




Java 虚拟机在执行程序的过程中,会把所管理的内存划分成若干不同的数据区域。这些区域各有各有的用途,有的区域会随着虚拟机进程的启动而一直存在;有的区域会伴随着用户线程的启用和结束而创建和销毁。
其次,JVM 内存区域也称为运行时数据区域,这些数据区域包括:程序计数器、虚拟机栈、本地方法栈、堆、方法区等
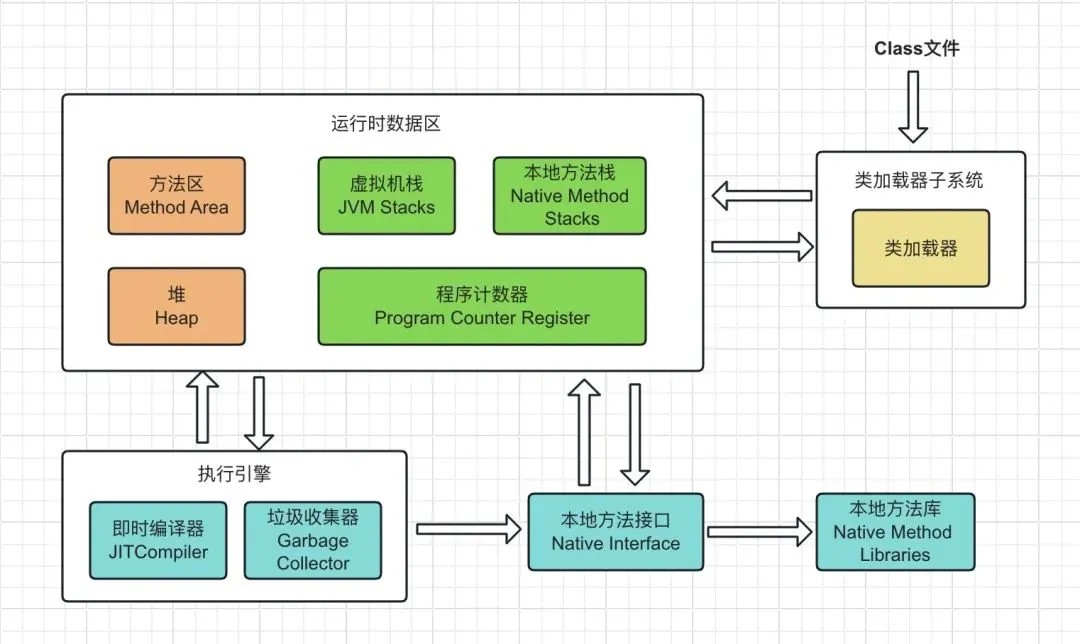
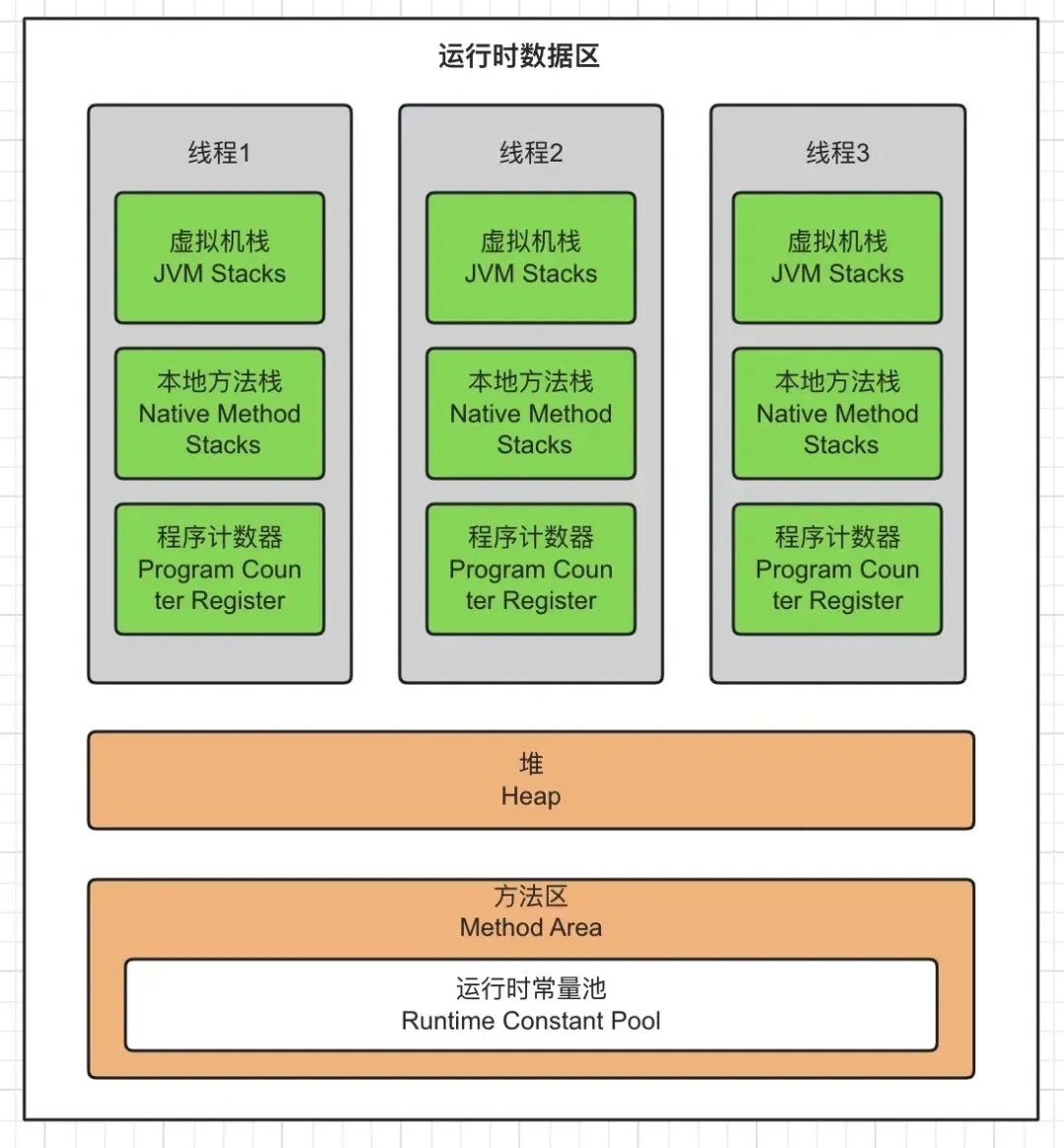
其中,运行时数据区的程序计数器、虚拟机栈、本地方法栈属于每个线程私有的区域;堆和方法区属于所有线程间共享的区域。
运行时数据区的线程间内存区域布局,可以用如下图来简要描述:
线上频繁 出现Full GC 的排查办法
1.查看 GC 日志
启用 GC 日志
在 Java 应用中,需要在启动参数中添加适当的参数来启用 GC 日志记录。可以使用-XX:+PrintGCDetails、-XX:+PrintGCDateStamps、-Xloggc:<log - path>参数。其中 -XX:+PrintGCDetails 会打印详细的 GC 信息,-XX:+PrintGCDateStamps会打印 GC 发生的时间戳,-Xloggc:<log - path>指定了 GC 日志的输出路径。
分析 GC 日志内容
