





PostgreSQL能设计出利用多CPU让查询更快的查询计划。这种特性被称为并行查询。对于那些可以从并行查询获益的查询来说,并行查询带来的速度提升是显著的。很多查询在使用并行查询时比之前快了超过两倍,有些查询是以前的四倍甚至更多的倍数。那些访问大量数据但只返回其中少数行给用户的查询最能从并行查询中获益。
| 视频讲解如下 |
|---|
|
【赵渝强老师】PostgreSQL的并行查询 |
一、 并行查询如何工作
PostgreSQL的并行化包含三个重要组件:进程本身(Leader进程)、Gather、Workers。没有开启并行化的时候,进程自身处理所有的数据;一旦计划器决定某个查询或查询中部分可以使用并行的时候,就会在查询的并行化部分添加一个Gather节点,将Gather节点作为子查询树的根节点,并根据并行查询的参数设置创建相应的Worker节点;最终由Worker节点执行相应的并行查询功能。PostgreSQL并行查询的工作原理如下图所示。
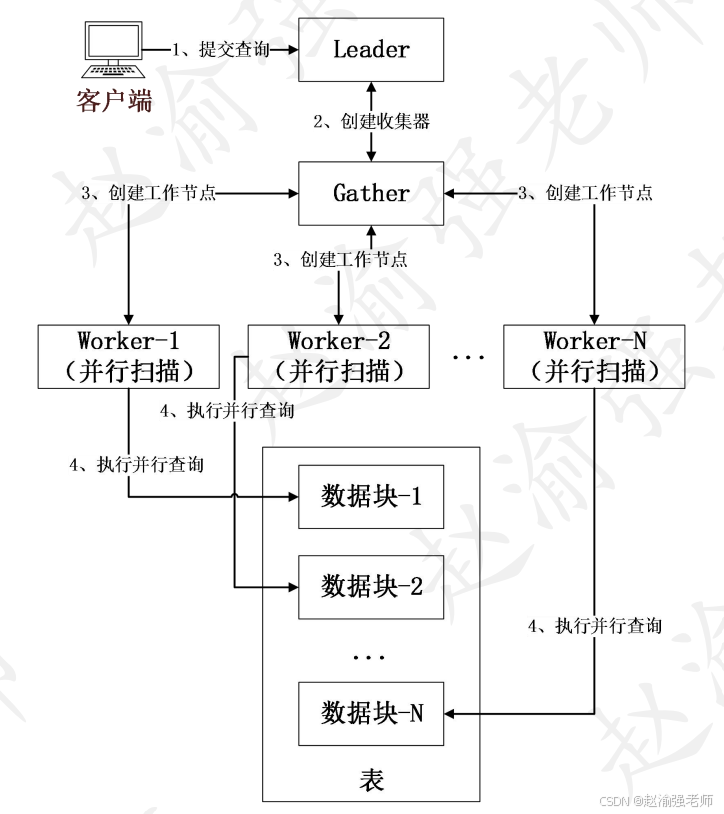
查询执行是从Leader进程开始。一旦开启了并行或查询中部分支持并行,就会分配一个gather节点和多个Worker线程。相关联的Blocks在各个Worker线程之间划分。Worker的数量受PostgreSQL的配置参数控制。Worker之间使用共享内存相互协调和通信,一旦Worker完成了自己的工作,结果就被传给了Leader进程。

二、 何时会用到并行查询?
