



大家好,我是飞哥!
最好有段时间没有更新文章了,原因是我在储备 GPU 方面的知识积累。等储备成形后给大家分享。今天还是继续给大家分享 Linux 内存底层原理。
在《从进程栈内存底层原理到Segmentation fault报错》一文中我们介绍了 Linux 的进程栈,今天我们再来聊聊线程栈的实现原理。
为什么要单独把线程栈拿出来说,这是因为线程栈和进程栈在实现上区别还是挺大的。
回顾下 Linux 的进程栈,它是一块在地址空间中专门的栈区域来表示的。进程在加载的时候就会调用将这块区域创建出来。
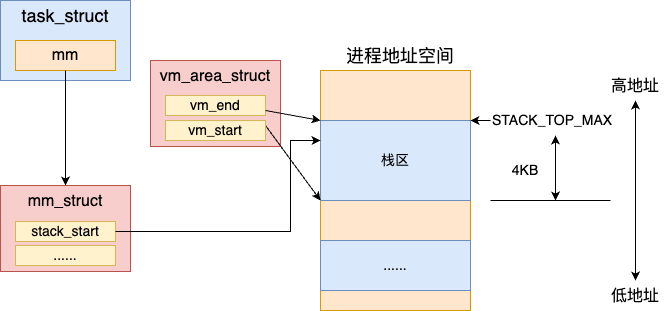
我们通过 cat /proc/{pid}/maps 可以查看到这块特殊的虚拟地址空间。
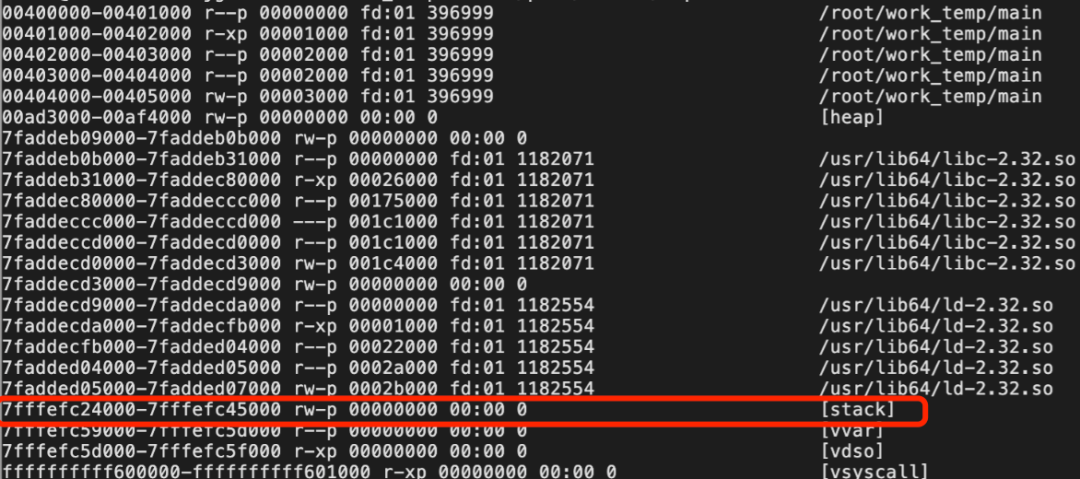
在聊聊Linux中线程和进程的联系与区别一文中我们了解了线程的创建过程。线程和创建它的进程是复用同一个地址空间的,也就是说同一个进程下的所有线程使用的都是同一块的内存。
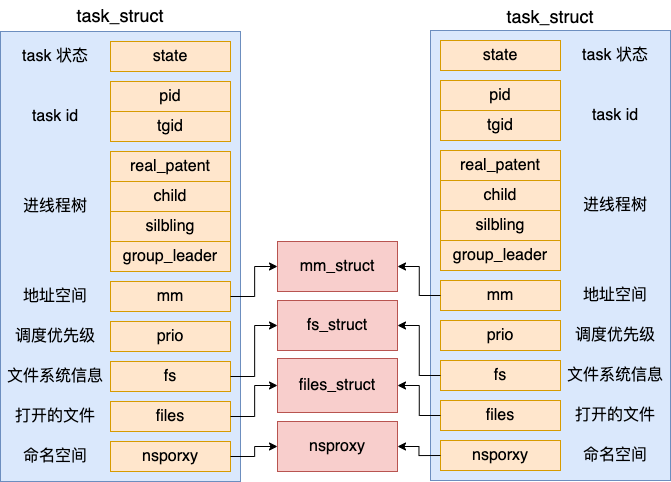
对于多线程程序而言,堆内存资源共享没问题。但是栈区必须是要独立的。但每一个线程为了保持独立的运行,是各自需要栈空间的。每个线程在并行调用的时候会在栈上独立地执行进栈和出栈,如果都使用进程地址空间中默认的 stack 区域,多线程跑起来就就乱套了。
所以,线程栈有自己独特的实现方法,我们今天就深入地了解一下。
一、关于 nptl 的故事
在 Linux 内核中,其实并没有线程的概念。内核原生的 clone 系统调用仅仅只是支持生成一个和父进程共享地址空间等资源的轻量级进程而已。
最早 LinuxThreads 项目希望在用户空间模拟对线程的支持。但不幸的是,这种方法有许多缺点,特别是在信号处理、调度和进程间同步原语等方面。另外,这种线程模型也没有符合 POSIX 标准。
为了改进 LinuxThreads,很明显需要做两方面的工作,一是在内核上提供支持,二是重写线程库。后来有两个改进 Linux 线程的工程被发起,一是 IBM 的 NGPT - Next-Generation POSIX Threads。另一个是 Red Hat 的 NPTL - Native POSIX Thread Library。IBM 在 2003 年的时候放弃了 NGPT,于是在改进 LinuxThreads 的路上就只剩下了 NPTL。
现在我们在 Linux 使用 pthread_create 来创建线程,其实就是使用的 NPTL。所以,在我们后面给大家展示线程源码时,会看到很多源文件所在的目录都是 nptl。
