>.
如何实现函数模板?函数在前,模板在后。函数的参数类型不是一个具体的类型,而是一个模板类型。但是其他不受影响。代码该怎样写依然是怎样写的。
使用
#include<iostream>
template<typename T>
void Swap(T& left, T& right)
{
T tmp = left;
left = right;
right = tmp;
}
int main()
{
char c1 = 'a';
char c2 = 'b';
Swap(c1, c2);
std::cout << c1 << c2;
int n1 = 1;
int n2 = 2;
Swap(n1, n2);
std::cout << n1 << n2;
double d1 = 1.1;
double d2 = 2.2;
Swap(d1, d2);
std::cout << d1 << d2;
return 0;
}
注意,由于swap在标准库中已经有对应的实现了,所以我们这里如果自己用模板来实现的话,需要命名不同来区分。

说句题外话,以后我们使用swap直接去调用标准库中的就行了。 他是std中的一个对应的函数,不需要包含头文件。
泛型编程可以用亦或改写swap吗
不行。因为亦或的特性是针对int的。T的话是任何类型。虽然亦或的效率比较高,但是实际上编译器并不在意这一点点的效率问题。
函数模板是如何实现的呢?
要经过参数推演和实例化。
参数的推演:推导函数模板参数的类型。比如实参是两个double,那么T对应推导也是两个double。会把这个函数的模板参数去掉,生成一个两个double。如果是int和char的话,也是差不多的。
实例化:需要针对推演的参数进行实例化。用函数模板生成具有具体参数的函数。比如如果是swap推演出了实参类型是两个double,那么实例化生成的函数就是交换两个double的swap函数。
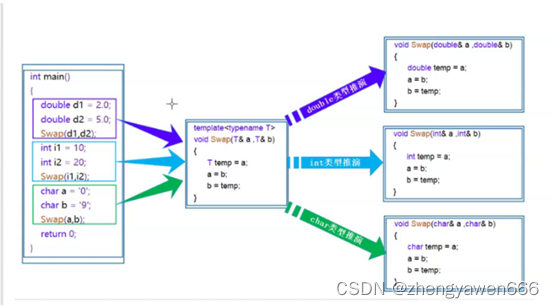
我们只需要写一个模板,那么多种类型的对象都能生成了。大大减少了工作量。
本质:把我们需要做的事情,交给编译器去做了。
这个函数实际上还是多个函数,只不过把这个过程交给了编译器来做,但是编译器需要去推演参数和实例化,让编译器编译的过程更复杂了,时间更长了。
实例化之后,函数调用的地址是不一样的,编译器看到的是三个函数。
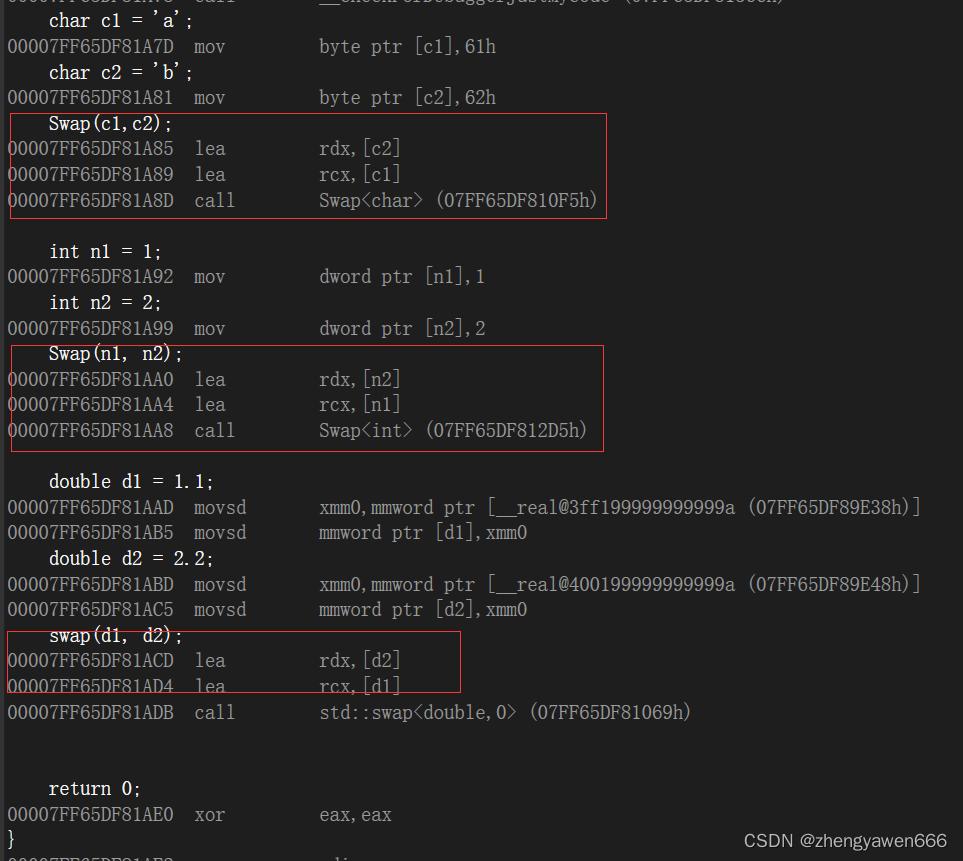
函数模板实现的时候,调用的不是同一个函数。针对不同类型的函数实现,调用不同的函数。并且三个函数的指令是不一样的,他们建立的栈帧都是不一样的。
函数模板的传参问题
如果一个传入double类型,一个传入int类型,模板参数不明确,该怎么办呢?
