 Keras实战指南
Keras实战指南





 本文详细介绍Keras库在图像分类任务中的应用,包括MNIST手写数字分类与CIFAR-10图像分类的具体实践,涵盖模型搭建、训练、测试及预测全流程,并探讨了正则化避免过拟合的方法及模型保存技术。
本文详细介绍Keras库在图像分类任务中的应用,包括MNIST手写数字分类与CIFAR-10图像分类的具体实践,涵盖模型搭建、训练、测试及预测全流程,并探讨了正则化避免过拟合的方法及模型保存技术。
主页 - Keras 中文文档Keras,Python 深度学习库中文文档。 https://keras.io/zh/
https://keras.io/zh/
1、mnist数据的分类,该实验进行了完整的模型训练测试以及预测,将新的样本送入进行预测,直观表征模型的有效性。keras送入模型训练的是ndarray数据,不要转化成tensor。
sklearn 的输入可以是ndarry可以使DataFrame ,但是DataFrame必须是二维的,因此数据维度大于二维时考虑采用ndarray进行训练。



# -*— coding:utf-8 -*-
# @time :2021/10/27 11:49
# @Author :zhangzhoubin
'''
Keras的研究,基于tensorflow theano框架的二次封装
'''
'''
功能:实现minist分类
'''
#导入第三方模块
import cv2
import numpy as np
import pandas as pd
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense,Activation,Dropout
from keras.optimizers import SGD
from keras.utils import np_utils
np.random.seed(1123)
#参数设定
out_num=10
#划分训练集和测试集
(train_x,train_y),(test_x,test_y)=mnist.load_data()
print("训练集形状",train_x.shape)
print("测试集形状",test_x.shape)
#改变形状、改变数值类型
train_x=train_x.reshape(60000,784).astype('float32')
test_x=test_x.reshape(10000,784).astype('float32')
#归一化、类向量二值化
train_X=train_x/255
test_X=test_x/255
train_Y=np_utils.to_categorical(train_y,out_num)
test_Y=np_utils.to_categorical(test_y,out_num)
print(train_X,train_Y)
#搭建网络模型
model=Sequential()
model.add(Dense(128,input_shape=(784,)))
#提升网络的深度
#起始
model.add(Activation('relu'))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.3))
model.add(Dense(236))
model.add(Activation('relu'))
#结束
model.add(Dense(10))
model.add(Activation('softmax'))
model.summary()
#训练模型
#模型编译
model.compile(loss='categorical_crossentropy',optimizer=SGD(),metrics=['accuracy'])
#模型训练
model.fit(train_X,train_Y,batch_size=64,epochs=2,validation_split=0.2,verbose=1)
#模型测试
score=model.evaluate(test_X,test_Y,verbose=1)
j=52
#模型预测,模型预测结果是softmax函数输出预测结果上不同类别的概率,类似[0.98,0.236,0.56...]
