



AlexNet 是 2012 年由 Alex Krizhevsky 等人提出的卷积神经网络(CNN),在 ImageNet 图像分类竞赛中以远超传统方法的准确率夺冠,彻底推动了深度学习在计算机视觉领域的爆发。以下从核心维度全面拆解 AlexNet 的知识点,兼顾理论细节与实战价值。
一、AlexNet 的背景与历史地位
在 AlexNet 出现前,计算机视觉领域主要依赖手工设计特征(如 SIFT、HOG),模型泛化能力弱;而 2012 年 AlexNet 在 ImageNet 竞赛中,将 top-5 错误率从传统方法的 26% 降至 15.3%,这一突破性成果证明了深度学习在图像识别中的巨大潜力,直接开启了 “深度 CNN 统治计算机视觉” 的时代。
-
核心贡献:首次将 CNN 成功应用于大规模图像数据集,为后续 VGG、ResNet、Inception 等经典网络奠定了设计范式。
-
竞赛背景:基于 ImageNet 数据集(包含 1000 个类别、约 120 万张训练图、5 万张验证图),AlexNet 的夺冠让工业界和学术界意识到 “端到端学习”(从像素直接学习特征)的优越性。
二、AlexNet 的网络结构细节(经典 8 层架构)
AlexNet 包含5 个卷积层(Conv)+3 个全连接层(FC),输入图像尺寸为 227×227×3(注:论文中写 224×224,实际计算时因卷积步长等原因等效为 227×227),最终输出 1000 个类别的概率(对应 ImageNet 的 1000 类)。各层参数与功能如下表所示:
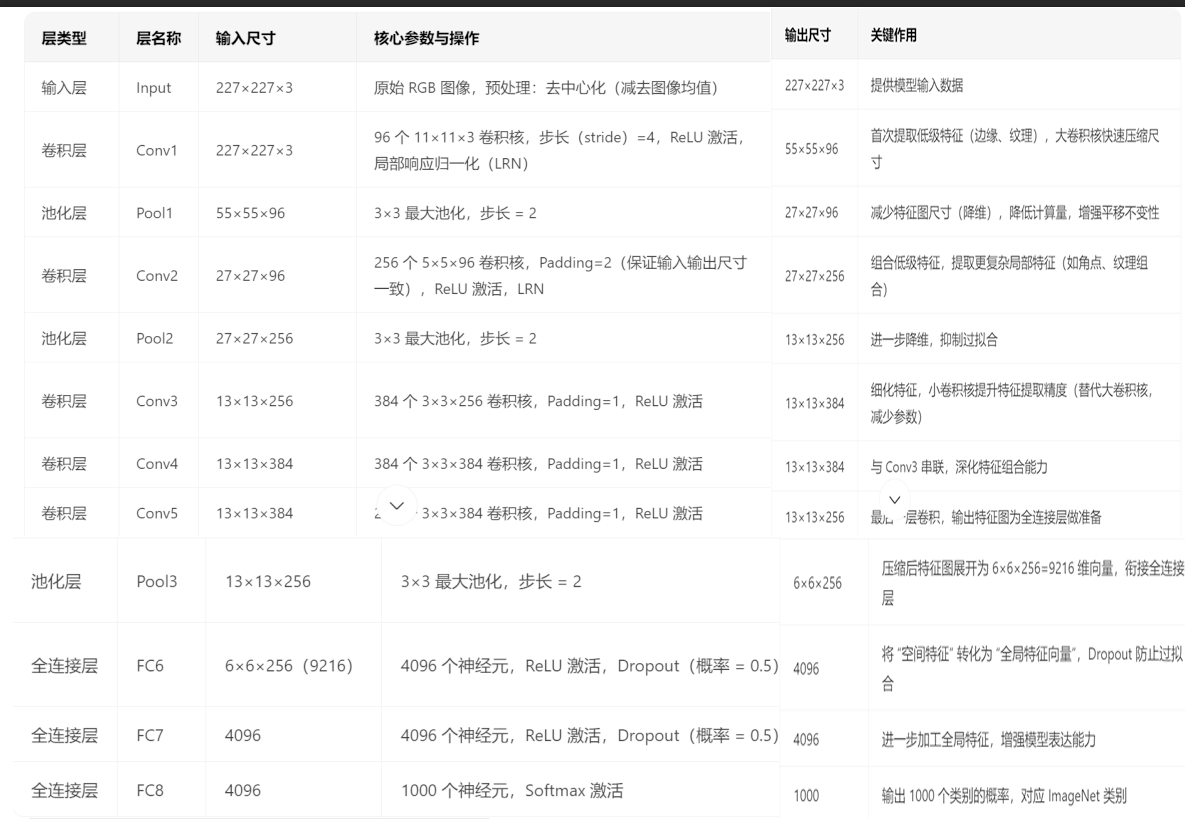
网络架构部分说明
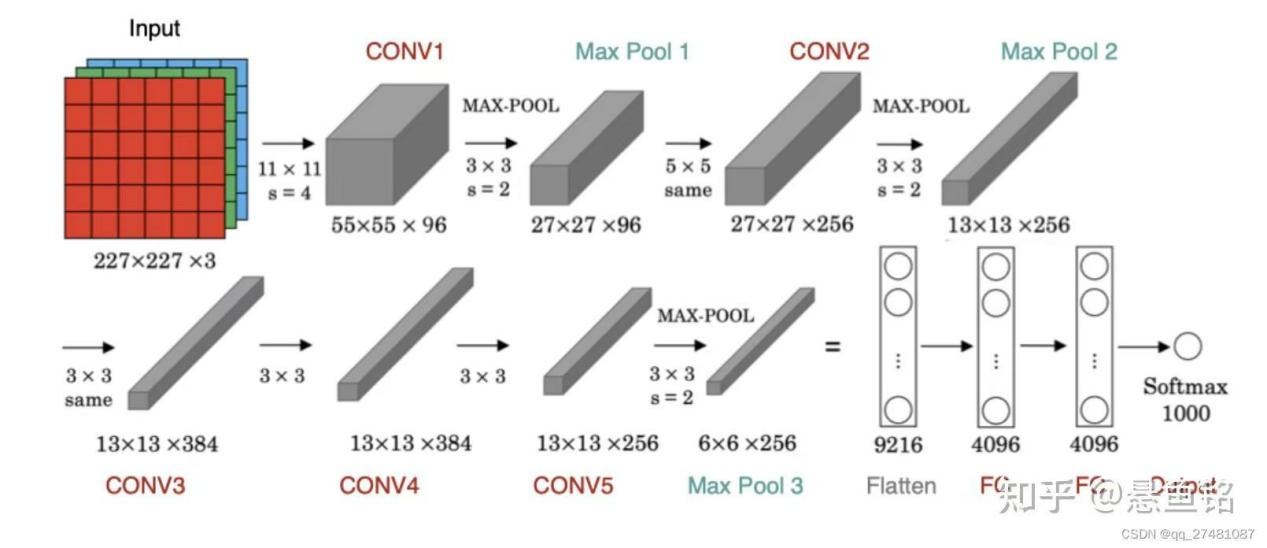
可以看到,中间经过了5个卷积层,3个最大池化层,和3个全连接层,以及还有输入和输出层。
输入层是224*224*3,实际因卷积细节调整为227*227*3,高和宽是227,通道是3;
经过了第一个卷积层,卷积核是11*11*3,步长为4,输出为55*55*96;(96个卷积核,即输出通道数)
经过了第一个最大池化层,3*3最大池化,步长为2,,输出27*27*96;(池化不改变通道数)
经过了第二个卷积层,卷积核是5*5*96,步长为2,输出为27*27*256;(256个卷积核,通道数增加)
经过了第二个最大池化层,3*3最大池化,步长为2,,输出13*13*256;
经过了第三个卷积层,卷积核是3*3*256,步长为1,输出为13*13*384;(384个卷积核,通道数增加)
经过了第四个卷积层,卷积核是3*3*384,步长为1,输出为13*13*384;
经过了第五个卷积层,卷积核是3*3*384,步长为1,输出为13*13*256;(256为卷积核数量,通道数减少,为后续全连接层做准备)
经过了第三个最大池化层,3*3最大池化,步长为2,,输出6*6*256;
经过了第一个全连接层(FC6),经过dropout函数,概率为0.5,输出是4096;(将9216维的输入映射到4096维的输出,4096是一个人为设置的超参数,折中设计,保留了足够的特征信息量,又降低计算量,防止了过拟合)
