



之前配置hadoop100的笔记先保存在这
1 hadoop100虚拟机配置要求
(1)使用 yum 安装需要虚拟机可以正常上网,yum 安装前可以先测试下虚拟机联网情况
命令su root输入密码进入root权限 ping www.baidu.com检验下外网是否可连
(2)安装 epel-release
注:Extra Packages for Enterprise Linux 是为“红帽系”的操作系统提供额外的软件包,适用于 RHEL、CentOS 和 Scientific Linux。相当于是一个软件仓库,大多数 rpm 包在官方 repository 中是找不到的)
命令yum install -y epel-release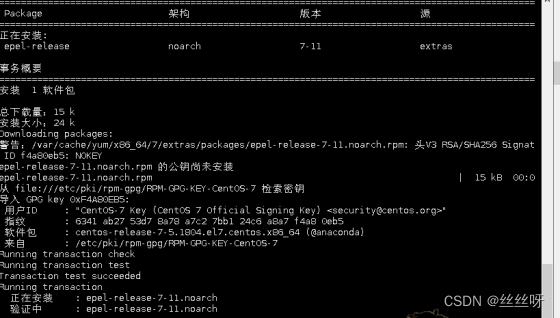
注意: 如果 Linux 安装的是最小系统版, 还需要安装如下工具; 如果安装的是 Linux桌面标准版,不需要执行如下操作
➢ net-tool:工具包集合,包含 ifconfig 等命令
命令:yum install -y net-tools
➢ vim:编辑器
命令: yum install -y vim
关闭防火墙 ,关闭防火墙开机自启
命令:systemctl stop firewalld
命令:systemctl disable firewalld.service
注意:在企业开发时,通常单个服务器的防火墙时关闭的。公司整体对外会设置非常安全的防火墙

2 配置 zhang 用户具有 root 权限 , 方便 后期 加 sudo 执行 root 权限的命令
命令:vim /etc/sudoers
进入,下翻,找到如下地方
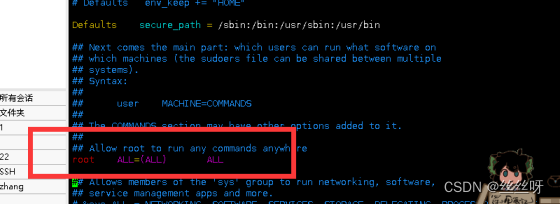
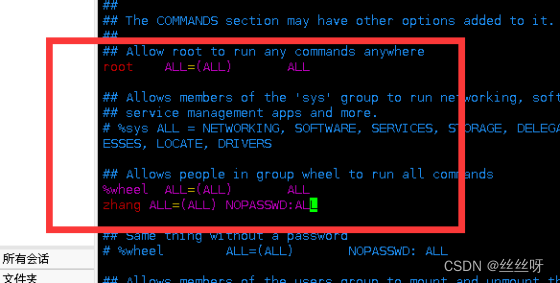
然后保存退出
在/opt 目录下创建文件夹 ,并修改所属主和所属组
(1)在/opt 目录下创建 module、software 文件夹
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software
(2)修改 module、software 文件夹的所有者和所属组均为 atguigu 用户
[root@hadoop100 ~]# chown zhang:zhang /opt/module
[root@hadoop100 ~]# chown zhang:zhang /opt/software
(3)查看 module、software 文件夹的所有者和所属组
[root@hadoop100 ~]# cd /opt/
[root@hadoop100 opt]# ll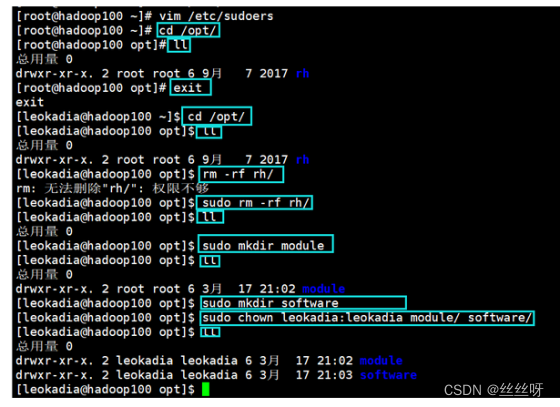
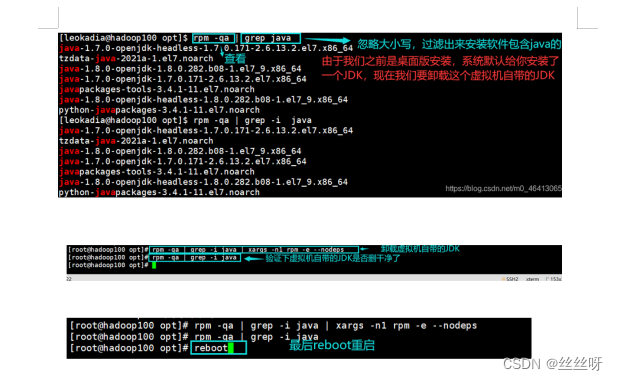
卸载虚拟机自带的 JDK
注意:如果你的虚拟机是最小化安装不需要执行这一步。
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
➢ rpm -qa:查询所安装的所有 rpm 软件包
➢ grep -i:忽略大小写
➢ xargs -n1:表示每次只传递一个参数
➢ rpm -e –nodeps:强制卸载软件
[root@hadoop100 opt]# rpm -qa | grep -i java 检查是否删完
[root@hadoop100 ~]# reboot
3 Hadoop集群搭建-克隆三台虚拟机
hadoop100关闭——管理——克隆
配置克隆出来的虚拟机的IP地址,主机名称
分别执行以下三条命令:
vim /etc/sysconfig/network-scripts/ifcfg-ens33(Linux的网卡参数详解)
vim /etc/hostname
vim /etc/hosts
配置完之后检查IP和网络
当出现虚拟机不能ping通的情况:重启网络
