






 本文介绍了如何使用Python进行简单的网页爬虫,以爬取指定网站的美女图片。通过分析网页结构,发现图片链接直接在HTML中,通过添加referer字段解决404问题。提供了一份仅23行的代码示例,适合初学者实践。
本文介绍了如何使用Python进行简单的网页爬虫,以爬取指定网站的美女图片。通过分析网页结构,发现图片链接直接在HTML中,通过添加referer字段解决404问题。提供了一份仅23行的代码示例,适合初学者实践。
爬取妹子图可能在爬虫里面没有什么技术含量了,新手练练手还是可以的。
今天爬取的网址是:http://www.youzi4.cc/mm/meinv/index_1.html
注意:爬取图片一般要加上referer,要不然就就出现,链接正确,总是返回<response 404>
1,分析网页
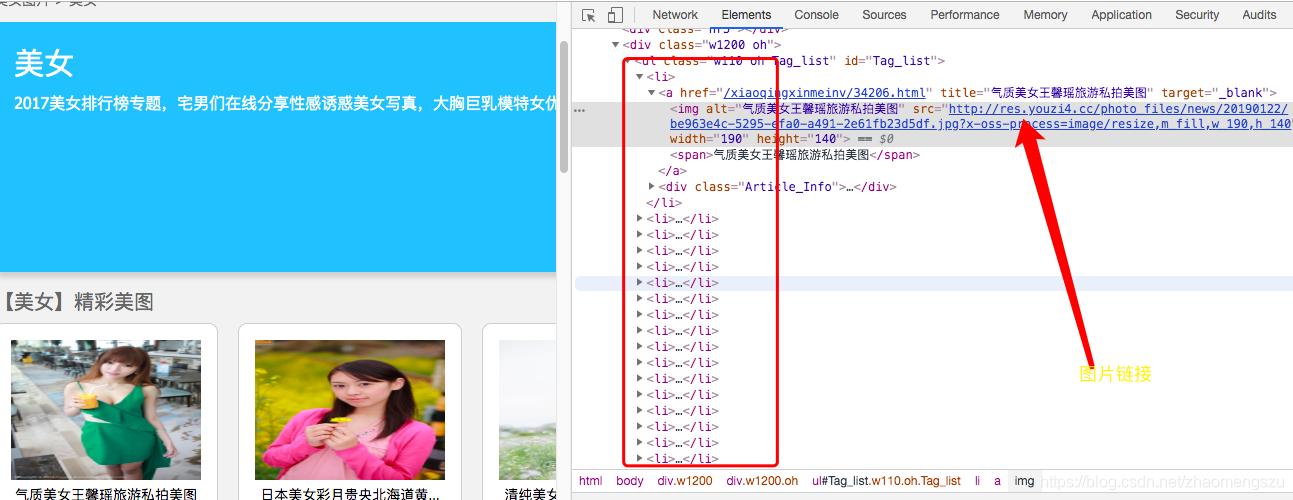
我们可以发现网页结构还是比较简单的,src链接就是图片的真实链接,那么我们就想办法获取了。
2,代码如下
from bs4 import BeautifulSoup
import requests
import re
num=1
content='http://www.youzi4.cc/mm/meinv/index_'
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
'Referer':'http://www.youzi4.cc/',
'Cookie':'BUSER=95b22bacda2b256ad16f4716a2cb9642; UM_distinctid=16a524cb1d670f-0c42da4818f7b-366d7e02-13c680-16a524cb1d73c7; Hm_lvt_a5380fe98a4f8ada8d996e42fd889959=1556158919; CNZZDATA1263076883=1951933051-1556159993-%7C1556159993; CNZZDATA1272874627=1426906288-1556156669-%7C1556172870; security_session_verify=f1e3941ff7da077d11d404a2e6d363dd; Hm_lpvt_a5380fe98a4f8ada8d996e42fd889959=1556175773',
}
max=2 #输入你想获取的页码数
for n in range(1, max):
url=content+str(n)+'.html'
webdata=requests.get(url,headers=headers).text
soup=BeautifulSoup(webdata,'lxml')
link=soup.select("img") #通过标签名查找
reg=r'src="(.*?)"'
imgre=re.compile(reg)
imglist=re.findall(imgre,str(link))
for imgurl in imglist:
pic=requests.get(imgurl,headers=headers).content
with open('/Users/zhaomeng/mv/'+str(num)+'.jpg','wb')as f:
f.write(pic)
num=num+1
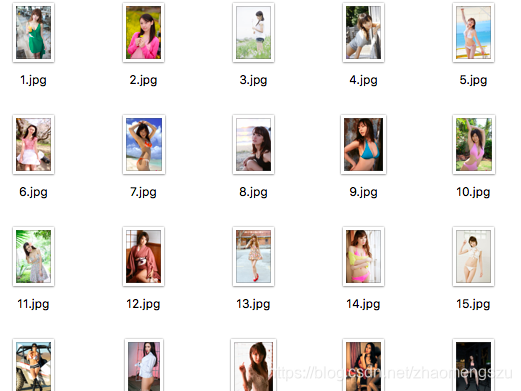
3,结果如下

















 3万+
3万+




 到【灌水乐园】发言
到【灌水乐园】发言