经过了第二个全连接层(FC7),经过dropout函数,概率为0.5,输出是4096;(dropout函数是暂时关闭一些神经元的输出,不会改变输出向量的维度,而维度由神经元数量决定)
经过了第三个全连接层(FC8),经过softmax函数激活,概率为0.5,输出是1000。(1000对应ImageNet数据集的1000个类别)
关键结构补充
- 双 GPU 并行训练:AlexNet 当时受限于 GPU 显存(单 GPU 仅 3GB),将网络拆分为两部分,分别在两个 GPU 上训练(如 Conv1 输出 96 通道,每个 GPU 处理 48 通道),训练完成后合并参数,这一设计也影响了后续并行计算的思路。
- ReLU 激活函数:首次在 CNN 中大规模使用 ReLU 替代传统的 Sigmoid/Tanh,解决了梯度消失问题(Sigmoid 在深层网络中梯度易趋近于 0),让深层网络的训练成为可能。
三、AlexNet 的核心创新点(奠定 CNN 设计范式)
AlexNet 的成功不仅在于 “深度”,更在于其突破性的设计思路,这些创新至今仍被后续网络沿用或改进:
1. ReLU 激活函数的引入
- 传统问题:Sigmoid 函数输出范围 [0,1],当输入绝对值较大时,导数趋近于 0,导致 “梯度消失”,深层网络无法训练。
- ReLU 优势:ReLU 函数(f (x)=max (0,x))在 x>0 时导数恒为 1,有效缓解梯度消失,且计算速度比 Sigmoid 快(无需指数运算)。
- 实验验证:AlexNet 论文中对比了 ReLU 与 Tanh,发现 ReLU 能让网络收敛速度提升 6 倍以上。
2. 局部响应归一化(LRN)
- 作用:模拟生物视觉系统的 “侧抑制” 机制,让同一位置不同通道的特征竞争,增强响应大的特征、抑制响应小的特征,提升泛化能力。
- 实现逻辑:对每个像素,在其相邻的 n 个通道内做归一化(如 Conv1 后用 LRN,n=5),公式为:
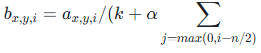 ,其中 k、α、β 为超参数(论文中 k=2,α=1e-4,β=0.75)。
,其中 k、α、β 为超参数(论文中 k=2,α=1e-4,β=0.75)。
- 后续发展:LRN 在 VGG 中被移除,后续更多用 Batch Normalization(BN)替代,但 LRN 是 “特征归一化” 的重要早期尝试。
3. Dropout 防过拟合
- 核心逻辑:训练时随机让 50% 的全连接层神经元失活(输出置 0),每个批次的网络结构都不同,避免神经元过度依赖某几个输入特征,降低过拟合风险。
- 注意点:测试时不使用 Dropout,而是将全连接层的权重乘以 0.5(或通过 “期望加权”),保证测试时的输出规模与训练时一致。
4. 数据增强(Data Augmentation)
-
AlexNet 的 3 种关键增强手段:
- 随机裁剪与翻转:将 256×256 的输入图随机裁剪为 227×227,同时随机水平翻转,让训练样本量间接扩大(仅裁剪就可产生 256×256/(3×3)≈7000 种样本)。
- 颜色抖动:在 RGB 颜色空间中,对每个通道的亮度、对比度、饱和度进行随机调整,增强模型对颜色变化的鲁棒性。
- PCA 颜色增强:对 ImageNet 数据集的所有图像计算 RGB 通道的协方差矩阵,随机加入微小的 PCA 扰动,模拟真实场景中的光照变化。
四、AlexNet 的训练细节与超参数
- 优化器:使用 SGD(随机梯度下降),动量系数 0.9,权重衰减(L2 正则)系数 1e-4,学习率初始为 1e-2,当验证集准确率停止提升时,学习率除以 10(共衰减 3 次)。
- 损失函数:交叉熵损失(Cross-Entropy Loss),适合多分类任务,公式为
其中 y 为真实标签(独热编码),p 为预测概率。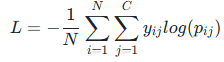
- ** batch size**:当时受 GPU 显存限制,每个 GPU 处理 128 个样本,总 batch size 为 256。
- 训练周期:在 ImageNet 上训练 90 个 epoch,约耗时 5-6 天(基于两块 GTX 580 GPU)。
五、AlexNet 的优缺点与后续影响
1. 优点
- 开创性:证明了深层 CNN 在大规模图像任务上的有效性,为计算机视觉奠定深度学习基础。
- 鲁棒性:通过 ReLU、Dropout、数据增强等手段,有效缓解梯度消失和过拟合,模型泛化能力强。
- 可迁移性:AlexNet 的卷积层能提取通用图像特征(如边缘、纹理、局部形状),后续可通过 “预训练 + 微调” 应用于小数据集任务(如人脸识别、目标检测)。
2. 缺点
- 参数量大:总参数量约 6000 万,对硬件要求较高(当时需双 GPU 训练),且推理速度较慢,难以部署到移动端。
- 结构冗余:全连接层(FC6、FC7)占总参数量的 80% 以上,很多参数并非必要,后续 VGG、ResNet 等通过 “减少全连接层”“用全局平均池化替代 FC” 优化。
- 对小目标不友好:大卷积核(如 11×11)虽能提取全局特征,但对小目标的细节捕捉能力较弱,后续网络(如 YOLO、Faster R-CNN)通过多尺度特征融合改进。
3. 后续影响
- 网络设计方向:推动卷积核从 “大尺寸” 向 “小尺寸” 发展(如 VGG 用 3×3 卷积核替代 11×11,提升特征提取精度且减少参数量)。
- 技术普及:让 ReLU、Dropout、数据增强成为 CNN 训练的 “标配”,Batch Normalization、残差连接等后续创新也基于 AlexNet 的框架衍生。
- 应用拓展:从图像分类延伸到目标检测(如 R-CNN 基于 AlexNet 预训练)、图像分割、人脸识别等领域,成为计算机视觉的 “基础模型”。

















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