要了解并行查询之前,首先介绍一下顺序扫描。下面通过一个例子来说明。
(1)创建一张表并插入数据,执行一个简单的查询,并输出执行计划。
mydemodb=# create table testtable1(tid int,tname varchar(20));
mydemodb=# insert into testtable1 values(0,'aaaa');
mydemodb=# explain select * from testtable1;
# 输出的信息如下:
QUERY PLAN
---------------------------------------------------------------
Seq Scan on testtable1 (cost=0.00..22.70 rows=1270 width=36)
(1 row)
# 这里的Seq Scan表示顺序扫描。
(2)现在往表中插入5千万条数据。
mydemodb=# insert into testtable1 select n,'myname_'||n
from generate_series(1,50000000) n;
(3)执行下面的查询,并输出执行计划
mydemodb=# explain analyze
select * from testtable1
where tname ='myname_10';
# 输出的信息如下:
QUERY PLAN
-------------------------------------------------------------------
Gather (cost=1000.00..687114.39 rows=1 width=19)
(actual time=0.224..1884.530 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on testtable1(cost=0.00..686114.29 rows=1 width=19)
(actual time=2370.242..4742.404 rows=0 loops=2)
Filter: (tname = 'myname_10'::text)
Rows Removed by Filter: 25000000
Planning Time: 0.051 ms
Execution Time: 1884.549 ms
其中:
(*)Workers Planned: 2 表示执行查询预估的并行进程数
(*)Workers Launched: 2表示实际启动的并行进程数
(*)Parallel Seq Scan on testtable1表示对表进行了并行的顺序扫描
(4)关闭并行查询,并重新生成上面的执行计划。
mydemodb=# set max_parallel_workers_per_gather = 0;
mydemodb=# explain analyze select * from testtable1 where tname ='myname_10';
# 输出的信息如下:
QUERY PLAN
-----------------------------------------------------------------
Seq Scan on testtable1 (cost=0.00..943470.90 rows=1 width=19)
(actual time=0.028..3608.929 rows=1 loops=1)
Filter: (tname = 'myname_10'::text)
Rows Removed by Filter: 49999999
Planning Time: 0.215 ms
Execution Time: 3608.948 ms
# 从这里的测试可以得出结论:
# 开启了并行查询耗时1884毫秒;
# 关闭并行查询后,耗时3608毫秒。性能降低了一倍。
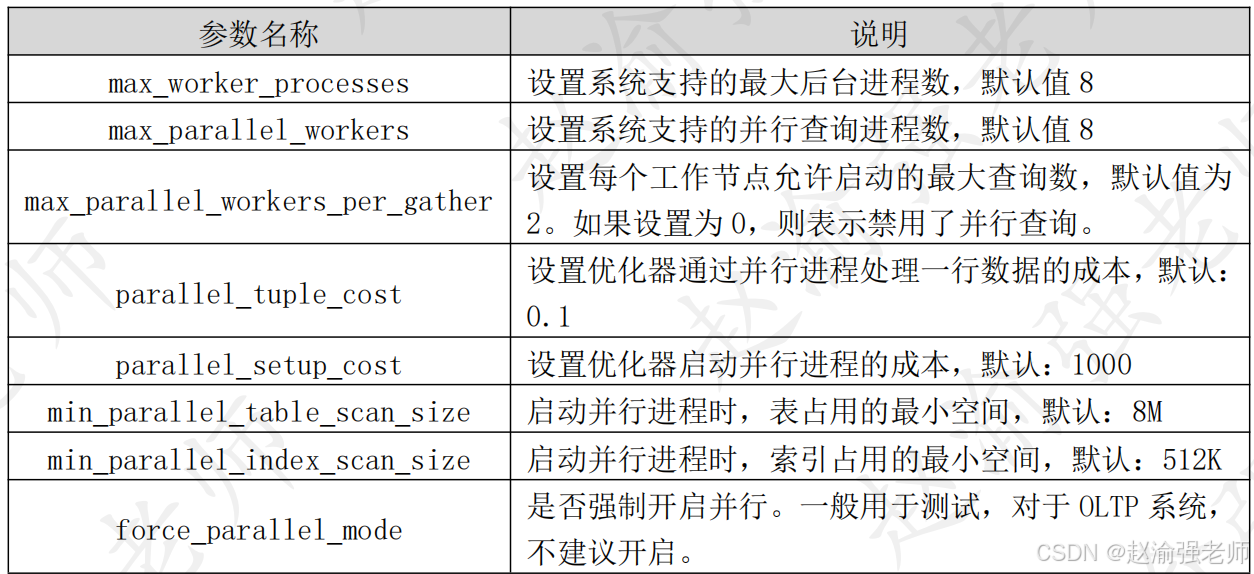
下表列举出了影响并行查询的相关参数及其含义。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