Full GC 频率:查看 GC 日志中 Full GC 发生的频率。如果 Full GC 过于频繁(例如,每分钟多次),则需要深入分析。
Full GC 原因:
内存不足(Heap Space):如果日志中显示java.lang.OutOfMemoryError: Java heap space,说明应用程序创建的对象太多,导致堆内存不够用,从而触发 Full GC。
永久代 / 元空间(Permanent Generation / Metaspace)溢出:在旧版本的 Java 中,可能会出现java.lang.OutOfMemoryError: PermGen space,在 Java 8 及以后可能会出现java.lang.OutOfMemoryError: Metaspace。这表示类加载过多或者存在类加载器泄漏等问题,导致永久代或元空间被耗尽。
System.gc () 调用:如果在日志中发现有Full GC(System),说明应用程序中显式调用了System.gc()方法。虽然在现代 JVM 中,System.gc()的调用不一定会立即触发 Full GC,但如果频繁调用,可能会导致 Full GC 频繁发生。
2.分析内存泄漏
使用内存分析工具
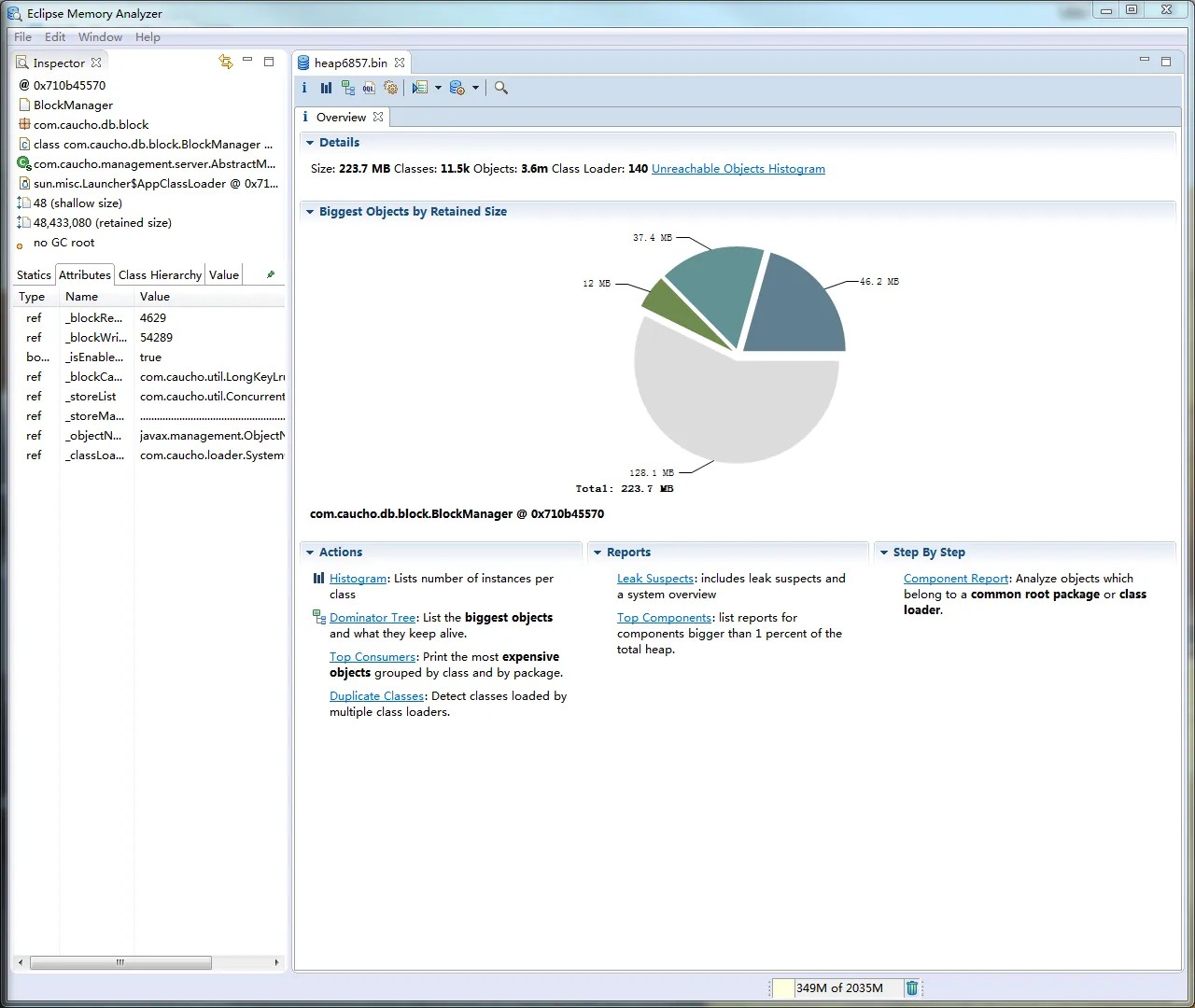