关于这段故事,大家可以看这篇经典的文章, http://cs.uns.edu.ar/~jechaiz/sosd/clases/extras/03-LinuxThreads%20and%20NPTL.pdf。 它详细讲述了 LinuxThreads 和 NPTL 的发展过程。
二、Linux 线程的实现
要想理解清楚 Linux 线程,首先要明确的是 Linux 线程是包含了两部分的实现。
第一部分是用户态的 glibc 库。我们创建线程调用的 pthread_create 就是在 glibc 库实现的。注意,glibc 库完全是在用户态运行的,并非内核源码。
第二部分是内核态的 clone 系统调用。内核通过 clone 系统调用可以创建出和父进程共享内存地址空间的轻量级用户进程。这一部分我们在聊聊Linux中线程和进程的联系与区别这篇文章中介绍的比较详细。
我们今天要讨论的线程栈,其实是在第一部分 - 用户态的 glibc 库中执行的。我们再次翻开 glibc 库中创建线程的 pthread_create 函数的源码,从源码中把线程栈内存原理展示给大家。
pthread_create 函数会调用到 __pthread_create_2_1。
//file:nptl/pthread_create.c
int
__pthread_create_2_1 (...)
{
...
//2.1 定义线程对象
struct pthread *pd;
//2.2 确定栈空间大小
//2.3 申请用户栈
err = ALLOCATE_STACK (iattr, &pd);
...
//创建用户进程
err = create_thread (pd, iattr, STACK_VARIABLES_ARGS);
}在这个函数中先是调用 ALLOCATE_STACK 为用户申请线程栈。然后通过 create_thread 来调用内核 clone 系统调用来创建线程。关于 clone 创建线程的过程参见聊聊Linux中线程和进程的联系与区别。
2.1 struct pthread
在开始看 ALLOCATE_STACK 之前我们得先说一下线程的核心数据结构 pthread。
前面我们说过线程资源分为两部分,一部分是内核资源,例如代表轻量级进程的内核对象 task_struct。另一部分是用户态内存资源,包含线程栈。
用户资源这一部分的数据结构就是 struct pthread。它存储了线程的相关信息,包括线程栈。每个 pthread 对象都唯一对应一个线程。
//file:nptl/descr.h
struct pthread
{
pid_t tid;
......
