



 本文深入解析了Java集合HashMap的工作原理,包括其数据结构、哈希冲突处理方式以及核心方法的实现细节。HashMap采用数组加链表结构,通过哈希函数定位元素,利用链地址法解决冲突,提供高效的键值对存储。
本文深入解析了Java集合HashMap的工作原理,包括其数据结构、哈希冲突处理方式以及核心方法的实现细节。HashMap采用数组加链表结构,通过哈希函数定位元素,利用链地址法解决冲突,提供高效的键值对存储。
一、基础篇--1.2Java集合-HashMap源码解析
散列表
哈希表是根据关键码值而直接进行访问的数据结构。也就是说,它能通过把关键码值映射到表中的一个位置来访问。这个映射函数就叫做散列函数,存放记录的数组就叫散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1)。
哈希冲突
如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。前面我们提到过,哈希函数的设计至关重要,好的哈希函数会尽可能地保证计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式。
HashMap实现原理
HashMap的数据结构
HashMap的主干是一个Entry数组,Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对还有下一个节点,因此Entry是一个单向链表。代码如下:
static class Entry implements Map.Entry {
final K key;
V value;
Entry next;
int hash;
Entry(int h, K k, V v, Entry n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^
(value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
void recordAccess(HashMap m) {
}
void recordRemoval(HashMap m) {
}
}HashMap的整体结构如下图:
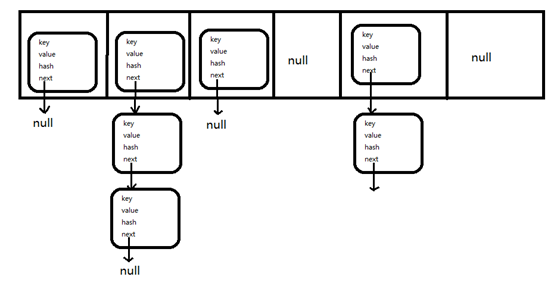
可以看出,HashMap是有数组和链表组成的,数组是HashMap的主体,链表是为了解决哈希冲突而存在的。由上面结构可以看出来,如果不存在链表,HashMap的查询修改删除性能都非常好,如果存在链表很多,即存在很多哈希冲突,则性能会降低很多,因为到指定位置后还要遍历整个链表。
HashMap源码分析
HashMap的继承关系
HashMap继承于AbstractMap,实现了Map<K,V>
java.lang.Object
↳ java.util.AbstractMap
↳ java.util.HashMap
public class HashMap
extends AbstractMap
implements Map, Cloneable, Serializable { }HashMap的关键属性
源码如下:
// 默认的初始容量是16,必须是2的幂。
static final int DEFAULT_INITIAL_CAPACITY = 16;
// 最大容量(必须是2的幂且小于2的30次方,传入容量过大将被这个值替换)
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/ 存储数据的Entry数组,长度是2的幂。
// HashMap是采用拉链法实现的,每一个Entry本质上是一个单向链表
transient Entry[] table;
// HashMap的大小,它是HashMap保存的键值对的数量
transient int size;
// HashMap的阈值,用于判断是否需要调整HashMap的容量(threshold = 容量*加载因子)
int threshold;
// 加载因子实际大小
final float loadFactor;
// HashMap被改变的次数,fail-fast用于快速抛出异常ConcurrentModificationException
transient int modCount;
static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE;
















 8396
8396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