Heap Dump 工具:例如,使用jmap -dump:format=b,file=<dump - file - path>命令可以生成堆快照(Heap Dump)文件。在生成堆快照时,要选择在 Full GC 发生后或者内存使用量较高时进行,这样能更准确地捕获问题。它可以打开堆快照文件,分析对象的引用关系、内存占用情况等。通过 MAT,可以查找那些占用大量内存且不应该存在的对象,例如:
JVM Heap Dump文件可以使用常用的分析工具如下:
- jdk的jhat
- Eclipse Memory Analyzer(MAT)
- IBM Heap Analyzer
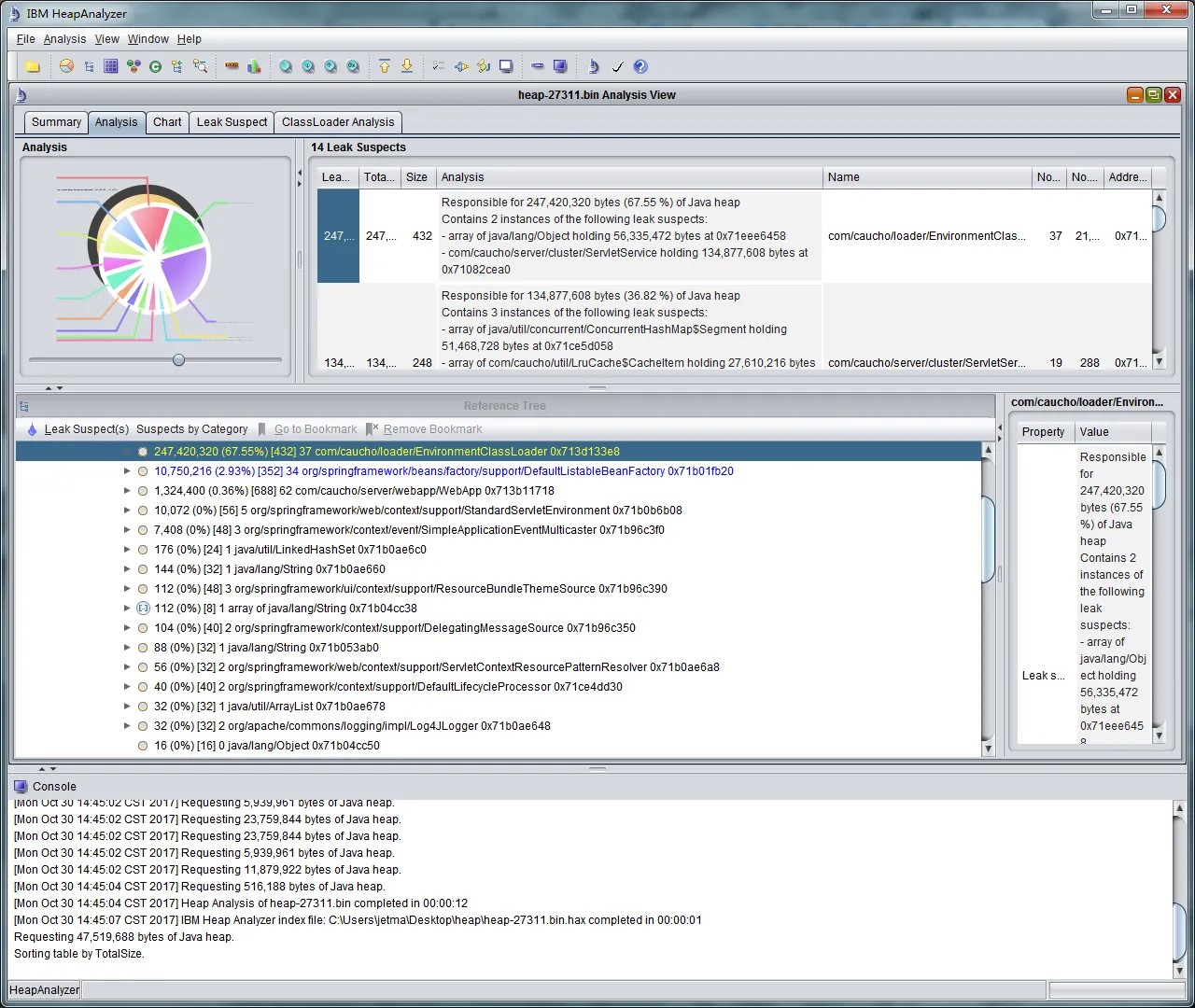
大对象(Large Objects):MAT 可以帮助找到那些占用大量堆内存的单个对象。如果存在一些本应被回收但却一直存在的大对象,可能是内存泄漏的迹象。
对象引用链(Reference Chains):通过分析对象的引用链,可以发现那些意外被长引用链所保持的对象。例如,一个不再使用的对象可能通过一系列的强引用被保存在内存中,导致无法被垃圾回收。
长期运行监控
Java Flight Recorder(JFR):这是 JDK 自带的一个性能监控和事件记录工具。它可以在应用程序运行过程中持续监控内存使用情况、对象分配和回收情况等。通过 JFR,可以发现随着时间的推移,内存中对象数量和大小的异常增长情况,从而判断是否存在内存泄漏。
