




〇、前言
Kubernetes,将中间八个字母用数字 8 替换掉简称 k8s,是一个开源的容器集群管理系统,由谷歌开发并维护。它为跨主机的容器化应用提供资源调度、服务发现、高可用管理和弹性伸缩等功能。
下面简单列一下 k8s 的几个特性:
- 自动化部署(调度):Kubernetes 可以根据应用程序计算资源需求自动分配到 node。
- 服务发现和负载均衡:Kubernetes 可以利用 DNS 名称或自己的 IP 地址暴露容器,如果到一个容器的流量过大,Kubernetes 能够负载均衡和分发网络流量,以保证部署稳定。
- 【水平伸缩】:即自动化容器扩容和缩容。根据 CPU 使用情况或其他选择的度量标准,Kubernetes 可以自动扩展或缩小运行的容器数量。
- 【自我修复】:当一个容器失败时,Kubernetes 会重新启动它;当节点失败时,它会替换和重新调度容器;当容器没有通过用户定义的健康检查时,它会杀死它。只有当容器准备好服务时,才会将其视为可用。
- 密钥和配置管理:Kubernetes Secrets 可以用来存储和管理敏感信息,如密码、OAuth 令牌和 SSH 密钥等。而 Kubernetes ConfigMaps 则可以用来存储和管理配置信息,如 Prometheus 配置文件、数据库连接字符串等。
一、关于 k8s 的一些概念解释
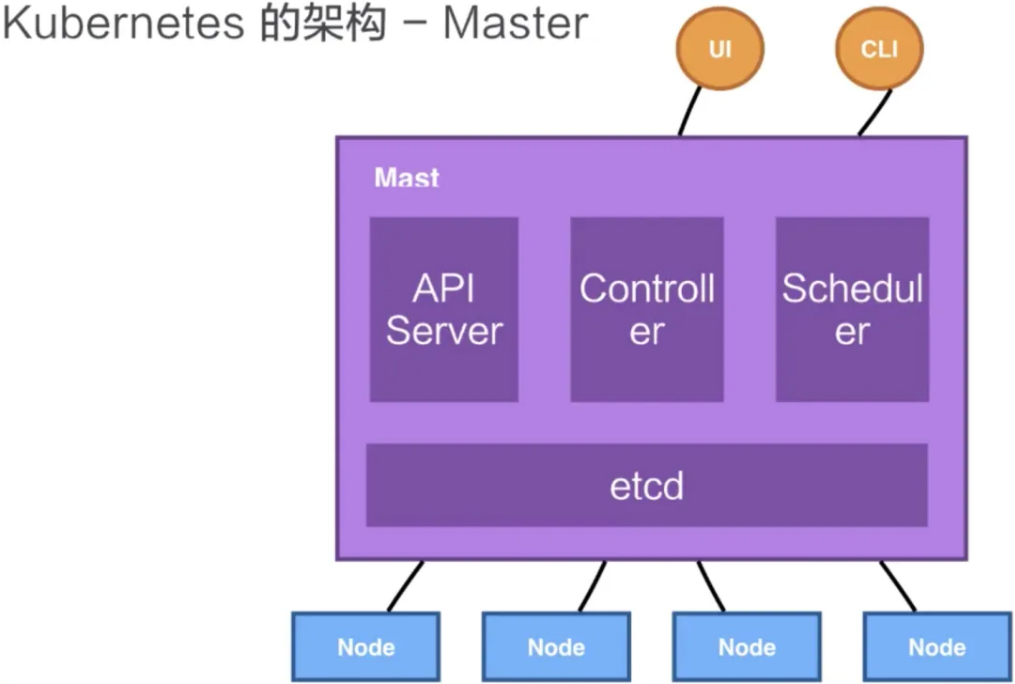
1.1 Master 主节点
k8s 里的 Master 指的是集群控制节点,每一个 k8s 集群里都必须要有一个 Master 节点,来负责整个集群的管理和控制,基本上 k8s 的所有控制命令都发给它,它来负责具体的执行过程。
通常,Master 部署在一个独立的服务器上,若想达到高可用性部署,建议用 2~3 台服务器,Master 也可以扩展副本数,来获取更好的可用性和冗余。它是整个集群的“首脑 brain”,如果宕机或者不可用,那么对集群内容器应用的管理都将失效。
