




 本文详细介绍了Cloudera的Flume日志采集系统,包括其高可用、高可靠的特点,以及如何通过agent实现数据从source到sink的传输过程。深入解析了Flume的运行机制、核心组件和事件(event)的概念,同时提供了Flume的安装部署步骤和使用案例。
本文详细介绍了Cloudera的Flume日志采集系统,包括其高可用、高可靠的特点,以及如何通过agent实现数据从source到sink的传输过程。深入解析了Flume的运行机制、核心组件和事件(event)的概念,同时提供了Flume的安装部署步骤和使用案例。
1.概述
- Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采
集、聚合和传输的软件。 - Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到
指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,
会先缓存数据(channel),待数据真正到达目的地(sink)后,flume 在删除自己缓
存的数据。
2.运行机制
Flume 系统中核心的角色是 agent,agent 本身是一个 Java 进程,一般运行
在日志收集节点。
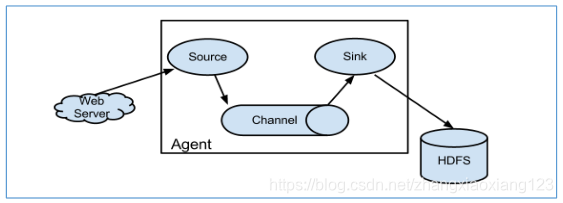 每一个 agent 相当于一个数据传递员,内部有三个组件:
每一个 agent 相当于一个数据传递员,内部有三个组件:
Source:采集源,用于跟数据源对接,以获取数据;
Sink:下沉地,采集数据的传送目的,用于往下一级 agent 传递数据或者往
最终存储系统传递数据;
Channel:agent 内部的数据传输通道,用于从 source 将数据传递到 sink;
在整个数据的传输的过程中,流动的是 event,它是 Flume 内部数据传输的
最基本单元。event 将传输的数据进行封装。如果是文本文件,通常是一行记录,
event 也是事务的基本单位。event 从 source,流向 channel,再到 sink,本身
为一个字节数组,并可携带 headers(头信息)信息。event 代表着一个数据的最
小完整单元,从外部数据源来,向外部的目的地去。
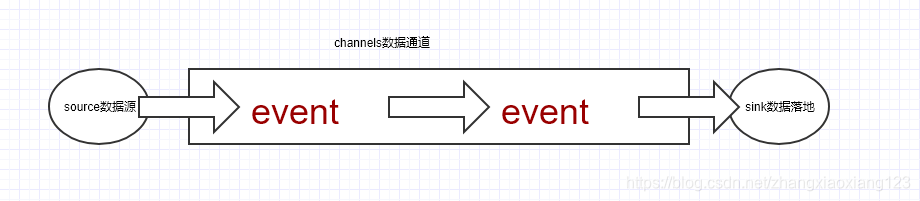
一个完整的 event 包括:event headers、event body、event 信息,其中
event 信息就是 flume 收集到的日记记录
3.Flume 采集系统结构图
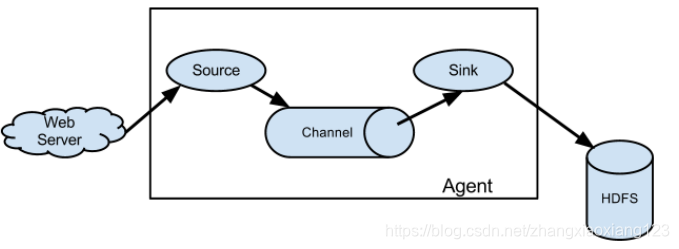
3.1简单结构
单个 agent 采集数据
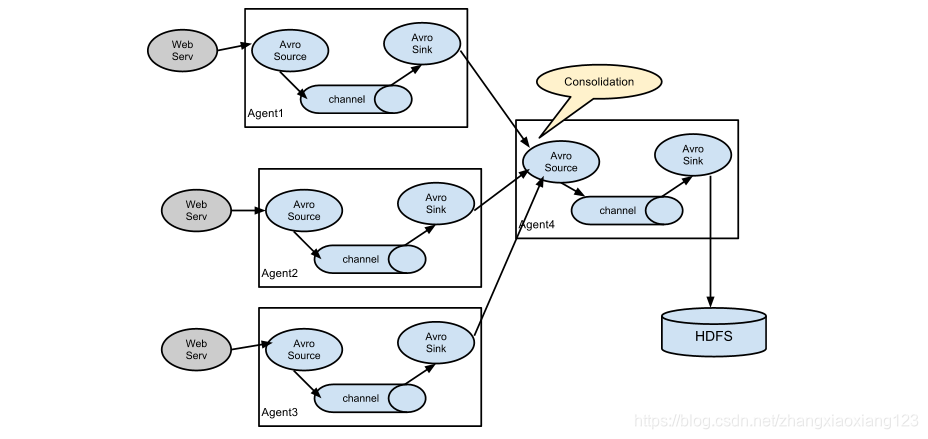
3.2多对一采集(合并采集)
3.3一对多(复用采集)
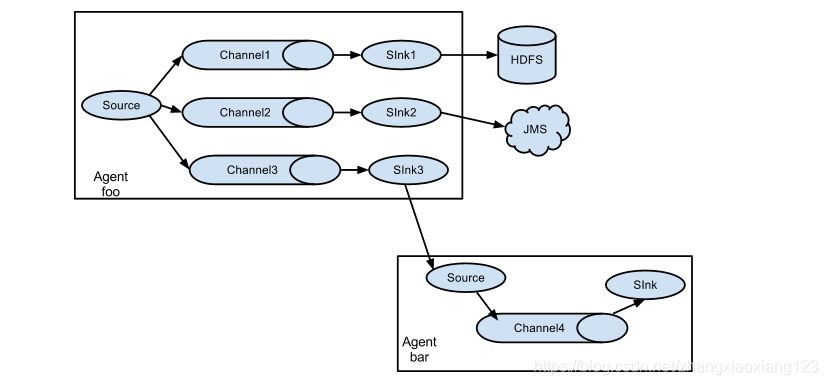
4.Flume 安装部署
- Flume 的安装非常简单
上传安装包到数据源所在节点上
然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz
然后进入 flume 的目录,修改 conf 下的 flume-env.sh,在里面配置 JAVA_HOME
4.1Flume使用
- 根据数据采集需求 配置采集方案,描述在配置文件中(文件名可任意自定义)
- 指定采集方案配置文件,在相应的节点上启动 flume agent
4.2Flume案例
针对一对一,一对多,多对一我这里分别一一展示。
未完待续

















 291
291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