3.检查对象生命周期
审查代码中的对象引用
局部变量和方法参数:检查方法中的局部变量和参数,确保在不需要使用对象时,对象的引用能够及时超出作用域。例如,在方法结束后,方法内创建的局部对象应该能够被垃圾回收。
静态变量和单例对象:静态变量和单例对象的生命周期通常与应用程序的生命周期相同。因此,要特别注意这些对象所引用的其他对象。如果单例对象持有大量其他对象的引用,并且这些引用在不需要时没有被正确清理,可能会导致内存问题。
缓存管理
缓存策略审查:如果应用程序中使用了缓存机制,例如使用HashMap或其他缓存库来缓存数据,需要检查缓存的清除策略。如果缓存没有设置合理的过期时间或者最大容量限制,可能会导致缓存对象不断累积,最终引发 Full GC。
弱引用和软引用的使用:考虑在合适的场景下使用弱引用(WeakReference)或软引用(SoftReference)。弱引用的对象在下次垃圾回收时会被回收,软引用的对象在内存不足时会被回收。例如,对于一些可以重新加载或者重新创建的数据,可以使用弱引用或软引用进行缓存,以避免长期占用内存。
4.优化代码
对象创建模式优化
减少不必要的对象创建:例如,在循环中频繁创建字符串对象(如String s = new String(“constant - value”);)是一种低效的做法。可以使用字符串常量或者StringBuilder来优化这种情况。