systemctl restart network
三台克隆虚拟机都配置好了后,将XSHELL也配置好:
4 JDK安装
在hadoop102上安装JDK
查看是否安装成功

解压JDK到/opt/module目录下
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/

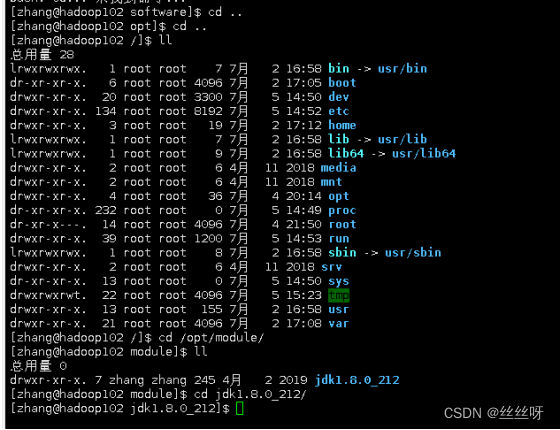
4.1 配置 JDK 环境变量
sudo vim /etc/profile.d/my_env.sh
![]()
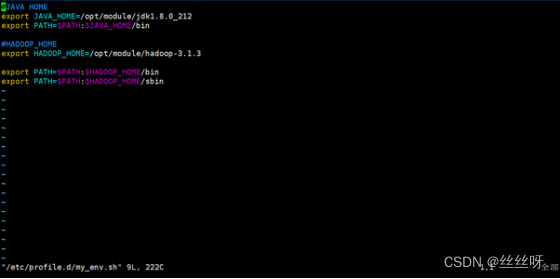
添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin 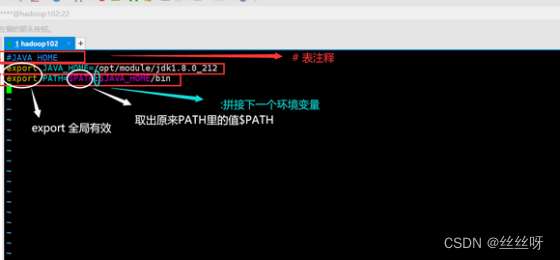
source /etc/profile

5 Hadoop安装
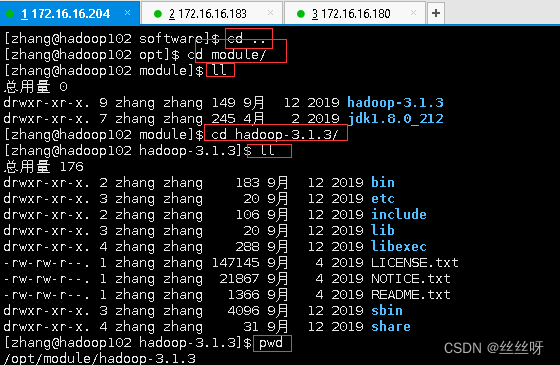
cd /opt/software/
ll
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/

sudo vim /etc/profile.d/my_env.sh
![]()
在 my_env.sh 文件末尾添加如下内容:
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin 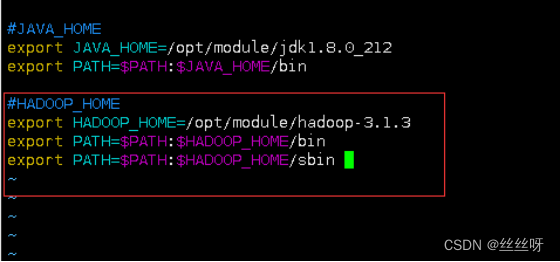
source /etc/profile
hadoop
ll
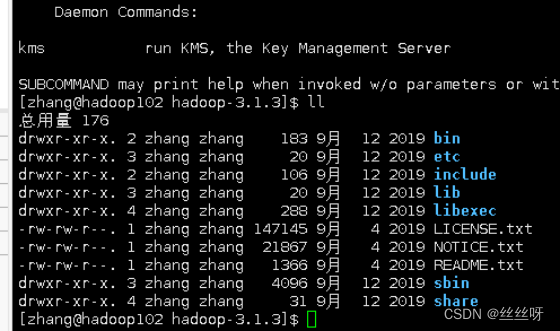
重要目录
(1)bin 目录:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本
(2)etc 目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件
(3)lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
(4)sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
(5)share 目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例
6 Hadoop 运行模式
Hadoop 官方网站:Apache Hadoop


本地运行模式 (官方 WordCount案例 )
1 ) 创建在 hadoop-3.1.3 文件下面创建一个 wcinput 文件夹
[zhang@hadoop102 hadoop-3.1.3]$ mkdir wcinput
2 ) 在 wcinput 文件下创建一个 word.txt 文件
[zhang@hadoop102 hadoop-3.1.3]$ cd wcinput
3 ) 编辑 word.txt 文件
[zhang@hadoop102 wcinput]$ vim word.txt
➢ 在文件中随便输入一些内容
➢ 保存退出::wq
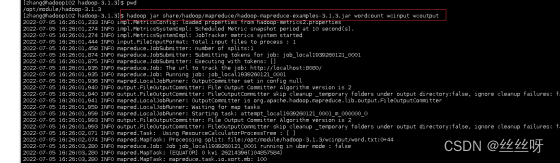
执行程序
[zhang@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput

7 完全分布式运行模式(重点)
分析:
1)准备 3 台客户机(关闭防火墙、静态 IP、主机名称)
2)安装 JDK
3)配置环境变量
4)安装 Hadoop
5)配置环境变量
注,以上步骤我们均在hadoop102上搞定了
6)配置集群
7)单点启动
8)配置 ssh
9)群起并测试集群
查看hadoop103和hadoop104上的module和software是否存在
