




 本文深入解析线程池的概念、工作原理及其在Java中的实现。介绍了线程池如何通过复用线程减少资源开销,探讨了核心线程数、最大线程数等关键参数的作用,以及不同线程池类型的特点。同时,对比了execute和submit方法的区别。
本文深入解析线程池的概念、工作原理及其在Java中的实现。介绍了线程池如何通过复用线程减少资源开销,探讨了核心线程数、最大线程数等关键参数的作用,以及不同线程池类型的特点。同时,对比了execute和submit方法的区别。
线程池
定义
1. 线程池是什么?
线程池顾名思义就是事先创建若干个可执行的线程放入一个池(容器)中,需要的时候从池中获取线程不用自行创建,使用完毕不需要销毁线程而是放回池中,从而减少创建和销毁线程对象的开销。
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。
多线程的异步执行方式,虽然能够最大限度发挥多核计算机的计算能力,但是如果不加控制,反而会对系统造成负担。线程本身也要占用内存空间,大量的线程会占用内存资源并且可能会导致Out of Memory。即便没有这样的情况,大量的线程回收也会给GC带来很大的压力。
为了避免重复的创建线程,线程池的出现可以让线程进行复用。通俗点讲,当有工作来,就会向线程池拿一个线程,当工作完成后,并不是直接关闭线程,而是将这个线程归还给线程池供其他任务使用。
使用
1. 线程池创建
线程池概念来源于Java中的Executor,它是一个接口,还有一个子类接口ExecutorService,一个抽象类AbstractExecutorService,真正的实现类为ThreadPoolExecutor。ThreadPoolExecutor的构造函数提供了一系列参数来配置线程池。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
下面解释这些参数的含义:
1. corePoolSize:
核心池的大小,这个参数跟后面讲述的线程池的实现原理有非常大的关系。在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法的名字就可以看出,是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中。
2. maximumPoolSize:
线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程。
3. keepAliveTime: 表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0。
3. unit:
TimeUnit枚举类型的值,代表keepAliveTime时间单位,可以取下列值:
TimeUnit.DAYS; //天
TimeUnit.HOURS; //小时
TimeUnit.MINUTES; //分钟
TimeUnit.SECONDS; //秒
TimeUnit.MILLISECONDS; //毫秒
TimeUnit.MICROSECONDS; //微妙
TimeUnit.NANOSECONDS; //纳秒
4. workQueue: 一个阻塞队列,用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响,一般来说,这里的阻塞队列有以下几种选择
ArrayBlockingQueue;
LinkedBlockingQueue;
SynchronousQueue;
ArrayBlockingQueue和PriorityBlockingQueue使用较少,一般使用LinkedBlockingQueue和Synchronous。线程池的排队策略与BlockingQueue有关。
5. threadFactory: 线程工厂,是用来创建线程的。默认new Executors.DefaultThreadFactory();
6. handler: 线程拒绝策略。当创建的线程超出maximumPoolSize,且缓冲队列已满时,新任务会拒绝,有以下取值:
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
Java通过Executors工厂类提供四种线程池,分别为:
- newCachedThreadPool
可缓存线程池,先查看池中有没有以前建立的线程,如果有,就直接使用。如果没有,就建一个新的线程加入池中,缓存型池子通常用于执行一些生存期很短的异步型任务
// 可缓存线程池
ExecutorService threadPool = Executors.newCachedThreadPool();
threadPool.execute(mTestRunnable);
- newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
// 创建一个可重用固定个数的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(3);
threadPool.execute(mTestRunnable);
- newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
// 定长线程池
ScheduledExecutorService threadPool = Executors.newScheduledThreadPool(5);
println("定时执行");
threadPool.schedule(mTestRunnable, 1, TimeUnit.SECONDS);
- newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
例如:
public static void main(String[] args) {
//
ExecutorService threadPool=Executors.newSingleThreadExecutor();
threadPool.execute(mTestRunnable);
}
private static Runnable mTestRunnable=new Runnable() {
@Override
public void run() {
println("测试线程池-----");
}
};
可以看到线程池的使用还是很简单的。关键还是要搞清楚其实现原理。
2. 为什么阿里巴巴开发手册不推荐使用Executors提供的静态工厂方法创建线程池?

