目录
一、Kafka
二、消息队列和Kafka
三、为什么选择Kafka
1、kafka可以无缝支持多个生产者,不管客户端在使用单个主题还是多个主题。
2、Kafka支持多个消费者从一个单独的消息流上读取数据,而且消费者之间互不影响。
3、Kafka基于磁盘的数据存储
4、Kafka的伸缩性
5、Kafka的高性能
四、Kafka的大数据生态系统
五、Kafka使用场景
1、活动追踪
2、传递消息
3、度量指标和日志记录
4、提交日志
5、流处理
一、Kafka
Kafka是一个流平台:在这个平台上可以发布订阅数据流,并把它们保存起来、进行处理。
作为一个现代分布式系统,kafka以集群的方式运行,可以自由伸缩,处理公司的所有应用程序。
Kafka一般被称为 “分布式提交日志”或者“分布式流平台”。文件系统或数据库提交日志用来提供所有事务 的持久记录,通过重放这些日志可以重建系统的状态。同样地,Kafka
的数据是按照一定 顺序持久化保存的,可以按需读取。此外,Kafka
的数据分布在整个系统里,具备数据故 障保护和性能伸缩能力。
二、消息队列和Kafka
消息系统只会传递消息,而kafka的流失处理能力让你可以让你只用很少的代码就可以动态处理派生流和数据集。
消息队列允许一组订阅者从队列的末尾提取一条或多条消息。在消息被移除之前,队列通常允许执行某些级别的事务,以确保在消息被删除之前执行所需的操作。并不是所有的队列系统都具有相同的功能,但是一旦消息被处理了,就会从队列中删除掉。
尽管可以在队列中扩展多个消费者,但它们都包含相同的功能,而这只是为了处理负载和并行处理消息,换句话说,它不允许你基于相同的事件启动多个独立的操作。队列消息的所有处理器将在相同的域中执行相同类型的逻辑。这意味着队列中的消息实际上是命令,它适合于命令式编程,而不是一个适合于响应式编程的事件。
Kafka,你可以将消息/事件发布到主题上,它们会被持久化。当消费者收到这些消息时,他们也不会被移除掉。这允许你重放消息,但更重要的是,它允许大量的消费者基于相同的消息/事件处理各自不同逻辑。
三、为什么选择Kafka
1、kafka可以无缝支持多个生产者,不管客户端在使用单个主题还是多个主题。
Kafka
可以无缝地支持多个生产者,不管客户端在使用单个主题还是多个主题。所以它很 适合用来从多个前端系统收集数据,并以统一的格式对外提供数据。例如,一个包含了多 个微服务的网站,可以为页面视图创建一个单独的主题,所有服务都以相同的消息格式向 该主题写入数据。消费者应用程序会获得统一的页面视图,而无需协调来自不同生产者的 数据流
2、Kafka支持多个消费者从一个单独的消息流上读取数据,而且消费者之间互不影响。
除了支持多个生产者外,Kafka 也支持多个消费者从一个单独的消息流上读取数据,而且 消费者之间互不影响。这与其他队列系统不同,其他队列系统的消息一旦被一个客户端读 取,其他客户端就无法再读取它。另外,多个消费者可以组成一个群组,它们共享一个消息流,并保证整个群组对每个给定的消息只处理一次。
3、Kafka基于磁盘的数据存储
Kafka
不仅支持多个消费者,还允许消费者非实时地读取消息,这要归功于
Kafka
的数据 保留特性。消息被提交到磁盘,根据设置的保留规则进行保存。每个主题可以设置单独的 保留规则,以便满足不同消费者的需求,各个主题可以保留不同数量的消息。消费者可能 会因为处理速度慢或突发的流量高峰导致无法及时读取消息,而持久化数据可以保证数据 不会丢失。消费者可以在进行应用程序维护时离线一小段时间,而无需担心消息丢失或堵 塞在生产者端。消费者可以被关闭,但消息会继续保留在 Kafka
里。消费者可以从上次中 断的地方继续处理消息。
4、Kafka的伸缩性
为了能够轻松处理大量数据,
Kafka
从一开始就被设计成一个具有灵活伸缩性的系统。用 户在开发阶段可以先使用单个 broker
,再扩展到包含
