




 本文围绕后端接口性能指标中的接口耗时,讲述了TCP握手相关的异常情况。包括端口不足导致CPU开销上涨、第一次握手半/全连接队列满丢包、第三次握手全连接队列满丢包等问题,还给出了打开syncookie、加大连接队列长度等应对方法。
本文围绕后端接口性能指标中的接口耗时,讲述了TCP握手相关的异常情况。包括端口不足导致CPU开销上涨、第一次握手半/全连接队列满丢包、第三次握手全连接队列满丢包等问题,还给出了打开syncookie、加大连接队列长度等应对方法。
大家好,我是飞哥!
在后端接口性能指标中一类重要的指标就是接口耗时。具体包括平均响应时间 TP90、TP99 耗时值等。这些值越低越好,一般来说是几毫秒,或者是几十毫秒。如果响应时间一旦过长,比如超过了 1 秒,在用户侧就能感觉到非常明显的卡顿。如果长此以往,用户可能就直接用脚投票,卸载我们的 App 了。
在正常情况下一次 TCP 连接耗时也就大约是一次 RTT 多一点。但事情不一定总是这么美好,总会有意外发生。在某些情况下,可能会导致连接耗时上涨、CPU 处理开销增加、甚至是超时失败。
今天飞哥就来说一下我在线上遇到过的那些 TCP 握手相关的各种异常情况。
一、客户端 connect 异常
端口号和 CPU 消耗这二者听起来感觉没啥太大联系。但我却遭遇过因为端口号不足导致 CPU 消耗大幅上涨的情况。来听飞哥分析分析为啥会出现这种问题!
客户端在发起 connect 系统调用的时候,主要工作就是端口选择(参见TCP连接中客户端的端口号是如何确定的?)。
在选择的过程中,有个大循环,从 ip_local_port_range 的一个随机位置开始把这个范围遍历一遍,找到可用端口则退出循环。如果端口很充足,那么循环只需要执行少数几次就可以退出。但假设说端口消耗掉很多已经不充足,或者干脆就没有可用的了。那么这个循环就得执行很多遍。我们来看下详细的代码。
//file:net/ipv4/inet_hashtables.c
int __inet_hash_connect(...)
{
inet_get_local_port_range(&low, &high);
remaining = (high - low) + 1;
for (i = 1; i <= remaining; i++) {
// 其中 offset 是一个随机数
port = low + (i + offset) % remaining;
head = &hinfo->bhash[inet_bhashfn(net, port,
hinfo->bhash_size)];
//加锁
spin_lock(&head->lock);
//一大段的选择端口逻辑
//......
//选择成功就 goto ok
//不成功就 goto next_port
next_port:
//解锁
spin_unlock(&head->lock);
}
}
在每次的循环内部需要等待锁,以及在哈希表中执行多次的搜索。注意这里的是自旋锁,是一种非阻塞的锁,如果资源被占用,进程并不会被挂起,而是会占用 CPU 去不断尝试获取锁。
但假设端口范围 ip_local_port_range 配置的是 10000 - 30000, 而且已经用尽了。那么每次当发起连接的时候都需要把循环执行两万遍才退出。这时会涉及大量的 HASH 查找以及自旋锁等待开销,系统态 CPU 将会出现大幅度的上涨。
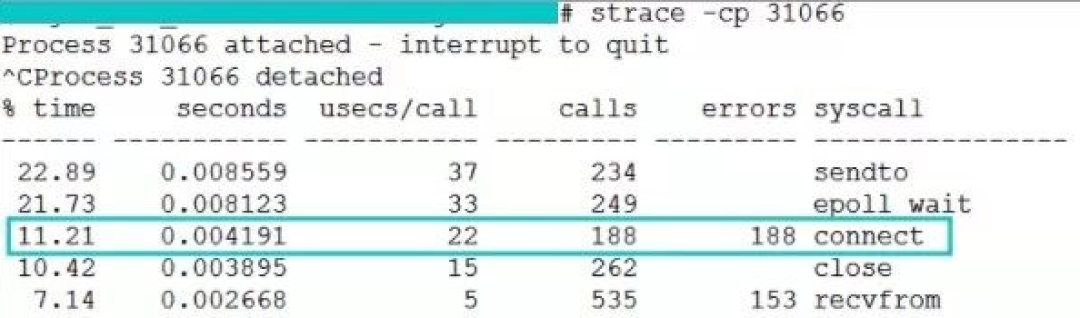
这是线上截取到的正常时的 connect 系统调用耗时,是 22 us(微秒)。
这个是我们一台服务器在端口不足情况下 connect 开销,是 2581 us(微秒)。
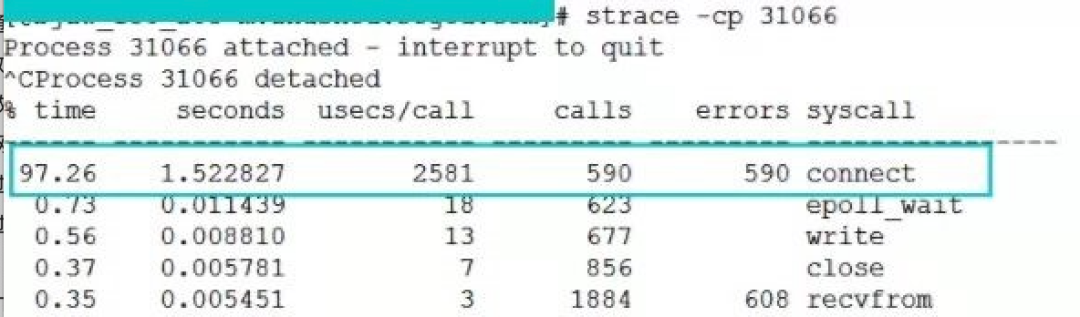
从上两张图中可以看出,异常情况下的 connect 耗时是正常情况下的 100 多倍。虽然换算成毫秒只有 2 ms 多一点,但是要知道这消耗的全是 CPU 时间。
二、第一次握手丢包
服务器在响应来自客户端的第一次握手请求的时候,会判断一下半连接队列和全连接队列是否溢出。如果发生溢出,可能会直接将握手包丢弃,而不会反馈给客户端。接下来我们分别来详细看一下。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1278
1278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