Master 节点上运行着以下四个关键进程:
- APIServer(kube-apiserver):k8s 提供了 HTTP Rest 接口的关键服务进程,是 k8s 里所有资源的增、删、改、查等操作的唯一入口,也是集群控制的入口进程。所有的组件都会和 API Server 进行连接,组件与组件之间一般不进行独立的连接。
- Controller(kube-controller-manager):控制器,k8s 里所有资源对象的自动化控制中心,可以理解为资源对象的“大总管”。比如这两个核心特性,水平伸缩、自我修复都是由 Controller 管理的。另外还有一种是云控制器管理器(cloud-controller-manager),是第三方云平台提供的控制器 API 对接管理功能。
- Scheduler(kube-scheduler):调度器,负责资源调度(Pod 调度)的进程,安排哪些服务的 Pod 运行在哪些节点上。
- etcd:是一个键值类型存储的分布式的一个存储系统,提供了基于 Raft 算法实现的自主的集群高可用性。APIServer 中所需要的这些原信息都被放置在 etcd 中,etcd 本身是一个高可用系统,通过 etcd 保证整个 k8s 的 Master 组件的高可用性。
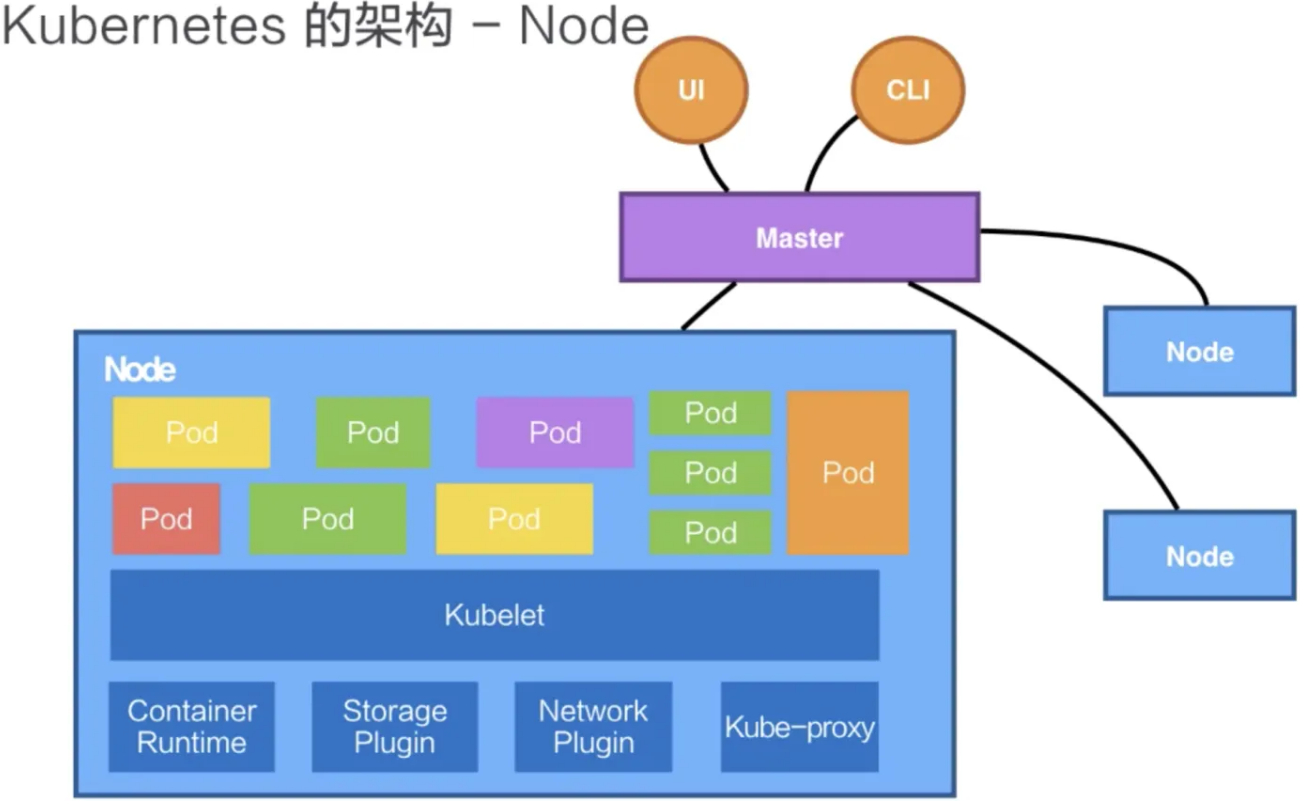
1.2 Node 子节点
除了 Master,k8s 集群中的其他机器被称为 Node 节点,Node 是真正运行业务负载的,每个业务负载会以 Pod 的形式运行。
与 Master 一样,Node 节点可以是一台物理主机或者是虚拟机。Node 节点才是 k8s 集群中的工作负载节点,每个 Node 都会被 Master 分配一些应用程序服务以及云工作流,在有些时候,Master 节点上也会“安排”一些服务运行,或者说是一些 Docker 容器,当某个 Node 宕机时,其上的工作负载会被 Master 自动转移到其他节点上去(自我修复)。