y_pred=model.predict(test_X[:j].reshape(-1,784),batch_size = 1)
print('test_score',score[0])
print('test_accuracy',score[1])
print(y_pred)
b=[]
#将预测结果转化二值标签类型
y_pred_f=y_pred.tolist()
for i in y_pred:
max_value=max(i)
print(max_value)
index=list(i).index(max_value)
print(index)
a=[]
for i in range(out_num):
if i==index:
a.append(1)
else:
a.append(0)
b.append(a)
#输出真实标签和预测标签二值类型
print('预测标签:',b)
print("真实标签:",test_Y[:j])
#将分类结果二值转化成原始标签(1,2,3,4,5,6,7,8,9),用于后期的模型预测
input_data = np.argmax(b, axis=1)
print("真实标签:",test_y[:j])
print("预测标签",input_data)
# #保存模型,然后导入模型作为预测
# from keras.models import load_model
# model=load_model('my_model.h5')
# score=model.evaluate(x_test,y_test,verbose=1)
# pred=model.predict(x_test)
# print(score[0],score[1])
# #模型评估
# print("真实值:",y_test)
# print("预测的值:",pred)
交叉熵损失函数:
 https://zhuanlan.zhihu.com/p/35709485
https://zhuanlan.zhihu.com/p/357094852、采用正则化的避免过拟合,正则化作用
模型的好坏依赖于在数据集上的损失决定,损失越小模型性能越好。为了尽可能减少损失模型会变得越来越复杂,从而导致两个问题:一、模型训练时间长,二、模型的在训练集上表现非常好,在测试集上表现不好,说明模型的泛化能力很差。本质模型学习就是学习多个有效的非零权重,模型的复杂度就是就由非零权重的个数决定。
因此,为了避免模型过拟合的问题,我们尽量选择最简单的包含非零权重个数的最少的模型,那么如何选择这样的模型呢,这就引入正则化规则:
L1正则化:也成为lasso,模型的复杂度表示为权重的绝对值之和
L2正则化:模型复杂度表示权重的平方和
弹性网络正则化:模型复杂度通过联合前述两个技术捕捉。
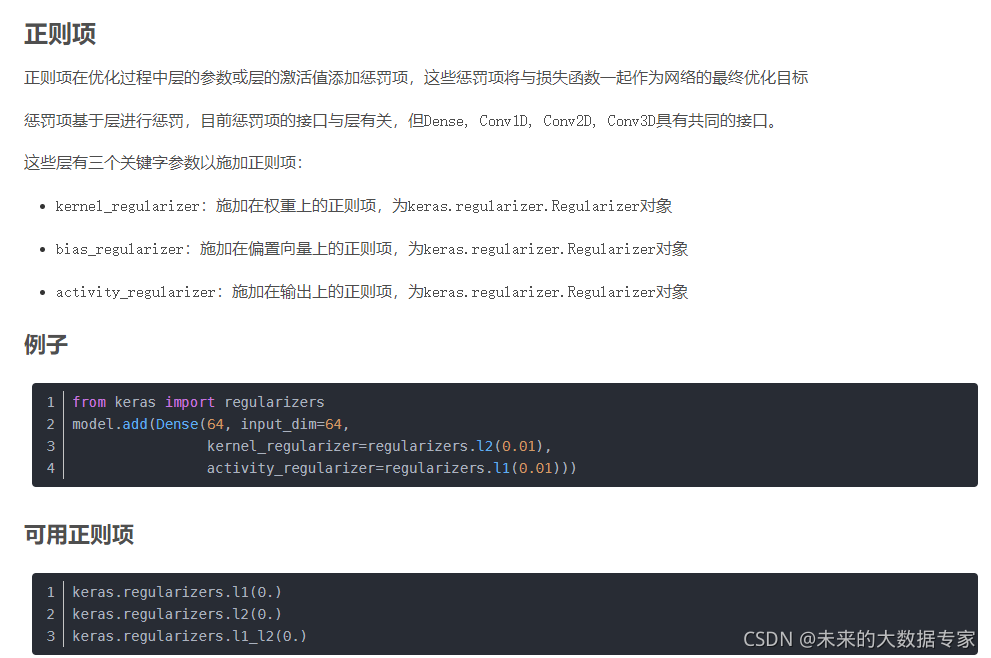

3、超参数调优
超参数:隐藏层神经元数量、batch_size、训练轮数、模型复杂度(正则化)、优化器中参数、Dropout、网络的层数等。
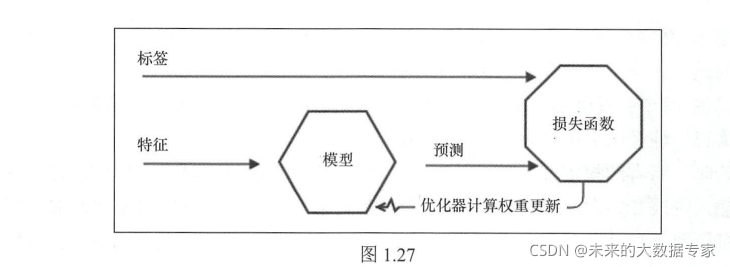
4、keras图像项目 cifar10图像分类,使用卷积神经网络进行图像分类
# -*— coding:utf-8 -*-
# @time :2021/11/1 10:38
# @Author :zhangzhoubin
'''
代码目标:cifar图像分类
'''
'''
功能:导入所需的包
'''
import pandas as pd
import numpy as np
from keras.models import Sequential
from keras.layers.core import Dense,Dropout,Flatten,Activation
from keras.utils import np_utils
from keras.optimizers import adam,RMSprop,SGD
from keras.datasets import cifar10
from keras.layers.convolutional import Conv2D,MaxPooling2D
'''
定义参数
'''
NB_CLASS=10
IMG_ROW=32
IMG_CLO=32
IMG_CHANNEL=3
'''
加载数据
对于数据进行处理
'''
(x_train,y_train),(x_test,y_test)=cifar10.load_data()