//线程栈内存
void *stackblock;
size_t stackblock_size;
}在 pthread 结构体的 tid 对象中存储了线程的 ID 值。在 stackblock 中指向了线程栈内存,stackblock_size 表明栈内存区域的大小。
2.2 确定栈空间大小
了解了 struct pthread 后,我们来看 ALLOCATE_STACK 是如何申请栈内存的。ALLOCATE_STACK 是一个宏,最终会调用到 allocate_stack 函数。
//file:nptl/allocatestack.c
static int
allocate_stack (const struct pthread_attr *attr, struct pthread **pdp,
ALLOCATE_STACK_PARMS)
{
//确定栈空间大小
size = attr->stacksize ?: __default_stacksize;
//申请栈内存
...
}如果用户指定了栈的大小,则使用用户指定的值。如果没有指定就使用确定的大小 __default_stacksize。其中在 init.c 文件中,我搜到了 __default_stacksize 设置值的过程。
//file:nptl/init.c
void __pthread_initialize_minimal_internal (void){
//确定缺省栈内存空间大小
if (getrlimit (RLIMIT_STACK, &limit) != 0
|| limit.rlim_cur == RLIM_INFINITY){
__default_stacksize = ARCH_STACK_DEFAULT_SIZE;
} else if (limit.rlim_cur < PTHREAD_STACK_MIN){
__default_stacksize = PTHREAD_STACK_MIN;
} else {
__default_stacksize = (limit.rlim_cur + pagesz - 1) & -pagesz;
}
}这段代码逻辑中,首先处理的是 ulimit 没有配置或者配置不合理的情况。
如果没有 ulimit 没有配置或者配置的是无限大,那么就配置的大小是 ARCH_STACK_DEFAULT_SIZE (32 MB)。
如果用户手残配置的太小了,可能会导致程序无法正常运行,所以 glibc 库最小也会给一个 PTHREAD_STACK_MIN 大小(16384 字节)。
关于这两个宏的定义位置如下:
//file:/usr/include/limits.h
#define PTHREAD_STACK_MIN 16384
//file:nptl/sysdeps/ia64/pthreaddef.h
#define ARCH_STACK_DEFAULT_SIZE (32 * 1024 * 1024)在 ulimit 配置合理的情况下,将取到的配置值对齐一下就直接用了。
2.3 申请用户栈
在确定了栈空间大小后,就可以开始申请内存了。
//file:nptl/allocatestack.c
static int
allocate_stack (const struct pthread_attr *attr, struct pthread **pdp,
ALLOCATE_STACK_PARMS)
{
size = attr->stacksize ?: __default_stacksize;
......
struct pthread *pd;
pd = get_cached_stack (&size, &mem);
if (pd == NULL){
mem = mmap (NULL, size, prot,
MAP_PRIVATE | MAP_ANONYMOUS | ARCH_MAP_FLAGS, -1, 0);
pd = (struct pthread *) ((((uintptr_t) mem + size - coloring
- __static_tls_size)
& ~__static_tls_align_m1)
- TLS_PRE_TCB_SIZE);
pd->stackblock = mem;
pd->stackblock_size = size;
......
}
//添加到全局在用栈的链表中
list_add (&pd->list, &stack_used);
...