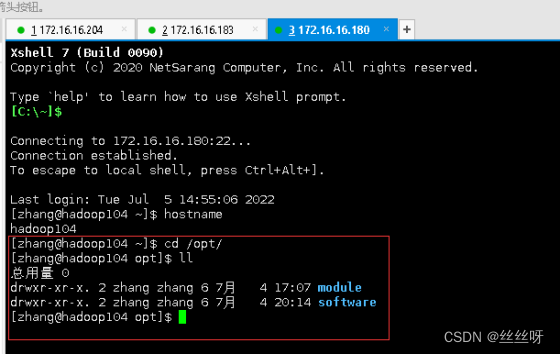
在 hadoop102 上,将 hadoop102 中/opt/module/jdk1.8.0_212 目录拷贝到hadoop103 上。
[zhang@hadoop102 ~]$ scp -r /opt/module/jdk1.8.0_212 zhang@hadoop103:/opt/module
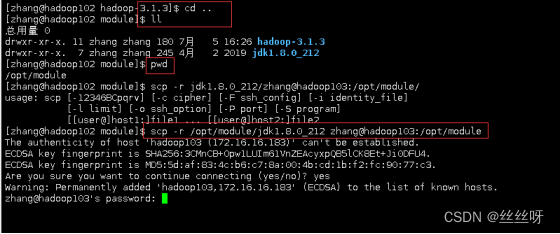
hadoop103上查看是否拷贝成功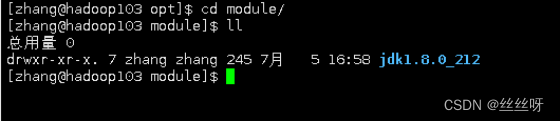
在 hadoop103 上,将 hadoop102 中/opt/module/hadoop-3.1.3 目录拷贝到hadoop103 上。
[zhang@hadoop103 ~]$ scp -r zhang@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/
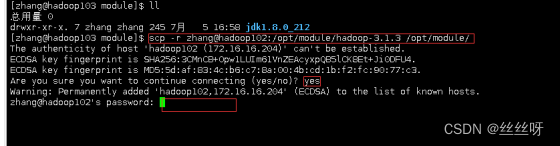
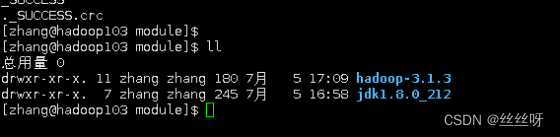
在 hadoop103 上操作,将 hadoop102 中/opt/module 目录下所有目录拷贝到hadoop104 上
[zhang@hadoop103 opt]$ scp -r zhang@hadoop102:/opt/module/
zhang@hadoop104:/opt/module
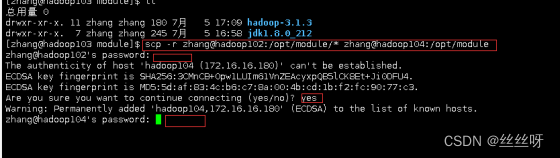
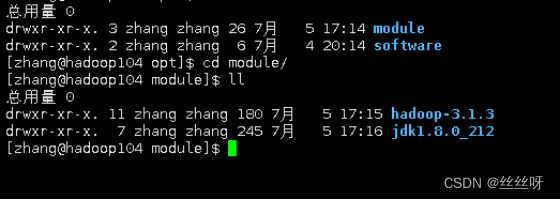
在hadoop104上查看,拷贝成功
8 rsync 远程同步工具
rsync 主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync 和 scp 区别:用 rsync 做文件的复制要比 scp 的速度快,rsync 只对差异文件做更
新。scp 是把所有文件都复制过去。
(1)基本语法
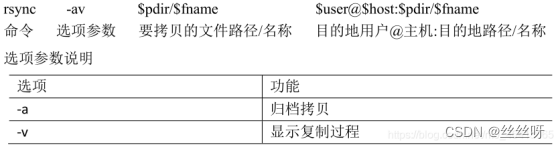
删除 hadoop103 中/opt/module/hadoop-3.1.3/wcinput
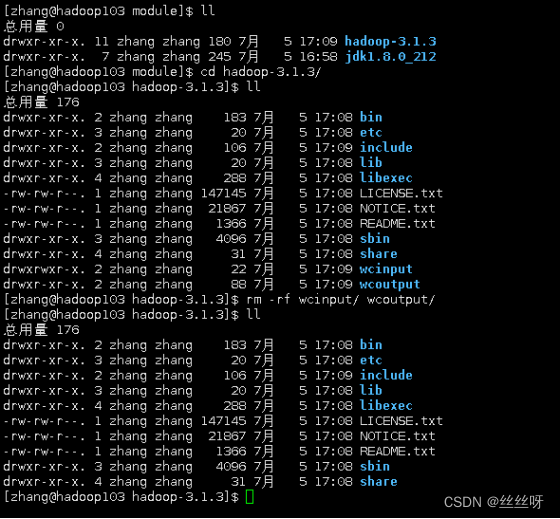 [zhang@hadoop103 hadoop-3.1.3]$ rm -rf wcinput/
[zhang@hadoop103 hadoop-3.1.3]$ rm -rf wcinput/
同步 hadoop102 中的/opt/module/hadoop-3.1.3 到 hadoop103
希望将 hadoop102 中的hadoop-3.1.3 到 hadoop103
看是所有的内容都拷贝,还是只拷贝差异性内容
[zhang@hadoop102 module]$ rsync -av hadoop-3.1.3/ zhang@hadoop103:/opt/module/hadoop-3.1.3/
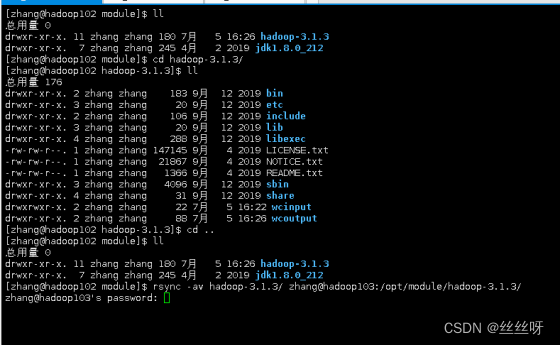
在hadoop103中验证:同步成功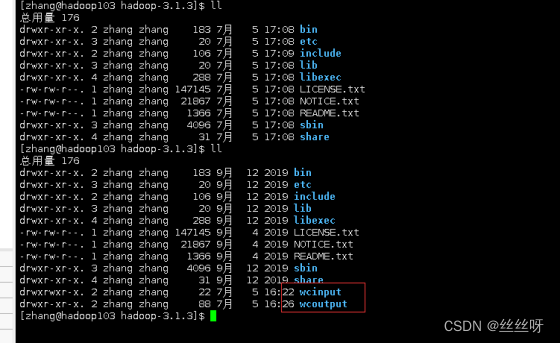
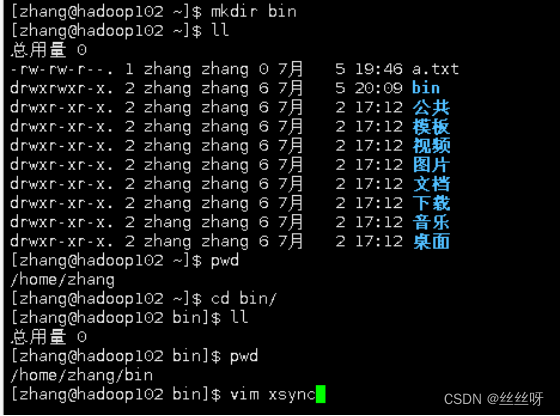
xsync 集群分发 脚本
(1)需求:循环复制文件到所有节点的相同目录下
在家目录下创建一个文件,希望写一个脚本,一执行这个命令,a.txt就可以分发到相同的路径
(2)需求分析:
(a)rsync 命令原始拷贝:
rsync -av /opt/module zhang@hadoop103:/opt/
(b)期望脚本:
xsync 要同步的文件名称
(c)期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径)