对象池(Object Pooling)技术:对于一些创建成本高且可复用的对象,如数据库连接、线程等,可以考虑使用对象池技术。通过对象池,可以重复利用已经创建的对象,减少对象创建和销毁的频率。
优化数据结构和算法
选择合适的数据结构:根据应用程序的需求选择合适的数据结构。例如,如果需要频繁地在集合中查找元素,使用HashSet或HashMap可能比ArrayList更高效。如果需要按照顺序访问元素,ArrayList可能更合适。
算法复杂度分析:对代码中的算法进行复杂度分析。如果存在时间复杂度或空间复杂度较高的算法(如嵌套的多层循环、递归调用深度过深等),可能会导致大量对象的创建和内存占用。优化这些算法可以减少内存压力。
5.调整垃圾回收策略
选择合适的垃圾回收器
Serial GC:适合单核 CPU 且内存较小的环境,简单且暂停时间较长。
Parallel GC(Throughput Collector):适合对吞吐量要求较高的应用,能够充分利用多核 CPU 并行进行垃圾回收,但暂停时间可能较长。
CMS(Concurrent Mark - Sweep)GC:适合对响应时间敏感的应用,它在垃圾回收过程中尽量减少应用程序的暂停时间,但可能会有更高的 CPU 使用率和内存碎片问题。
G1(Garbage - First)GC:适用于大容量内存的服务器,它将堆内存划分为多个大小相等的区域(Region),在垃圾回收时可以优先回收垃圾最多的区域,兼具高吞吐量和低暂停时间的特点。