3
个
broker
的小型开发集群,然后随 着数据量不断增长,部署到生产环境的集群可能包含上百个 broker
。对在线集群进行扩展 丝毫不影响整体系统的可用性。也就是说,一个包含多个 broker
的集群,即使个别
broker 失效,仍然可以持续地为客户提供服务。要提高集群的容错能力,需要配置较高的复制系 数。
5、Kafka的高性能
上面提到的所有特性,让
Kafka
成为了一个高性能的发布与订阅消息系统。通过横向扩展 生产者、消费者和 broker
,
Kafka
可以轻松处理巨大的消息流。在处理大量数据的同时, 它还能保证亚秒级的消息延迟。
四、Kafka的大数据生态系统
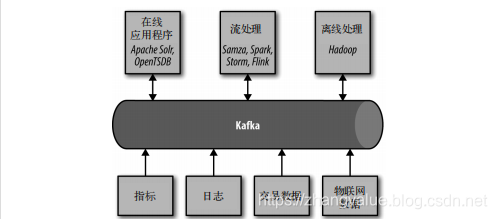
五、Kafka使用场景
1、活动追踪
Kafka
最初的使用场景是跟踪用户的活动。网站用户与前端应用程序发生交互,前端应用 程序生成用户活动相关的消息。这些消息可以是一些静态的信息,比如页面访问次数和点 击量,也可以是一些复杂的操作,比如添加用户资料。这些消息被发布到一个或多个主题 上,由后端应用程序负责读取。这样,我们就可以生成报告,为机器学习系统提供数据, 更新搜索结果,或者实现其他更多的功能。
2、传递消息
Kafka
的另一个基本用途是传递消息。应用程序向用户发送通知(比如邮件)就是通过传 递消息来实现的。这些应用程序组件可以生成消息,而不需要关心消息的格式,也不需要 关心消息是如何被发送的。一个公共应用程序会读取这些消息,对它们进行处理:
•
格式化消息(也就是所谓的装饰);
•
将多个消息放在同一个通知里发送;
•
根据用户配置的首选项来发送数据。
使用公共组件的好处在于,不需要在多个应用程序上开发重复的功能,而且可以在公共组 件上做一些有趣的转换,比如把多个消息聚合成一个单独的通知,而这些工作是无法在其 他地方完成的。
3、度量指标和日志记录
Kafka
也可以用于收集应用程序和系统度量指标以及日志。
Kafka
支持多个生产者的特性在 这个时候就可以派上用场。应用程序定期把度量指标发布到 Kafka
主题上,监控系统或告 警系统读取这些消息。Kafka
也可以用在像
Hadoop
这样的离线系统上,进行较长时间片段
的数据分析,比如年度增长走势预测。日志消息也可以被发布到
Kafka
主题上,然后被路 由到专门的日志搜索系统(比如 Elasticsearch
)或安全分析应用程序。更改目标系统(比 如日志存储系统)不会影响到前端应用或聚合方法,这是 Kafka
的另一个优点。
4、提交日志
Kafka
的基本概念来源于提交日志,所以使用
Kafka
作为提交日志是件顺理成章的事。我 们可以把数据库的更新发布到 Kafka
上,应用程序通过监控事件流来接收数据库的实时更 新。这种变更日志流也可以用于把数据库的更新复制到远程系统上,或者合并多个应用程 序的更新到一个单独的数据库视图上。数据持久化为变更日志提供了缓冲区,也就是说, 如果消费者应用程序发生故障,可以通过重放这些日志来恢复系统状态。另外,紧凑型日 志主题只为每个键保留一个变更数据,所以可以长时间使用,不需要担心消息过期问题。
5、流处理
流处理是又一个能提供多种类型应用程序的领域。可以说,它们提供的功能与 Hadoop 里 的 map 和 reduce 有点类似,只不过它们操作的是实时数据流,而 Hadoop 则处理更长时间 片段的数据,可能是几个小时或者几天,Hadoop 会对这些数据进行批处理。通过使用流 式处理框架,用户可以编写小型应用程序来操作 Kafka 消息,比如计算度量指标,为其他 应用程序有效地处理消息分区,或者对来自多个数据源的消息进行转换.























 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