}在申请栈内存前,首先尝试通过 get_cached_stack 获取一块缓存直接用,以避免频繁地对内存申请和释放。我们先忽略这段逻辑。
假设没有取到缓存,就使用 mmap 系统调用直接申请一块匿名页内存空间。 这就是线程栈内存和进程栈内存的区别,进程栈直接使用的是启动进程时创建的 stack 。但是线程是使用 mmap 在用户态来申请的。
我们接下来再稍微看看 glibc 是如何使用这块内存的。
在申请到内存后,mem 指针指向是新内存的低地址。通过 mem 和 size 算出高地址空间后,经过复杂的地址预留策略,例如对齐等,把 struct pthread 给放了上去。
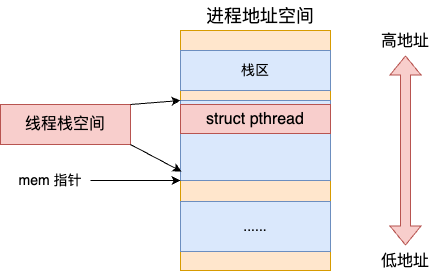
所以线程栈内存是由两个用途的,一个是存储线程栈对象 struct pthread,另一个是真正当做线程栈内存来用。
2.4 栈的释放
Glibc 中的每个线程在结束阶段都会做一个公共的操作,即释放那些已结束线程的栈内存。Glibc 在线程结束阶段(线程仍活着)将自己的内存块从 stack_used 移除,放入 stack_cache 链表中。
三、总结
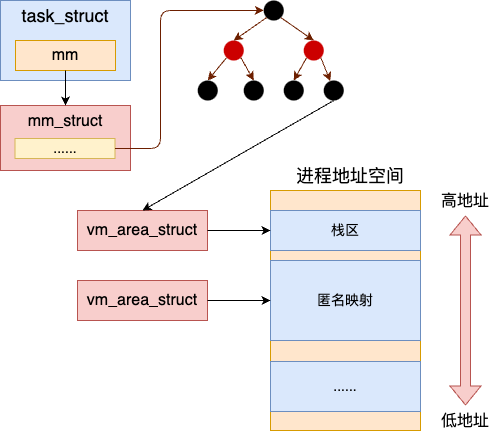
每个线程都需要有独立的栈,来保证并发调度时不冲突。然而进程地址空间的默认栈由于多个 task_struct 所共享的,所以线程必须通过 mmap 来独立管理自己的栈。
Linux 中 glibc 中的线程库其实是 nptl 线程。它包含了两部分的资源。第一部分是在用户态管理了用户态的线程对象 struct pthread,以及独立的线程栈。第二部分就是内核中的 task_struct,地址空间等内核对象。进程栈和线程栈的关系如下图所示。
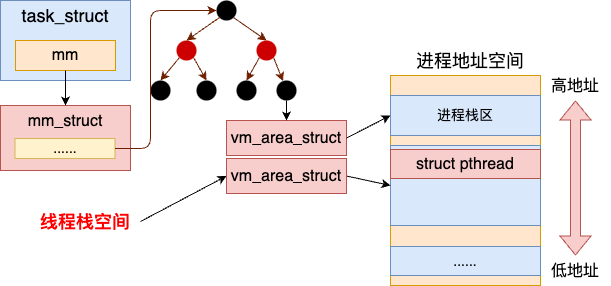
有了这块栈内存后,你在写代码中申请的局部变量就有了落脚之地了。
#include <stdio.h>
void funcA()
{
int n = 0;
...
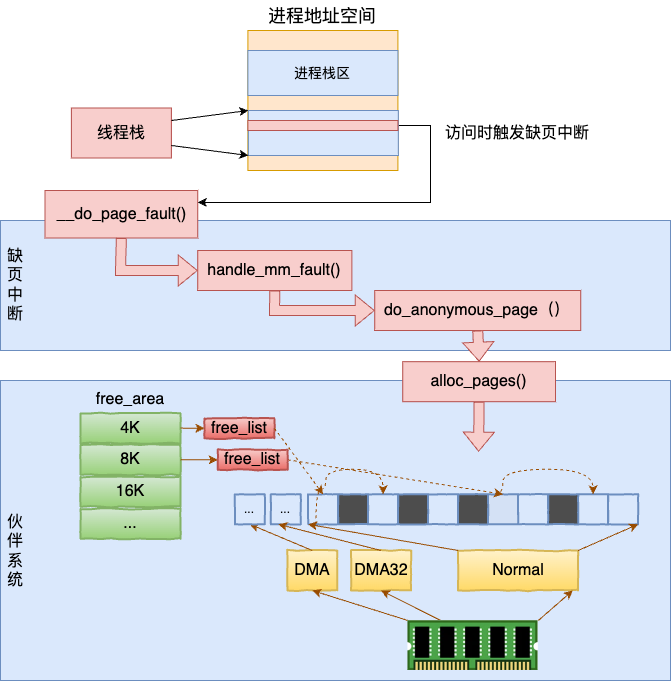
}当然了,本文介绍了半天的线程栈地址空间,仍然围绕的是虚拟地址空间来介绍的。并没有涉及物理内存的申请和访问。真正的物理内存还仍然是在真正访问的时候发生缺页中断,缺页的时候通过伙伴系统来申请的。
本文摘自飞哥的技术专著《深入理解Linux进程与内存》。也欢迎大家入手高质量印刷的纸质书观看!

















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