ZGC(The Z Garbage Collector):JDK 11中推出的一款低延迟垃圾回收器, 是JDK 11+ 最为重要的更新之一,适用于大内存低延迟服务的内存管理和回收。
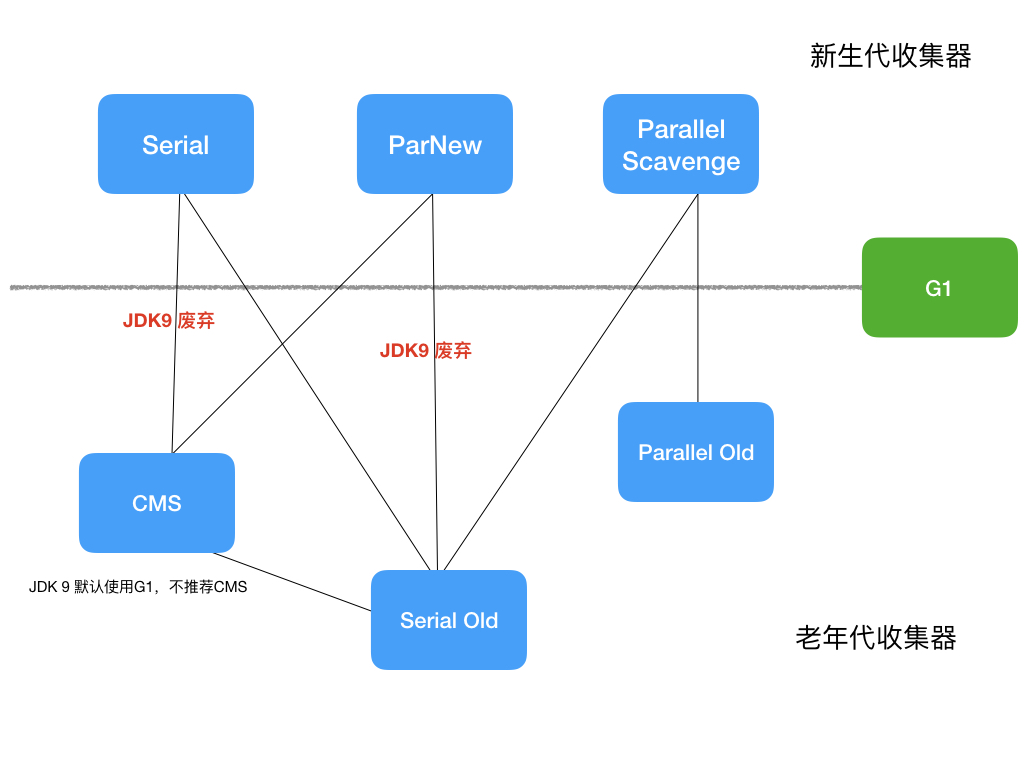
调整垃圾回收器参数
堆大小参数:-Xms和-Xmx分别用于设置初始堆大小和最大堆大小。合理设置这两个参数可以避免因堆空间过小导致频繁 Full GC,同时也避免因堆空间过大而浪费内存资源。
新生代和老年代比例:例如,-XX:NewRatio参数可以设置新生代和老年代的比例。调整这个比例可以影响对象在新生代和老年代之间的分配,进而影响垃圾回收的频率和效率。
Survivor 区比例:-XX:SurvivorRatio参数用于设置 Eden 区和 Survivor 区的比例。合理的 Survivor 区比例可以确保在新生代中对象的复制和回收能够高效进行。
6.使用监控工具
实时监控内存使用情况
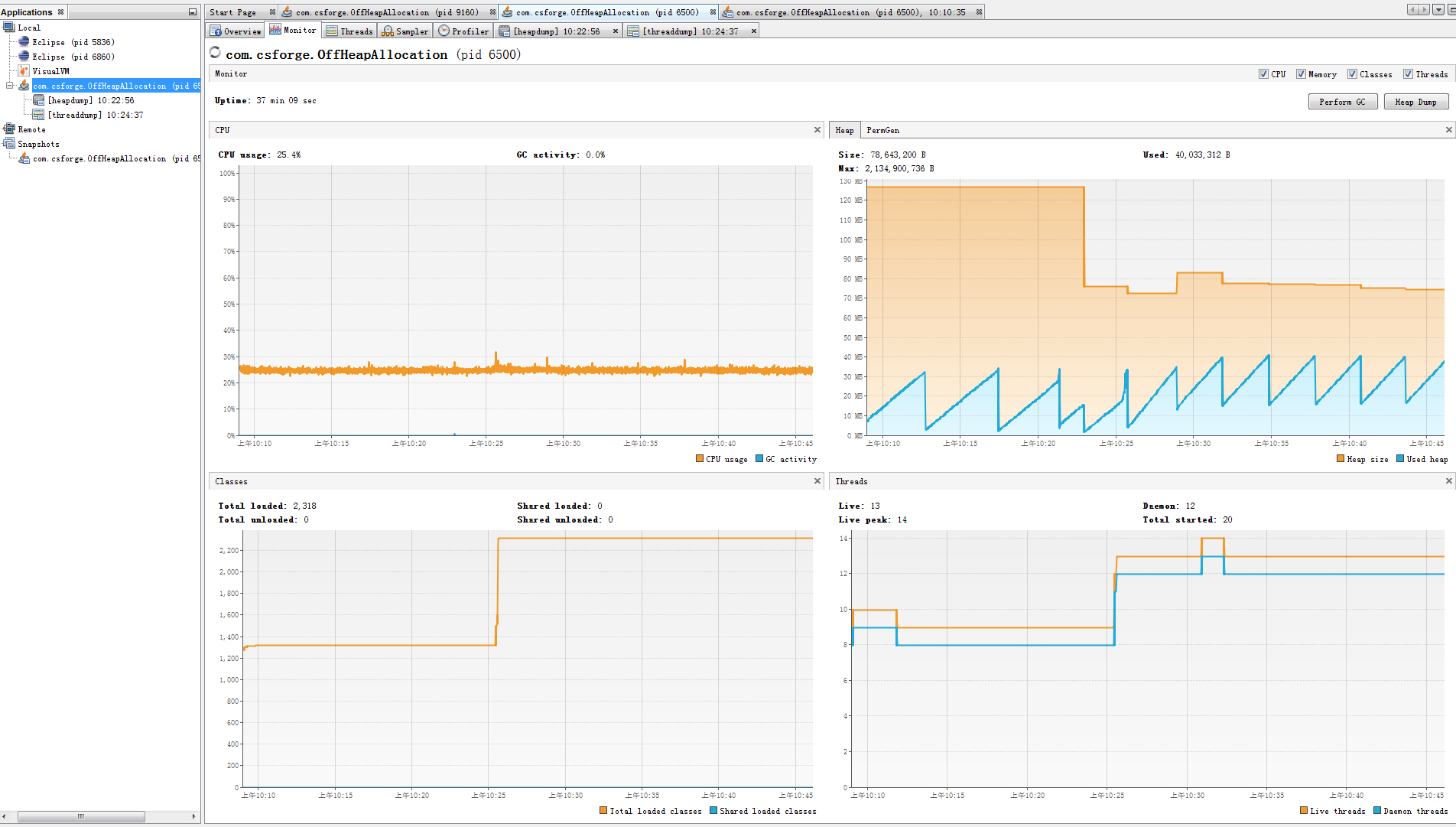
VisualVM:这是一个免费的 Java 性能监控和分析工具。它可以连接到本地或远程的 Java 应用程序,实时监控堆内存、非堆内存、线程等的使用情况。通过 VisualVM,可以直观地看到内存使用量的变化趋势,以及 Full GC 发生的时间点和频率。