[zhang@hadoop102 ~]$ echo $PATH 查看 全局环境变量的路径
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/home/zhang/.local/bin:/home/zhang/bin
![]()
#!/bin/bash
#1. 判断参数个数
判断参数是否小于1
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
对102,103,104都进行分发
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
# 如果不存在
else
echo $file does not exists!
fi
done
done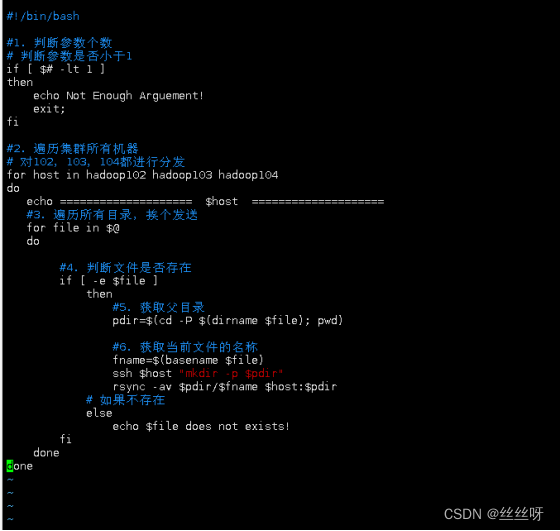
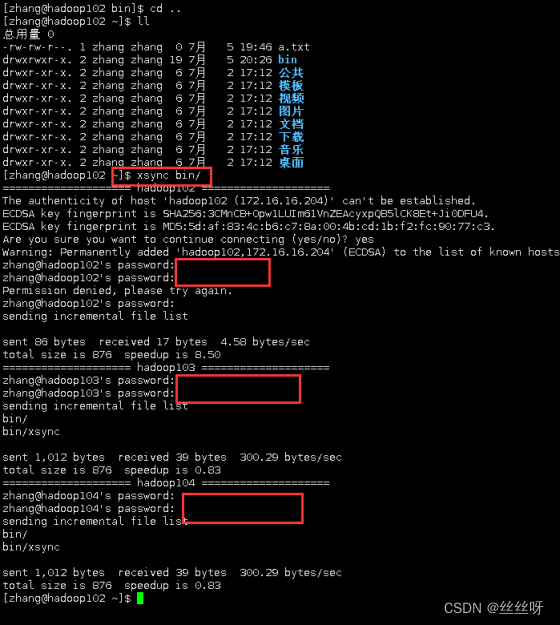
在hadoop103,hadoop104上验证,发现脚本传输成功
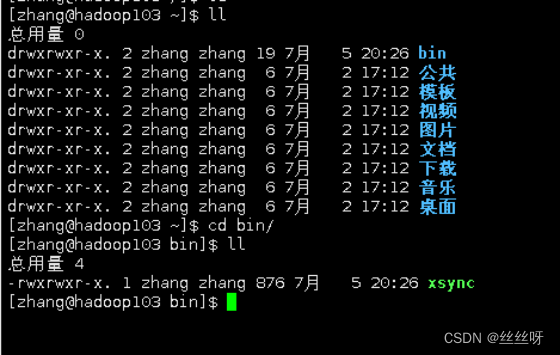
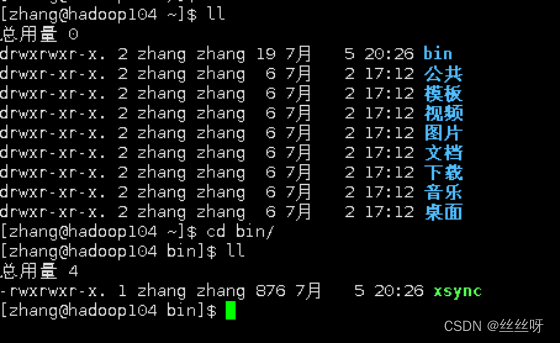
[zhang@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh
注意:如果用了 sudo,那么 xsync 一定要给它的路径补全。
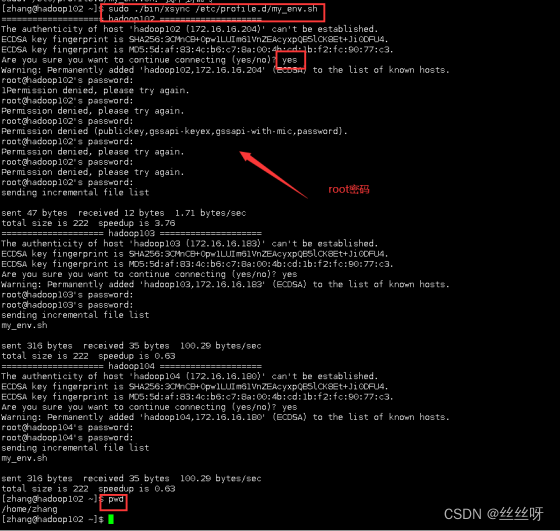
在hadoop103,hadoop104下验证一下:
[zhang@hadoop103 bin]$ sudo vim /etc/profile.d/my_env.sh
[zhang@hadoop103 bin]$ source /etc/profile
[zhang@hadoop104 bin]$ source /etc/profile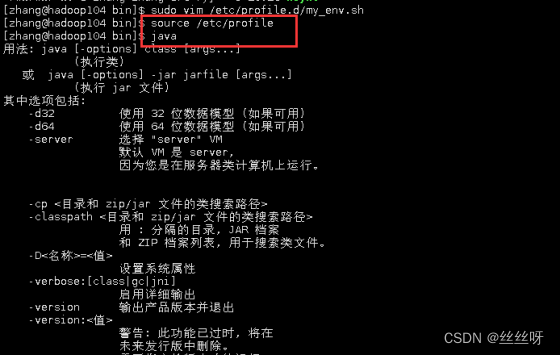
9 SSH免密登录 配置
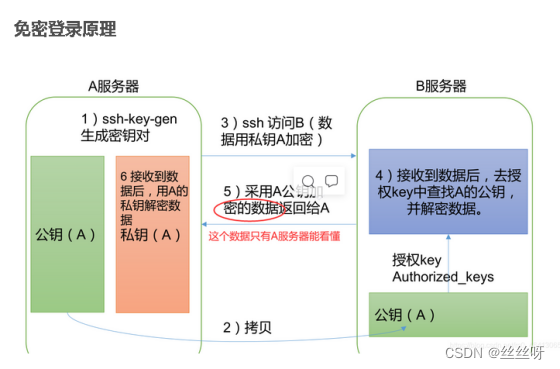
私钥始终掌握在自己的服务器上,不要给别人,否则服务器秘密被泄露,通常公钥拷贝给对方,对方将公钥放在一个已授权的文件,只要放在这个文件,后续再访问这个,查到有对应的公钥,相当于两台服务器已经达成协议,允许访问。
ssh 另一台电脑的 IP 地址
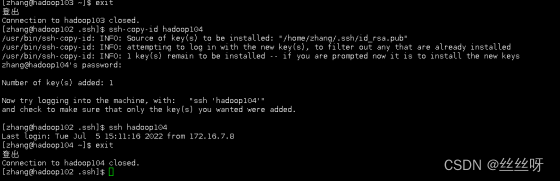
我们先用hadoop102访问一下hadoop103
[zhang@hadoop102 ~]$ ssh hadoop103
用hadoop102访问了hadoop103,二者均出现.ssh文件
ls -al 查看所有隐藏文件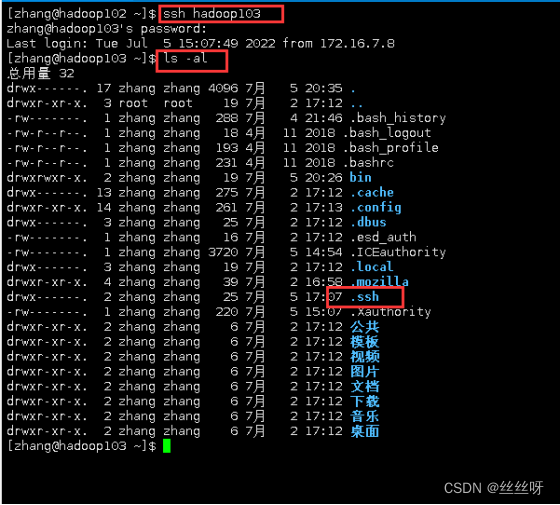
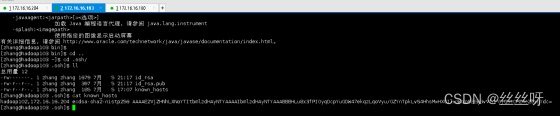
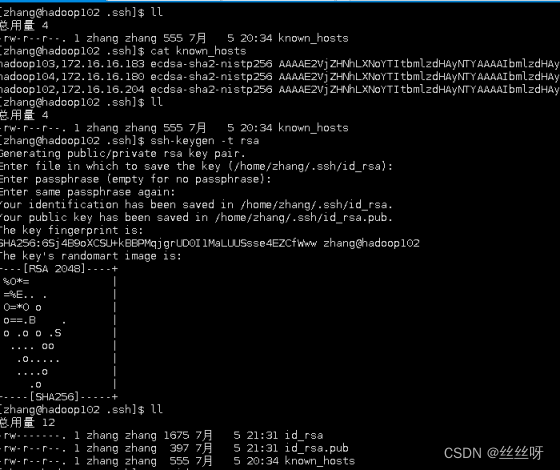
得到私钥
得到公钥
![]()


同样方式访问104
访问自己

相同方法配置103和104分别对102,103,104无密登录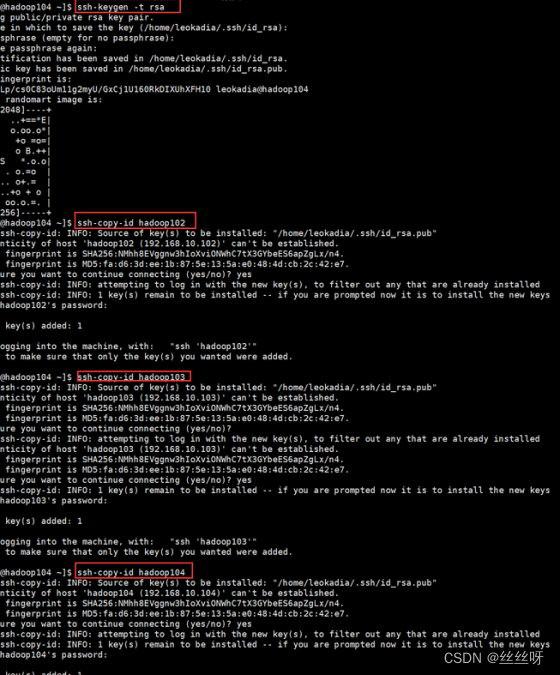
在root上访问hadoop103还是要密码,因此我们在每台主机的root用户再配置下免密登录
这里只展示hadoop102 root用户的配置: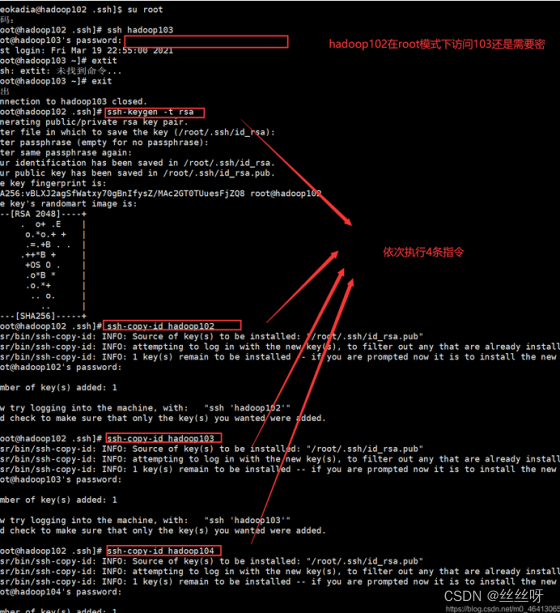
10 集群配置
NameNode 和 SecondaryNameNode 不要安装在同一台服务器 。
(它们两个都需要耗内存,分开减少集群的压力)
ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在同一台机器上