print(x_train.shape,y_train.shape)
print(x_test.shape,y_test.shape)
Y_train=np_utils.to_categorical(y_train,NB_CLASS)
Y_test=np_utils.to_categorical(y_test,NB_CLASS)
X_train=x_train.astype('float32')
X_test=x_test.astype('float32')
X_train/=255
X_test/=255
'''
构建网络模型
'''
model=Sequential()
model.add(Conv2D(32,(3,3),input_shape=(IMG_CLO,IMG_ROW,IMG_CHANNEL),padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dropout(0.25))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dense(NB_CLASS))
model.add(Activation('softmax'))
model.summary()
'''
模型编译、训练、测试
'''
model.compile(loss='categorical_crossentropy',optimizer=adam(),metrics=['accuracy'])
model.fit(X_train,Y_train,batch_size=128,epochs=2,validation_split=0.2,verbose=1)
score=model.evaluate(X_test,Y_test,batch_size=128,verbose=1)
print('test_score:',score[0])
print('test_accuracy:',score[1])
5、keras框架模型保存、模型二次继续训练技术
#模型保存
........
........
model.compile(loss='categorical_crossentropy',optimizer=adam(),metrics=['accuracy'])
#模型训练
model.fit(train_X,train_Y,batch_size=64,epochs=10,validation_split=0.2,verbose=1)
score=model.evaluate(test_X,test_Y,verbose=1)
print('test_score',score[0])
print('test_accuracy',score[1])
#模型保存
model.save('my_model.h5') #模型保存
#模型加载,新来数据继续训练模型,并保存
from keras.model import load_model
model=load_model('my_model.h5') #导入模型
model.compile(loss='categorical_crossentropy',optimizer=adam(),metrics=['accuracy'])
#模型训练
model.fit(train_X,train_Y,batch_size=64,epochs=10,validation_split=0.2,verbose=1)
score=model.evaluate(test_X,test_Y,verbose=1)
print('test_score',score[0])
print('test_accuracy',score[1])
#这个地方可以继续保存训练的模型
model.save('my_model.h5')
#将保存的模型导入,直接预测
from keras.model import load_model
model=load_model('my_model.h5') #导入模型
score=model.evaluate(test_X,test_Y,verbose=1)
print('test_score',score[0])
print('test_accuracy',score[1])
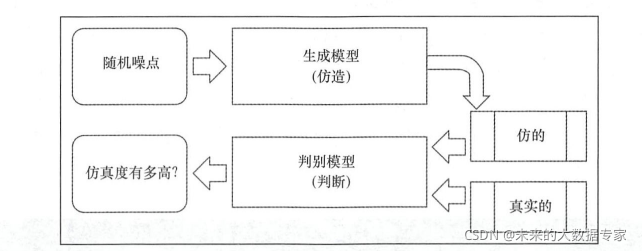
6、生成对抗网络

















 632
632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