3. 线程池的关闭
ThreadPoolExecutor提供了两个方法,用于线程池的关闭,分别是shutdown()和shutdownNow(),其中:
shutdown():不会立即终止线程池,而是要等所有任务缓存队列中的任务都执行完后才终止,但再也不会接受新的任务
shutdownNow():立即终止线程池,并尝试打断正在执行的任务,并且清空任务缓存队列,返回尚未执行的任务
原理
1. 线程池是怎么实现复用线程的?
线程池中长期驻留了一定数量的活线程,当任务需要执行时,我们不必先去创建线程,线程池会自己选择利用现有的活线程来处理任务。
很显然,线程池一个很显著的特征就是“长期驻留了一定数量的活线程”,避免了频繁创建线程和销毁线程的开销,那么它是如何做到的呢?我们知道一个线程只要执行完了run()方法内的代码,这个线程的使命就完成了,等待它的就是销毁。既然这是个“活线程”,自然是不能很快就销毁的
在分析源码之前先来思考一下要怎么去分析,源码往往是比较复杂的,如果知识储备不够丰厚,很有可能会读不下去,或者读岔了。一般来讲要时刻紧跟着自己的目标来看代码,跟目标关系不大的代码可以不理会它,一些异常的处理也可以暂不理会,先看正常的流程。就我们现在要分析的源码而言,目标就是看看线程是如何被复用的
先重构造函数看起:
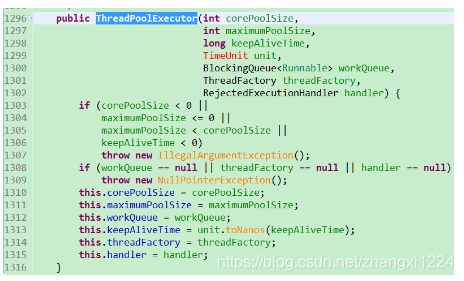
ThreadPoolExecutor这个是线程池的实现类。里面的字段含义上面已经解释过了。这里再简单回顾下
- corePoolSize 核心线程数
- maximumPoolSize 最大线程数
- workqueue 工作队列-其实就是任务队列
- keepAliveTime 非核心线程存活的最大时间
- threadFactory 线程创建工厂类
- handler 异常处理类
比较难理解的就是workqueue 其实它是BlockingQueue 这个是阻塞队列。从队列中读取数据如果队列为空,那么此线程会挂起等待 直到读取数据。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6Li6D1wW-1578457156011)(A832F72EB77C49329B367C4B9CB6B857)]](https://i-blog.csdnimg.cn/blog_migrate/7b0f7b4b6f350cec985d33b7a6cb8517.png)
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
字段ctl是对线程池的运行状态和线程池中有效线程的数量进行控制的, 它包含两部分信息: 线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount)。这里是采用的位运算。AtomicInteger是保证原子操作。大家可以运行看看结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VtnnjsEr-1578457156012)(BA96EA461E5B45F889E7DBD169E3B039)]](https://i-blog.csdnimg.cn/blog_migrate/ab25d732ee1e7d47a77f986f2f0f9e07.png)
接着看execute方法:
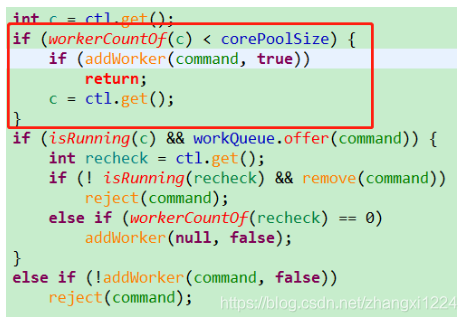
我们先看红色框的判断,如果当前工作线程数量小于核心数量,则去添加工作线程。那我们看addWorker.
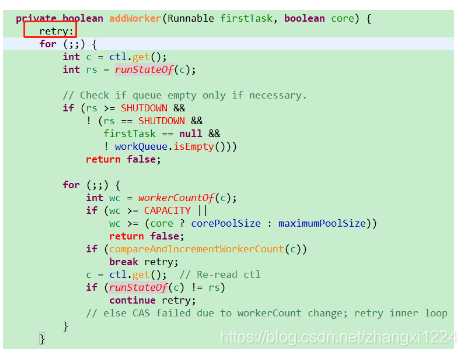
首先这里有个retry:这相当于一个goto语句。正常 break和continue就退出了,但是这个就是退到 retry处 开始。可以简单写一个测试一下。
首先检测线程池运行状态。
然后检测线程池中的工作线程数量
这里用了CAS保证线程同步问题。继续往下看

创建一个工作线程Worker 并且把任务传递进去。
ReentrantLock锁 同步操作
检测运行状态
把工作线程添加进入workers.

这个workers就是线程池中的池 存储工作线程。数据结构是hashset。
然后调用start启动工作线程。
接着就进入了工作线程的run方法。这个方法其实就是worker类中的run方法。


其实只要英语好的,值看这个方法的注释就知道这个方法在干嘛了。
这里开启了一个无限循环处理任务。
如果task不为空就直接 回调 task的run方法。
如果为空则去队列中取出getTask();
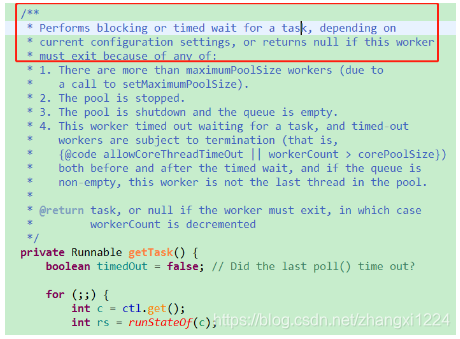
红框说的很清楚,执行阻塞 或者 定时等待任务 或者返回null。
如果返回null 那么循环就退出了,线程就算是销毁了。阻塞就会一直等待任务。

关键就是这个 poll和take 方法是不同的。take会一直阻塞,poll是定时。
到此为止,其实原理已经比较清楚了。池就是hashset。里面维护了一些 线程 他们的run方法中 开启无线循环 从阻塞队列中取任务,有就执行,没有就阻塞。execute方法就根据当前的情况是 创建新的工作线程,还是往队列中添加任务。
2. execute和submit有什么区别?
submit方法是ExecutorService接口中定义的。execute方法是Executor接口中定义的。ExecutorService是Executor的子类

submit方法的实现在AbstractExecutorService抽象类中。

和execute 区别不大,多了结果回调。对应上面线程创建的第三种方式。
总结
-
所谓线程池本质是一个hashSet。多余的任务会放在阻塞队列中。
-
只有当阻塞队列满了后,才会触发非核心线程的创建。所以非核心线程只是临时过来打杂的。直到空闲了,然后自己关闭了。
-
线程池提供了两个钩子(beforeExecute,afterExecute)给我们,我们继承线程池,在执行任务前后做一些事情。
-
线程池原理关键技术:锁(lock,cas)、阻塞队列、hashSet(资源池)、位运算、同步


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