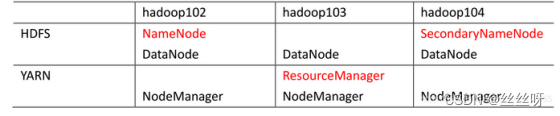

自定义配置文件:
core-site.xml 、hdfs-site.xml 、yarn-site.xml 、mapred-site.xml 四个配置文件存放在
$HADOOP_HOME/etc/hadoop 这个路径上,用户可以根据项目需求重新进行修改配置。
配置 core-site.xml
[zhang@hadoop102 ~] $ cd $HADOOP_HOME/etc/hadoop
[zhang@hadoop102 hadoop]$ vim core-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 zhang -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>zhang</value>
</property>
</configuration> 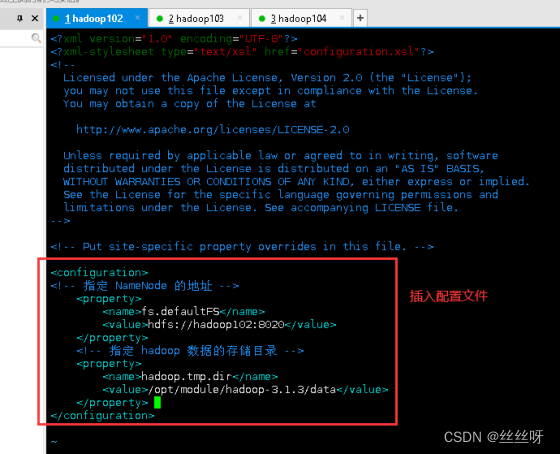
配置 hdfs-site.xml
[zhang@hadoop102 hadoop]$ vim hdfs-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- NameNode web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- SecondaryNameNode web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration> 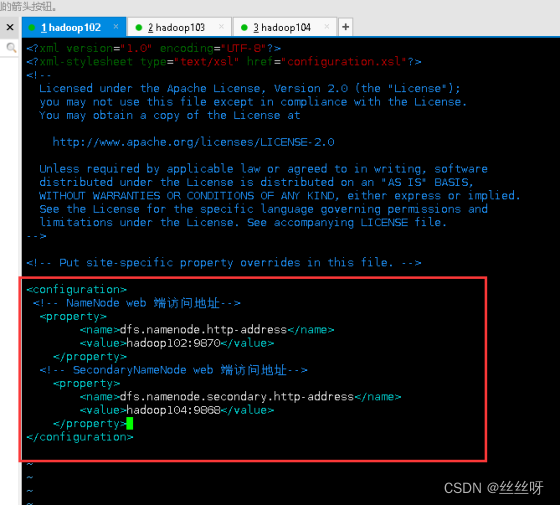
配置 yarn-site.xml
[zhang@hadoop102 hadoop]$ vim yarn-site.xml 文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration> 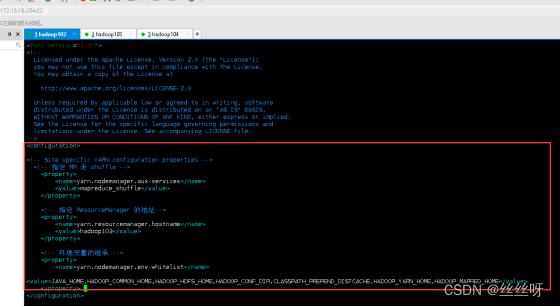
配置 mapred-site.xml
[zhang@hadoop102 hadoop]$ vim mapred-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> 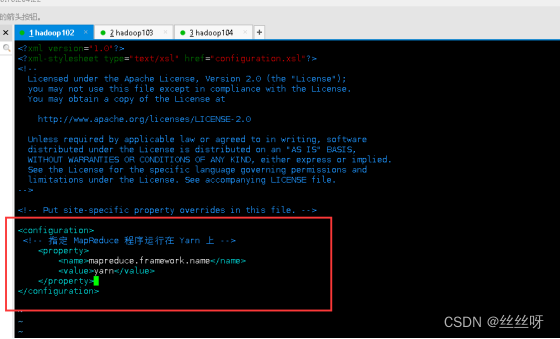
在集群上分发配置好的 Hadoop 配置文件
[zhang@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/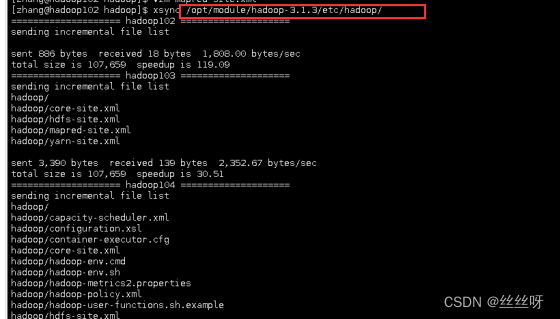
去 103 和 104 上 查看文件分发情况
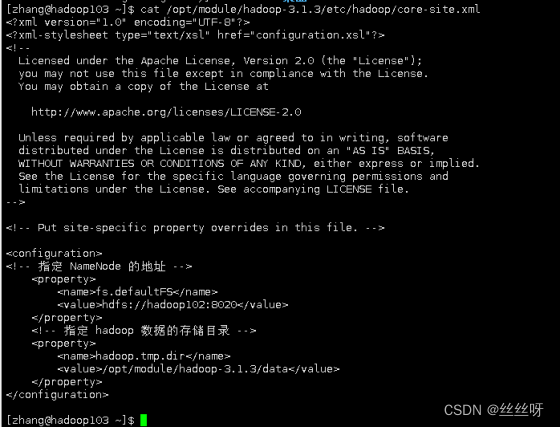
[zhang@hadoop103 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
[zhang@hadoop104 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
11 启动集群并测试
启动集群之前需要配置workers
先进入hadoop目录
[zhang@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop
[zhang@hadoop102 hadoop]$ vim workers
删除默认的localhost
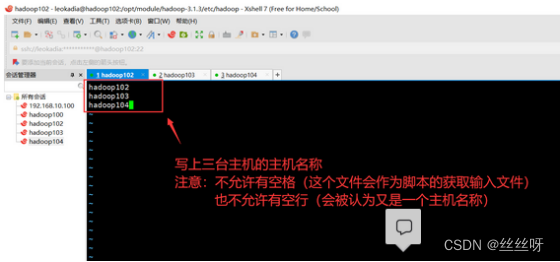
分发[zhang@hadoop102 hadoop]$ xsync workers
[zhang@hadoop102 hadoop]$ cd ..
[zhang@hadoop102 etc]$ cd ..
