




 本文详细介绍SpringBoot与ElasticSearch的整合过程,包括配置、文档定义、索引操作及Mysql与Elasticsearch的数据同步策略,适用于快速搭建全文检索系统。
本文详细介绍SpringBoot与ElasticSearch的整合过程,包括配置、文档定义、索引操作及Mysql与Elasticsearch的数据同步策略,适用于快速搭建全文检索系统。
1.springboot和ElasticSearch的整合
server:
port: 9007
spring:
application:
name: tensquare‐search #指定服务名
data:
elasticsearch:
cluster‐nodes: 127.0.0.1:9300
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import java.io.Serializable;
//文档是索引库中的最小单位,相当于表中的一行,记录 两个参数
/**
* 其中的indexName 相当于索引库,相当于数据库,type相当于数据库中的表
*/
@Document(indexName = "tensquare_article",type = "article")
public class Article implements Serializable{
@Id
private String id;
//其中的域表示的是表中的一列的意思
//是否索引 就是看该域是否能否被搜索到
//是否分词,表示该搜索的时候是整体匹配还是单词匹配
//是否存储,就是是否在页面上显示
其中的index 表示是否分词 ,analyzer
@Field(index = true,analyzer = “ik_max_word”,searchAnalyzer = “ik_max_word”)
private String title;
@Field(index = true,analyzer = "ik_max_word",searchAnalyzer = "ik_max_word")
private String content;
private String State;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getState() {
return State;
}
public void setState(String state) {
State = state;
}
}
重点:
//是否索引 就是看该域是否能否被搜索到 //是否分词,表示该搜索的时候是整体匹配还是单词匹配 //是否存储,就是是否在页面上显示
具体的 @Document @Field 的操作 ,解释还的看
https://blog.youkuaiyun.com/qq_28364999/article/details/81109666
@Documnet 注解
public @interface Document {
String indexName(); //索引库的名称,个人建议以项目的名称命名
String type() default ""; //类型,个人建议以实体的名称命名
short shards() default 5; //默认分区数
short replicas() default 1; //每个分区默认的备份数
String refreshInterval() default "1s"; //刷新间隔
String indexStoreType() default "fs"; //索引文件存储类型
}
@Field注解
public @interface Field {
FieldType type() default FieldType.Auto; //自动检测属性的类型,可以根据实际情况自己设置
FieldIndex index() default FieldIndex.analyzed; //默认情况下分词,一般默认分词就好,除非这个字段你确定查询时不会用到
DateFormat format() default DateFormat.none; //时间类型的格式化
String pattern() default "";
boolean store() default false; //默认情况下不存储原文
String searchAnalyzer() default ""; //指定字段搜索时使用的分词器
String indexAnalyzer() default ""; //指定字段建立索引时指定的分词器
String[] ignoreFields() default {}; //如果某个字段需要被忽略
boolean includeInParent() default false
}
3.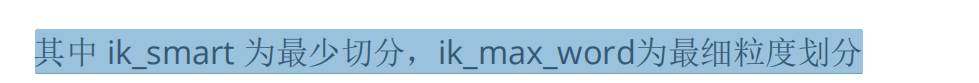
4.建立索引 ElasticsearchRepsitory<Article,String>

5.实现EleasticSearch 和 Mysql 数据库的同步操作:

6.MysqL和 Elasticsearch 之间可以通过一张配置文件,进行两者的配置
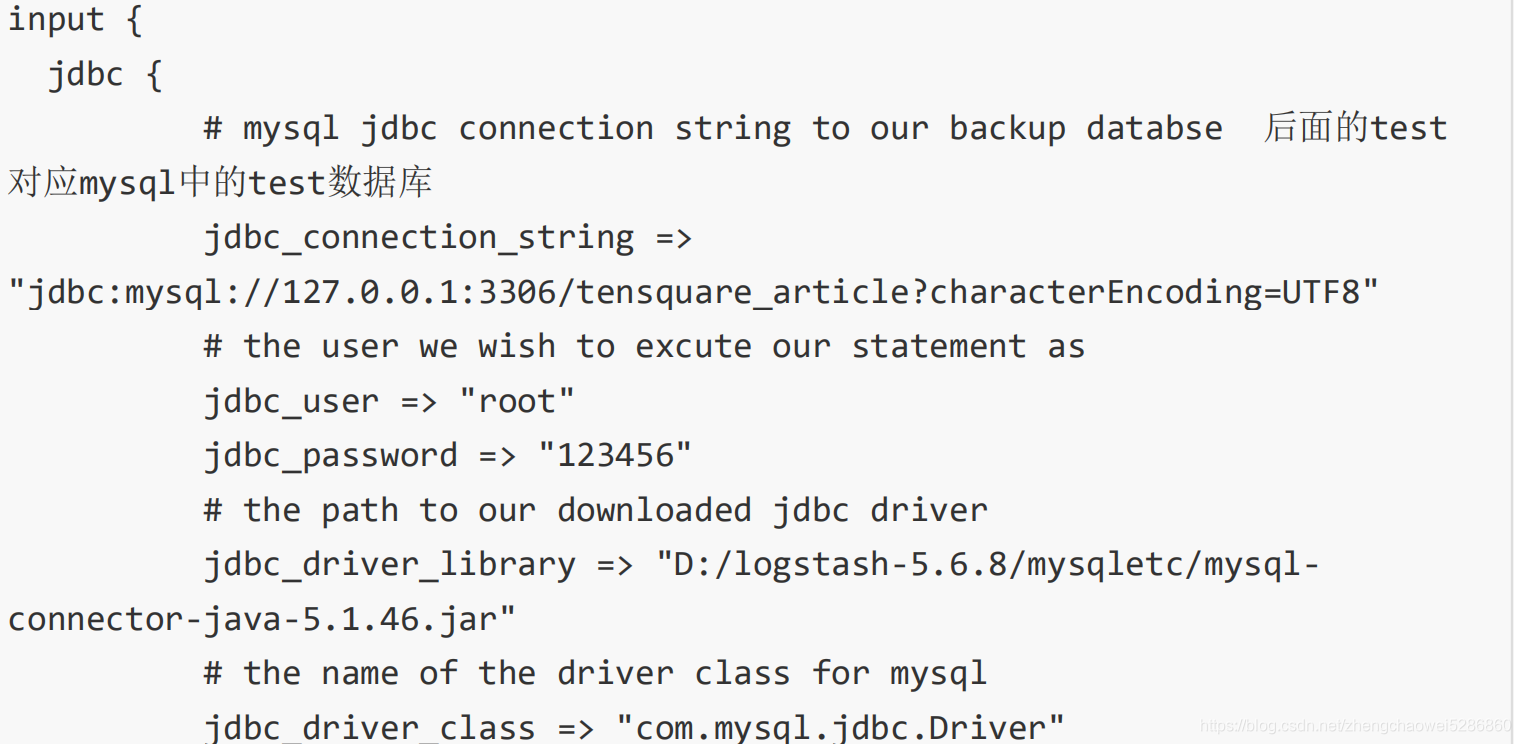

从mysql 中取得数据到Elasticsearch输出
两者之间的关系,


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