每个 Node 节点上都运行着以下一组关键进程:
- kubelet:负责 Pod 对应的容器的创建、启停等生命周期任务,以及存储和网络等,同时与 Master 节点密切协作,实现集群管理的基本功能。
- kube-proxy:实现 k8s 中 Service 的服务发现与负载均衡机制的重要组件。
- Container-Runtime:容器运行时环境。最常用的运行时就是:DockerEngine(docker),Docker 引擎,负责本机的容器创建和管理工作。其他还有 containerd、CRI-O。
Node 节点可以在运行期间动态增加到 k8s 集群中,前提是这个节点上已经正确安装、配置和启动了上述关键进程。
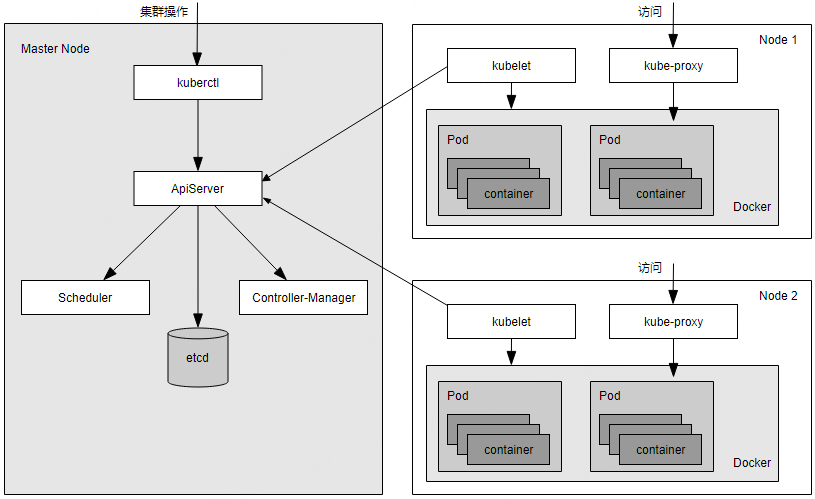
在默认情况下,kubelet 会向 Master 注册自己,这也是 k8s 推荐的 Node 管理方式。
一旦 Node 被纳入集群管理范围,kubelet 进程就会定时向 Master 节点汇报自身的情报。例如操作系统、Docker 版本、机器的 CPU 和内存情况,以及当前有哪些 Pod 在运行等,这样 Master 可以获知每个 Node 的资源使用情况,并实现高效均衡等资源调度策略。
而某个 Node 超过指定时间不上报信息时,会被 Master 判断为“失联”,Node 的状态被标记为不可用(Not Ready),随后 Master 会触发“工作负载大转移”的自动流程。
kubect 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4573
4573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