[zhang@hadoop102 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
初始化(第一次需要)
[zhang@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
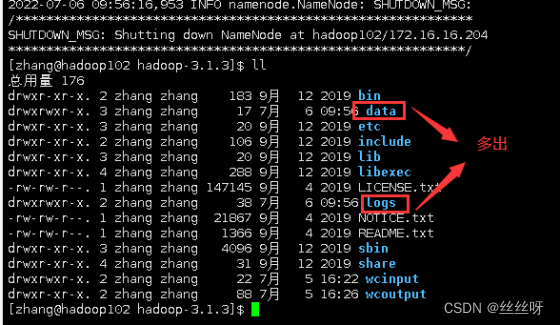
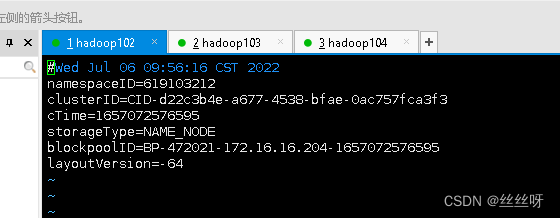
12 启动 HDFS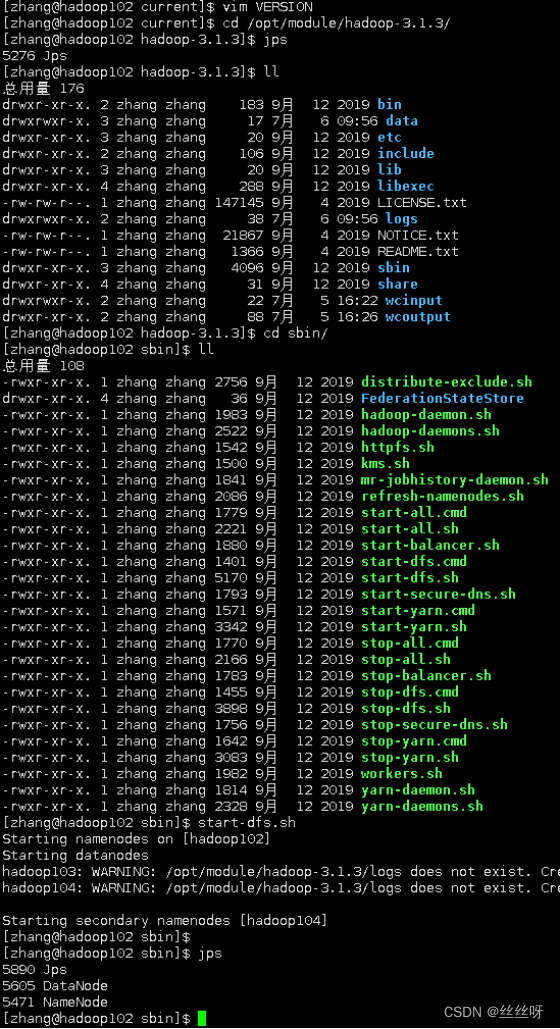
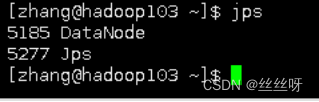
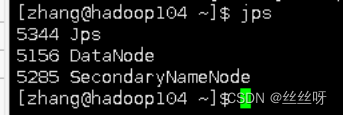
用jps查看和最初设置一样
在配置了 ResourceManager 的节点 (hadoop103 )启动 YARN
[zhang@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh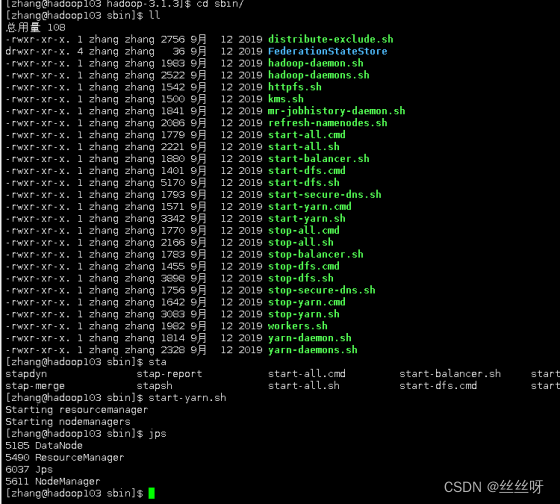
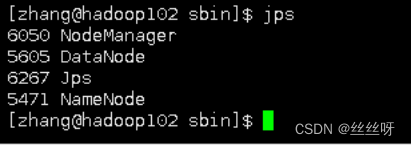
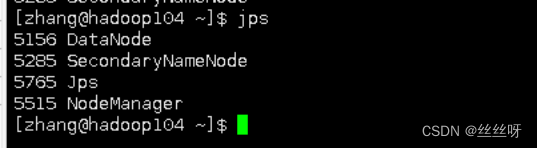
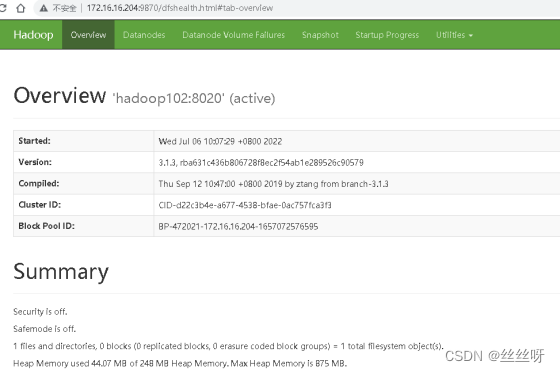
11.1 Web 端查看 HDFS 的 NameNode
11.2 Web 端查看 YARN 的 ResourceManager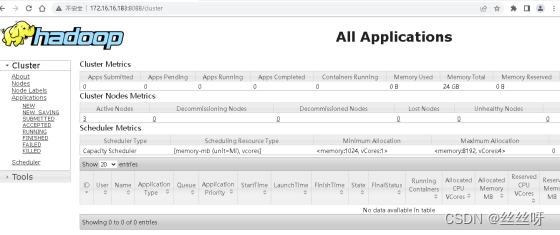
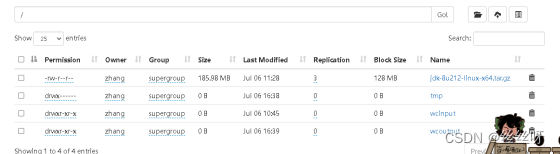
12 集群基本测试
上传文件到集群
➢ 上传小文件
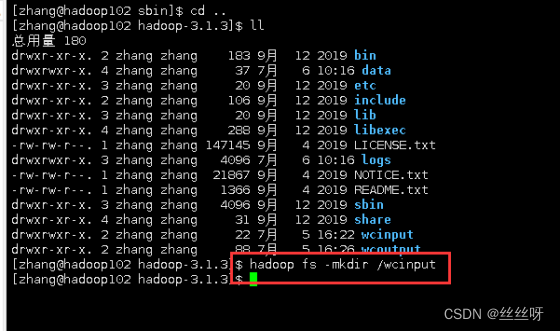
[zhang@hadoop102 ~]$ hadoop fs -mkdir /input
执行完后,HDFS网页种多了个文件
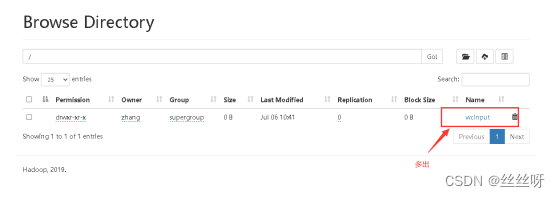
传递一个本地文件
[zhang@hadoop102 ~]$ hadoop fs -put $HADOOP_HOME/wcinput/word.txt /input
上传大文件
[zhang@hadoop102 ~]$ hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /
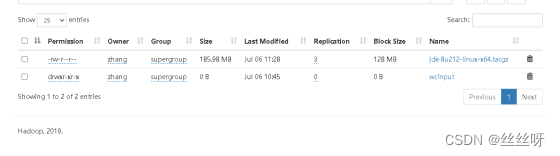
查看 HDFS 文件存储路径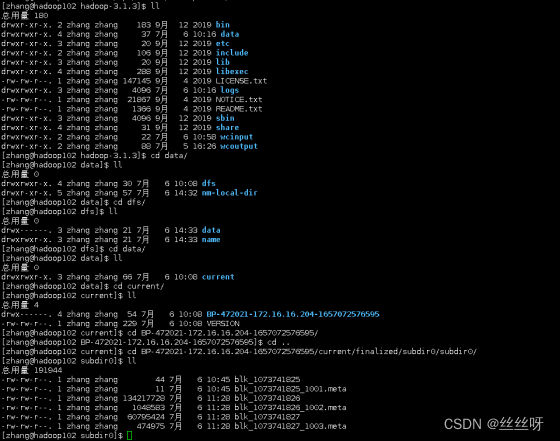

查看一个文件,追加写到文件后缀
[zhang@hadoop102 subdir0]$ cat blk_1073741826>>tmp.tar.gz
[zhang@hadoop102 subdir0]$ cat blk_1073741827>>tmp.tar.gz
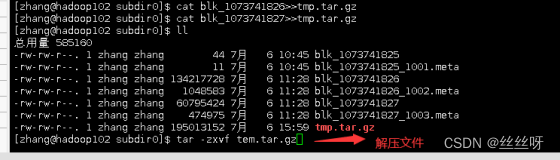
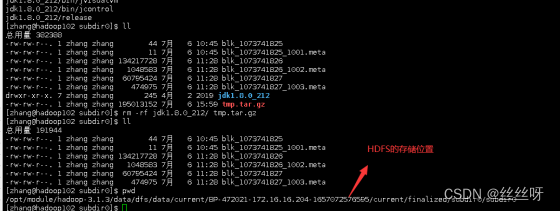
Hadoop高可用,任何一个服务器挂了还有两份副本
求证是否真的有三个副本
在hadoop103上再找一次路径,发现跟102上存储的数据一模一样
三台数据存储一样

执行 wordcount 程序
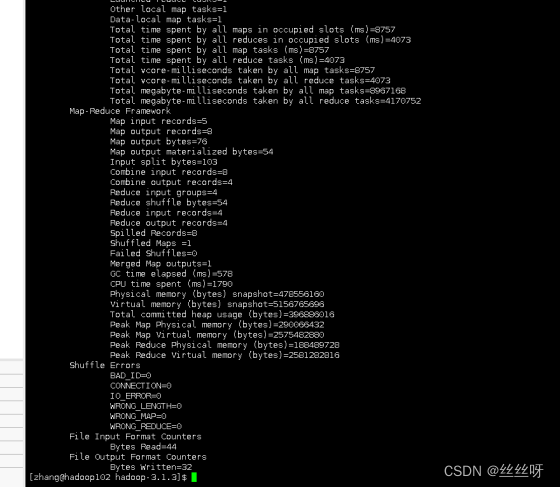
13 集群崩溃的处理方法
(1)先回到目录
[zhang@hadoop102 current]$ cd $HADOOP_HOME
(2)先杀死进程
[zhang@hadoop102 hadoop-3.1.3]$ sbin/stop-dfs.sh
(3)删除每一个集群上的data和logs
[zhang@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs
(4)最后再进行格式化
[zhang@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
(5)初始化后再次启动集群
打扫干净屋子再启动
先停进程,再清历史数据,再格式化,最后启动