隐式实例化
#include<iostream>
using namespace std;
template<typename T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int n1 = 1;
int n2 = 2;
double d1 = 1.1;
double d2 = 2.2;
cout << Add((double)n1, d1) << endl;//2.1
cout << Add(n1, (int)d1) << endl;//2
return 0;
}以实现Add为例,注意传参要加const。因为实参传递给形参,会进行拷贝,将拷贝的临时变量传递给形参,但是临时变量具有常性,如果不加const的话,编译就无法通过。
模板不能饮食类型转换,所以如果分别传入两个不同类型的参数,那么他们在传参之前就已经报错了,在推演实例化的时候报错的。无法根据不同的类型推演出来,推演冲突。
这是通过编译器来进行的自动推演,所以是隐式实例化。
显示实例化
cout << Add<int>(n1, d1) << endl;//2
cout << Add<double>(n1, d1) << endl;//2.1这种不由编译器推演,直接指定T是int类型,让编译器去推导int类型的,这种就是显示实例化。
这种应用场景很多。比如类模板的显示实例化,或者有些函数必须要显示实例化才能使用。不显示实例化,没办法自动推演出对应的类型。不知道new的类型是啥。
另外一种解决方案:指定两个模板参数,这样就不会推演矛盾了。但是随之产生的问题-》返回值是什么类型的呢?
整形提升成double,之后你改成了int,编译器会报错,有时候会产生意想不到的结果。
关于调用顺序问题
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
template<typename T>
T Add(const T& left, const T& right)
{
return left + right;
}
int Add(int left, int right)
{
return left + right;
}
template<typename T1,typename T2>
T1 Add(const T1& left, const T2& right)
{
return left + right;
}
int main()
{
Add(1, 1);
Add(1.1, 1);
return 0;
}如果同时存在,那么调用的时候如何走?编译器先去看有没有参数匹配,有没有参数是int的,如果有直接调用了,如果没有的话,会先进行实例化才行了。原则:函数和模板是可以同时存在的。但是如果直接有函数匹配,直接用函数;如果没有的话,会用模板进行推演之后再进行实例化。因为编译器认为去推演还有开销,直接用现成的更好。
但是对于模板参数相同和不同的,调用哪个呢?一般情况下是第一个,机制更简单。
但是如果传入的参数不同,才会去调用第二个。但是这种模板实现Add设计的其实特别不好,最好不要这样写。他们只有参数和返回值类型不同。我们上述只是为了说明现象故意写成这样的。
2 类模板
为什么会有类模板呢?他解决了什么我们之前解决不了的问题呢?Typedef为什么不能叫做泛型编程呢?
我们之前使用的typedef已经不起作用了,必须再定义一个存储其他类型的类,并且他们的名字还需要进行区分,使用非常的繁琐。语法取巧,让更换类型更方便了,他解决不了两个栈存不同的数据类型的问题。
C语言无法实现数据结构的库,因为无法解决类似如果一个栈存储int,另一个栈存储double这样,栈存储不同数据类型的问题,而只有模板才能很好地解决这个问题。
如果stack一个存int 一个存double,怎么声明呢?
函数模板调用不指定参数类型,还能在调用的时候,通过传参来推演。但是类模板如果没有传入的话,就无法推演了。
因此类模板一般都是显示实例化。
Stack<int> st1;
Stack<double> st2;虽然用一个类模板实例化出来,但是并不是一个类型。
注意:类模板不支持分离编译-》声明放在.h 定义放在.cpp否则编译会报错。有些地方会把模板改名字.hpp。他从名字上就告诉你,该文件不止有模板对应的声明,还有对应的实现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









