



from operator import gt
from pyspark import SparkContext, SparkConf
'''
实现思路:
1、按照Ordered和Serializable接口实现自定义排序的key
2、要将进行排序的文件加载进来生成<key,value>的RDD
3、使用sortByKey基于自定义的Key进行二次排序
4、去除掉排序的Key只保留排序的结果
'''
class SecondarySortKey():
def __init__(self, k):
self.column1 = k[0]
self.column2 = k[1]
def __gt__(self, other):
if other.column1 == self.column1:
return gt(self.column2, other.column2)
else:
return gt(self.column1, other.column1)
def main():
conf = SparkConf().setAppName('saprk_sort').setMaster('local[1]')
sc = SparkContext(conf=conf)
file = "D://tydic_study\spark//num.txt"
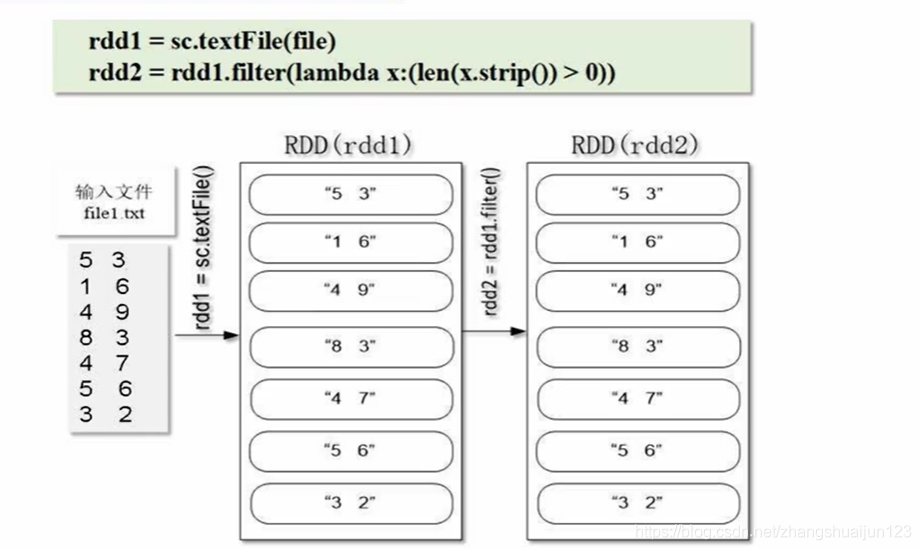
rdd1 = sc.textFile(file)
rdd2 = rdd1.filter(lambda x: len(x.strip()) > 0)
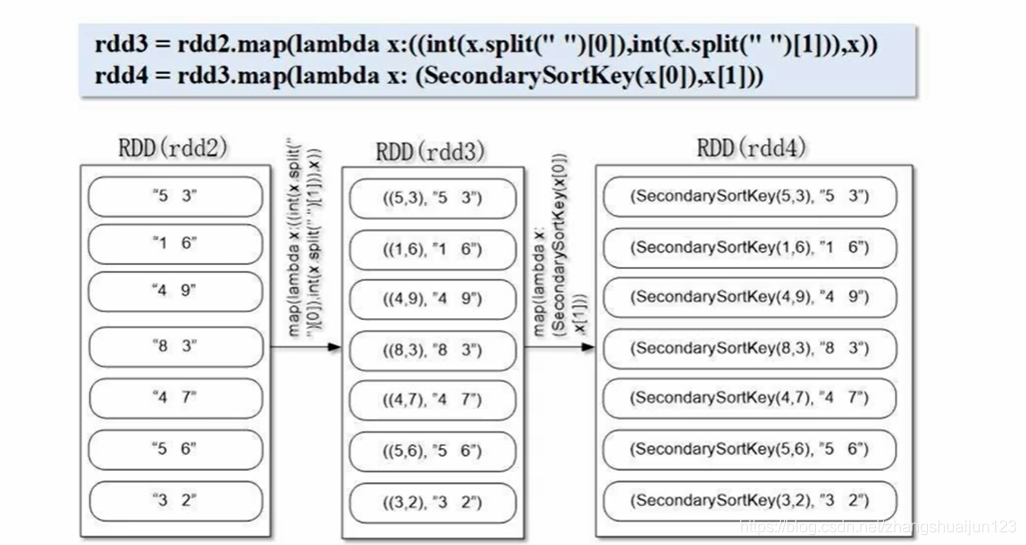
rdd3 = rdd2.map(lambda x: ((int(x.strip(" ")[0]), int(x.strip(" ")[1])), x))
rdd4 = rdd3.map(lambda x: (SecondarySortKey(x[0], x[1])))
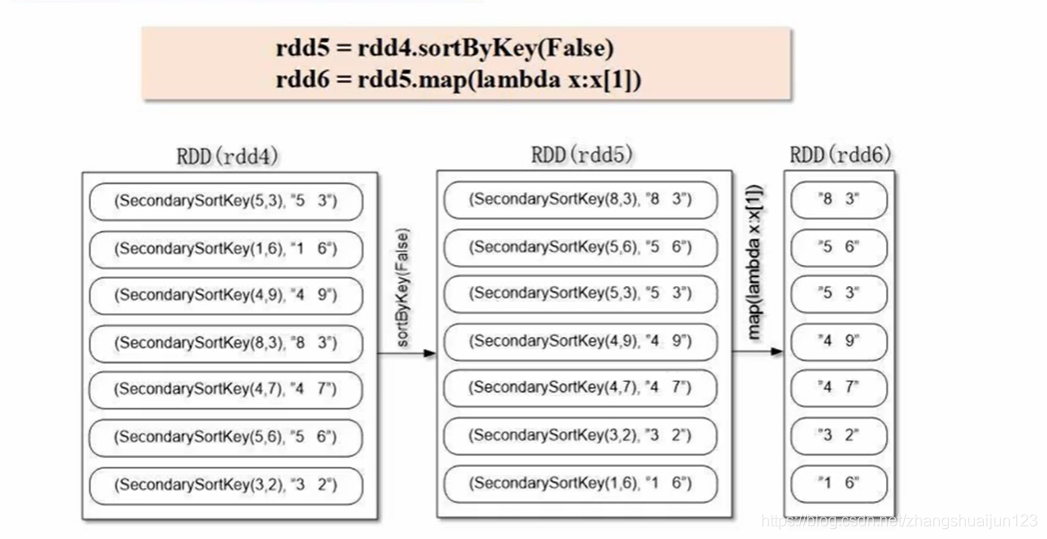
rdd5 = rdd4.sortByKey(False)
rdd6 = rdd5.map(lambda x:x[1])
rdd6.foreach(print)
if __name__ == '__main__':
main()
解题思路:


















 2131
2131




 到【灌水乐园】发言
到【灌水乐园】发言