[zhang@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
进入网页,可以看见网页可以出现了,但数据都被清空了
配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1 ) 配置 mapred-site.xml
只需在mapred-site.xml配置文件加两个参数:
[zhang@hadoop102 hadoop]$ vim mapred-site.xml
在该文件里面增加如下配置。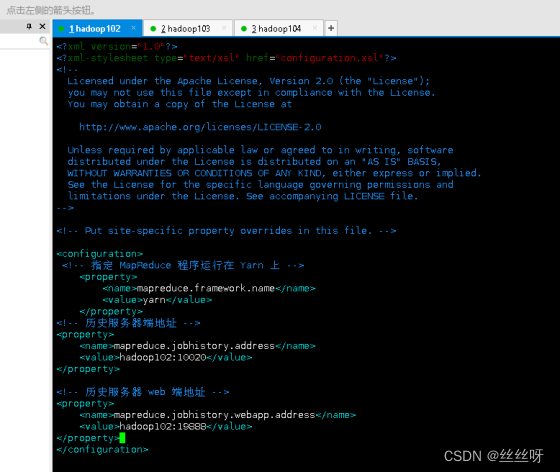
分发配置
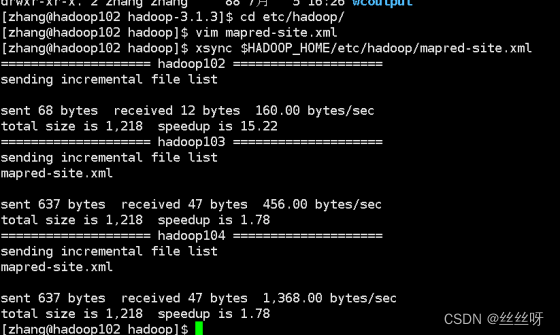
[zhang@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
先重新启动一下集群,先stop后start
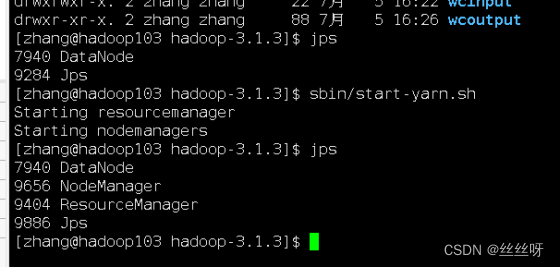
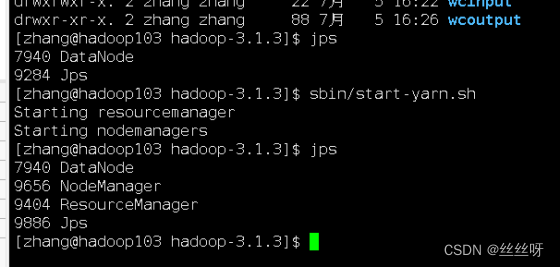
在 hadoop102 启动历史服务器
[zhang@hadoop102 hadoop]$ mapred --daemon start historyserver
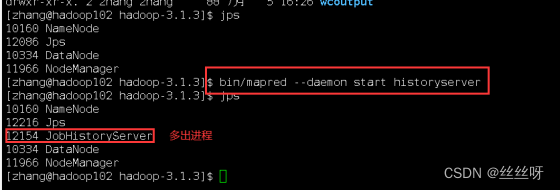
[zhang@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /input
[zhang@hadoop102 hadoop-3.1.3]$ hadoop fs -put wcinput/word.txt /input
2022-07-06 19:28:52,703 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
[zhang@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动 NodeManager 、ResourceManager 和HistoryServer。
开启日志聚集功能具体步骤如下:
1 ) 配置 yarn-site.xml
[zhang@hadoop102 hadoop]$ vim yarn-site.xml
在该文件里面增加如下配置。
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property> 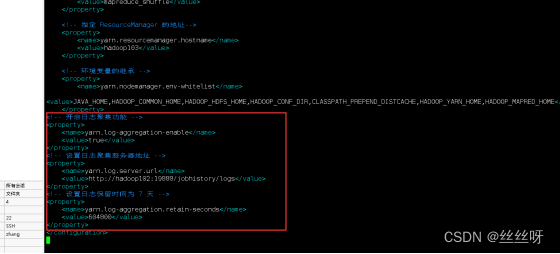
分发配置[zhang@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
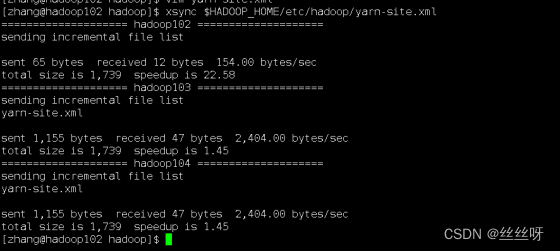
注意:分发完毕后一定要重启一下yarn
关闭HistoryServer
[zhang@hadoop102 hadoop-3.1.3]$ mapred --daemon stop historyserver
关闭 NodeManager 、ResourceManager
[zhang@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
启动 NodeManager 、ResourceManage
[zhang@hadoop103 ~]$ start-yarn.sh
启动 HistoryServer
[zhang@hadoop102 ~]$ mapred --daemon start historyserver
14 执行 WordCount 程序
[zhang@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
编写 Hadoop 集群常用脚本
1 )Hadoop 集群启停脚本(包含 HDFS ,Yarn ,Historyserver ):
myhadoop.sh
[zhang@hadoop102 hadoop-3.1.3]$ cd /home/zhang/bin 进入c盘bin目录,将脚本放在这里
[zhang@hadoop102 bin]$ vim myhadoop.sh
输入如下内容
记住:写脚本的时候能写绝对路径,千万不要写相对路径!