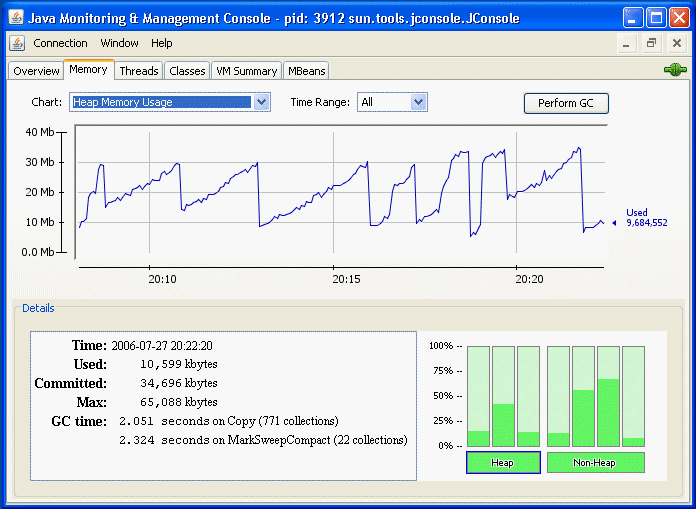
JConsole:JDK 自带的监控工具,可以监控 Java 应用程序的运行时性能,包括内存使用、线程、类加载等。JConsole 可以帮助发现内存使用的异常情况,例如内存使用量突然急剧上升等。
分析监控数据
内存使用趋势分析:通过长期监控内存使用情况,分析内存使用量的增长趋势。如果发现内存使用量呈线性或指数增长,可能存在内存泄漏或其他内存相关问题。
Full GC 与应用程序行为关联分析:将 Full GC 的发生时间与应用程序的业务操作进行关联分析。例如,如果每次执行某个特定的业务操作后都会引发 Full GC,那么很可能这个业务操作存在内存问题,如创建了大量对象或者持有了不必要的对象引用等。
新应用上线JVM内存分配思路
1. 一个新系统开发完毕之后如何设置JVM参数?
- 首先估算一下系统每个核心接口每秒多少次请求,每次请求会创建多少个对象,每个对象大概多大,每秒钟会使用多少内存空间。
- 接着就可以估算出来Eden区大概多长时间会占满。然后就可以估算出来多长时间会发生一次Young GC,而且可以估算一下发生Young GC的时候,会有多少对象存活下来,会有多少对象升入老年代里,老年代对象增长的速率大概是多少,多久之后会触发一次Full GC。
