






 本文介绍了深度学习推荐模型(DLRM)的设计,它结合了推荐系统中的embedding技术和预测分析中的多层感知器(MLP),用于处理分类和稠密特征。DLRM通过交叉不同特征来预测事件概率,并将在PyTorch和Caffe2中开源。
本文介绍了深度学习推荐模型(DLRM)的设计,它结合了推荐系统中的embedding技术和预测分析中的多层感知器(MLP),用于处理分类和稠密特征。DLRM通过交叉不同特征来预测事件概率,并将在PyTorch和Caffe2中开源。
个性化推荐系统现在应用于很多大的网络公司的任务中,包括广告的ctr预测和排序。尽管这些方法已经有了很久的历史,但是这些方法只是进来才有神经网络的。针对个性化推荐的深度学习模型的结构设计主要两个方面的贡献。
第一个来自推荐系统的观点。这些系统最初使用content filtering,一些专家将产品分类,用户选择他们喜欢的类别,然后基于他们的喜好匹配。该领域后来发展到使用collaborative filtering,基于用户过去的行为推荐,例如之前对给定的产品的评级。通过将用户和产品分组来提供推荐的neighborhood 方法,和通过矩阵分解技术的某些隐含因素来描述用户和产品的latent factor方法 后来得到了成功的应用。
第二个观点来自预测分析,通过统计模型来分类或预测基于给定的数据事件发生的概率。预测模型从使用简单的模型如线性和逻辑回归模型转向包含深层网络的模型。为了处理分类数据,这些模型采用了embeddings技术,将one-和multi-hot向量转变到抽象空间的稠密表达。这个抽象空间可以解释为推荐系统发现的潜在因素的空间。
在本文中,我们介绍了一个个性化模型,用上边描述的两个方面的结合来构造的。该模型用embeddings来处理表示分类数据的稀疏特征,用MLP来处理稠密特征,然后将这些特征显示的用24中的统计技术进行交叉。最后通过另一个MLP后处理交叉结果来找到事件概率。我们将这个模型成为DLRM。这个模型的PyTorch和Caffe2实现的将开源用于测试和实验。
2、模型设计和结构
在这部分,我们将描述DLRM的设计。
我们将从网络的高水平的组件开始,解释how和why他们以这种特定的方式组合在一起,来启发将来的模型设计。
然后描述低级别的组成模型的操作和器件,来启发将来的硬件和系统设计。
2.1、DLRM的组件
DLRM的高级别组件可以通过回顾以前的方法更容易的理解。我们将避免全面的科学文献回顾,相反关注早期模型中的四种技术,可以解释DLRM的高级别组件。
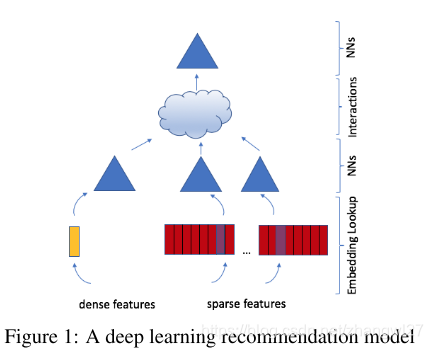
2.1.1 Embeddings
为了处理分类数据,嵌入向量将每个分类映射到抽象空间的稠密表达。

















 2164
2164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