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac 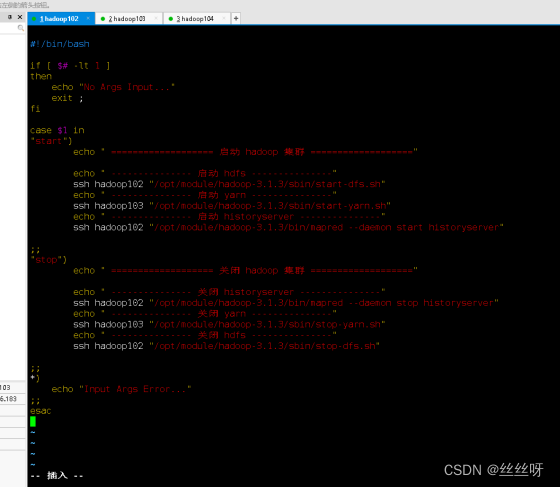
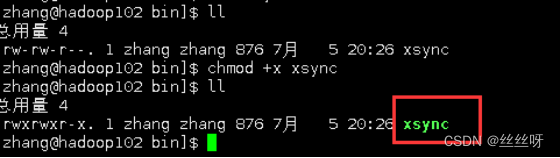
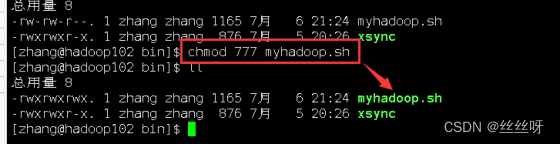
保存后退出,然后赋予脚本执行权限
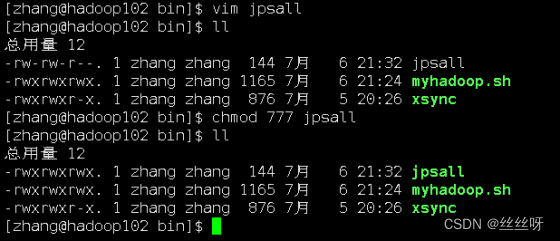
[zhang@hadoop102 bin]$ chmod +x myhadoop.sh
测试一下好不好使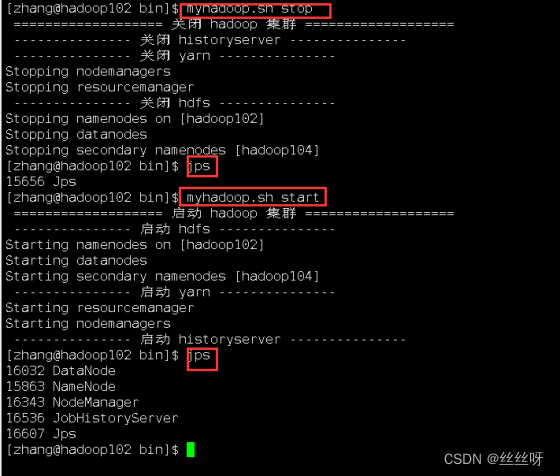
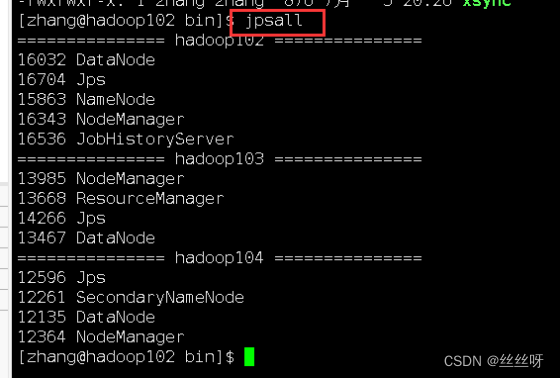
查看三台服务器 Java 进程脚本:jpsall
由于每次查看进程都得到每台服务器上输入jps查看,比较麻烦,且如果服务器较多,十分耗时,于是想到编写一个脚本,查看所有服务器的进程情况。
[zhang@hadoop102 ~]$ cd /home/zhang/bin
[zhang@hadoop102 bin]$ vim jpsall
输入如下内容
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done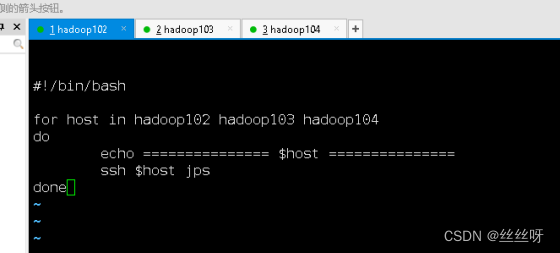
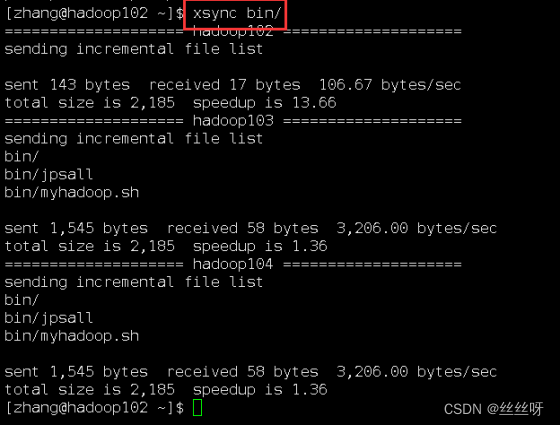
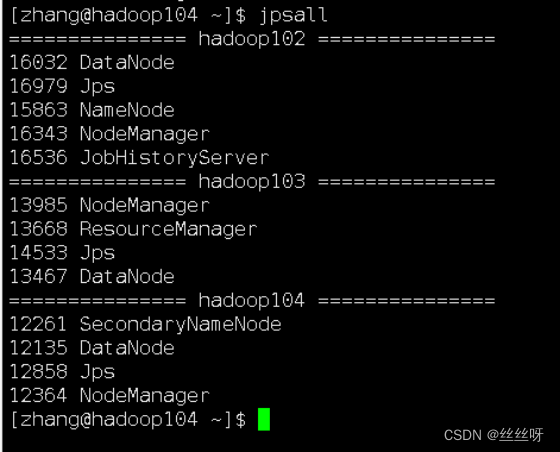
分发目录,保证三台机器都能使用
14 集群时间同步
如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期和公网时间进行校准;
如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差,导致集群执行任务时间不同步。
找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,生产环境根据任务对时间的准确程度要求周期同步。
测试环境为了尽快看到效果, 采用 1 分钟同步一次。
时间服务器配置(必须 root 用户)
(1)查看所有节点 ntpd 服务状态和开机自启动状态
[zhang@hadoop102 ~]$ sudo systemctl status ntpd
[zhang@hadoop102 ~]$ sudo systemctl start ntpd
[zhang@hadoop102 ~]$ sudo systemctl is-enabled ntpd
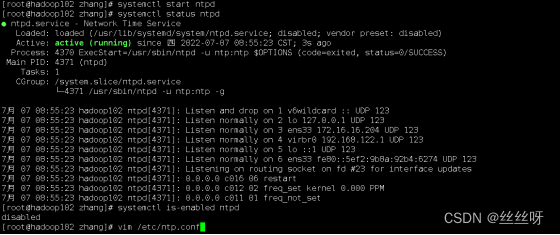
(2)修改 hadoop102 的 ntp.conf 配置文件
[zhang@hadoop102 ~]$ sudo vim /etc/ntp.conf
修改内容如下
(a)修改 1(授权 192.168.10.0-192.168.10.255 网段上的所有机器可以从这台机器上查
询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
为 restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
(b)修改 2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
(c) 添加 3 (当该节点丢失网络连接, 依然可以采用本地时间作为时间服务器为集群中
的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
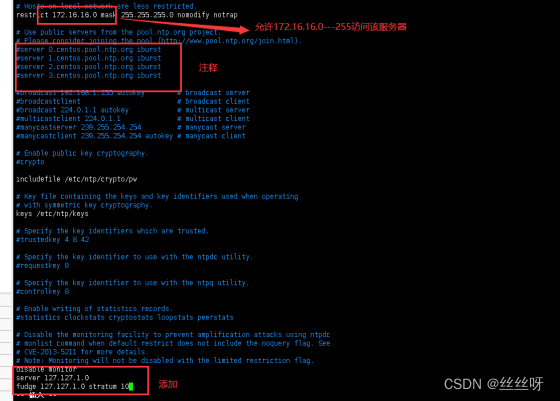
(3)修改 hadoop102 的/etc/sysconfig/ntpd 文件
[zhang@hadoop102 ~]$ sudo vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动 ntpd 服务
[zhang@hadoop102 ~]$ sudo systemctl start ntpd
(5)设置 ntpd 服务开机启动
[zhang@hadoop102 ~]$ sudo systemctl enable ntpd
3 ) 其他机器配置(必须 root 用户)
(1)关闭所有节点上 ntp 服务和自启动
[zhang@hadoop103 ~]$ sudo systemctl stop ntpd
[zhang@hadoop103 ~]$ sudo systemctl disable ntpd
[zhang@hadoop104 ~]$ sudo systemctl stop ntpd
[zhang@hadoop104 ~]$ sudo systemctl disable ntpd
(2)在其他机器配置 1 分钟与时间服务器同步一次
[zhang@hadoop103 ~]$ sudo crontab -e
编写定时任务如下:
*/1 * * * * /usr/sbin/ntpdate hadoop102
(3)修改任意机器时间
[zhang@hadoop103 ~]$ sudo date -s "2021-9-11 11:11:11"
(4)1 分钟后查看机器是否与时间服务器同步
[zhang@hadoop103 ~]$ sudo date

















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









