






LangChain 中的 Retriever(检索器)
相关文章:
Python LangChain RAG从入门到项目实战10.:质量评价指标体系
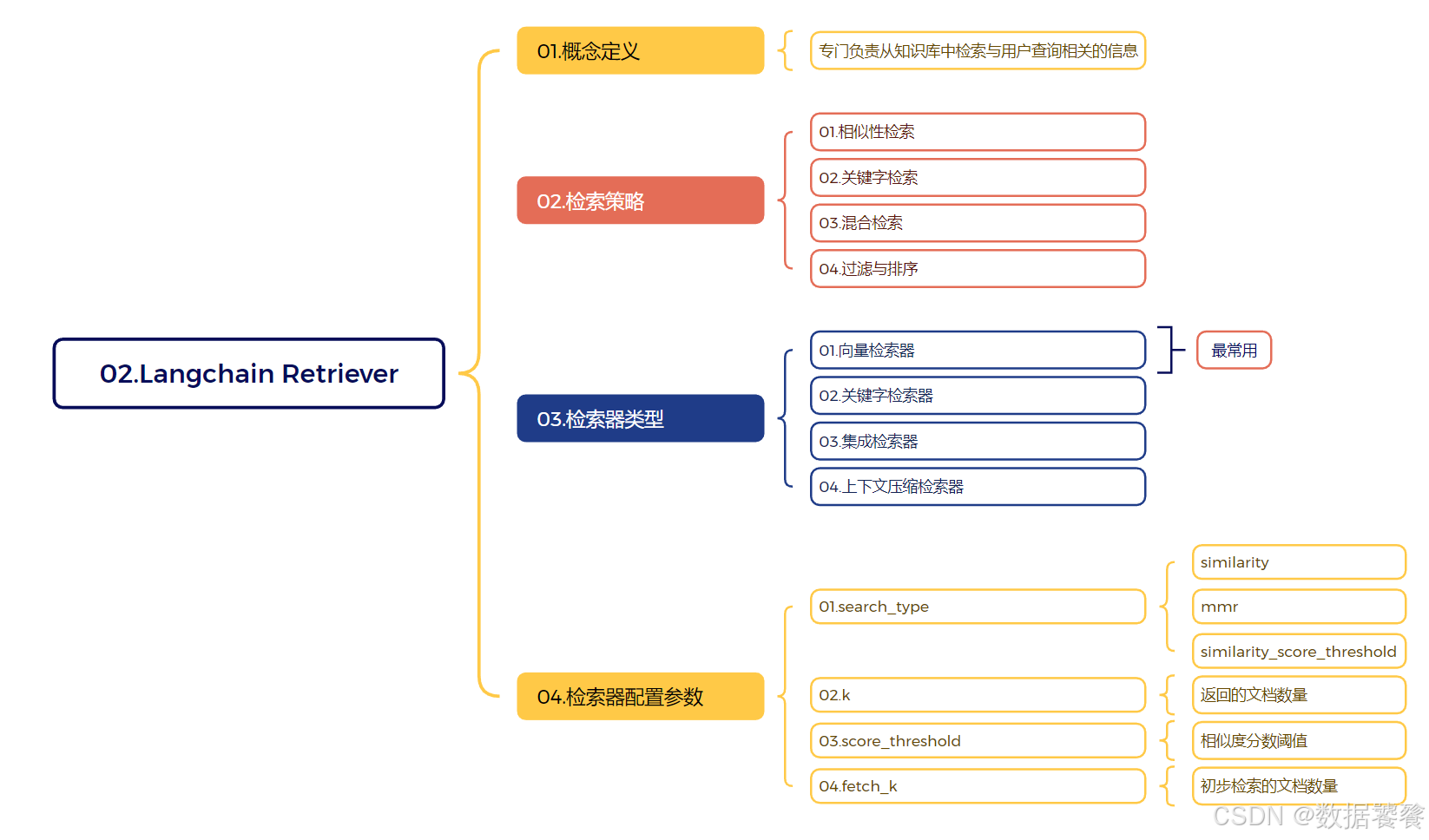
在 LangChain 中,Retriever(检索器) 是一个核心组件,专门负责从知识库中检索与用户查询相关的信息。它的主要作用是根据输入的问题或查询,从大量文档中找到最相关的片段,为后续的问答或生成任务提供上下文。
1.Retriever 的主要功能
- 相似性检索:基于语义相似度找到与查询最相关的文档片段
- 关键字检索:基于关键词匹配找到相关文档
- 混合检索:结合多种检索策略提高检索质量
- 过滤与排序:对检索结果进行筛选和排序,返回最相关的内容
2.Retriever 的工作原理
典型的 Retriever 工作流程:
- 接收用户查询/问题
- 将查询转换为向量表示(使用嵌入模型)
- 在向量数据库中搜索相似向量
- 返回最相关的文档片段
3.Retriever 的类型
LangChain 支持多种类型的 Retriever:
-
向量存储检索器(VectorStore Retriever)
- 基于向量相似度进行检索
- 示例:Chroma、FAISS、Pinecone 等向量数据库
-
关键字检索器(Keyword-Based Retriever)
- 基于传统关键词匹配
- 示例:TF-IDF、BM25
-
集成检索器(Ensemble Retriever)
- 结合多种检索方法的结果
- 提高检索的召回率和准确率
-
上下文压缩检索器(Contextual Compression Retriever)
- 对检索到的文档进行压缩,只保留相关部分
- 减少不必要信息的传输
4.在代码中的使用示例
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
# 创建向量数据库
vectorstore = Chroma(
persist_directory="./chroma_db",
embedding_function=OllamaEmbeddings(model="nomic-embed-text")
)
# 创建检索器
retriever = vectorstore.as_retriever(
search_type="similarity", # 检索类型:相似度
search_kwargs={"k": 3} # 返回最相关的3个文档
)
# 使用检索器
query = "什么是机器学习?"
relevant_docs = retriever.invoke(query)
5.检索器配置参数
常见的检索器配置选项:
search_type:检索类型(“similarity”、“mmr”、“similarity_score_threshold”)k:返回的文档数量score_threshold:相似度分数阈值fetch_k:初步检索的文档数量(用于MMR)
6.Retriever 在 RAG 中的应用
在检索增强生成(RAG)系统中,Retriever 扮演着关键角色:
- 从大规模知识库中检索相关信息
- 为生成模型提供上下文
- 提高生成答案的准确性和相关性
7.总结
Retriever 是 LangChain 中连接用户查询与知识库的关键桥梁,它通过高效的检索算法找到最相关的信息,为大语言模型提供准确的上下文,从而生成更高质量的回答。选择合适的 Retriever 类型和配置参数对于构建高效的问答系统至关重要。



















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