- 通过一连串的估算,就可以合理的分配年轻代和老年代的空间,还有Eden和Survivor的空间。原则就是:尽可能让每次Young GC后存活对象远远小于Survivor区域,避免对象频繁进入老年代触发Full GC。
- 最理想的状态下,就是系统几乎不发生Full GC,老年代应该就是稳定占用一定的空间,就是那些长期存活的对象在躲过15次Young GC后升入老年代自然占用的。然后平时主要就是几分钟发生一次Young GC,耗时几毫秒。
2. 在压测之后合理调整JVM参数
任何一个新系统上线都得进行压测,此时在模拟线上压力的场景下,可以用jstat等工具去观察JVM的运行内存模型:
- Eden区的对象增长速率多块?
- Young GC频率多高?
- 一次Young GC多长耗时?
- Young GC过后多少对象存活?
- 老年代的对象增长速率多高?
- Full GC频率多高?
- 一次Full GC耗时?
压测时可以完全精准的通过jstat观察出来上述JVM运行指标,让我们对JVM运行时的情况了如指掌。然后就可以尽可能的优化JVM的内存分配,尽量避免对象频繁进入老年代,尽量让系统仅仅有Young GC。
3. 线上系统的监控和优化
系统上线之后,务必进行一定的监控,高大上的做法就是通过Zabbix、Open-Falcon之类的工具来监控机器和JVM的运行,频繁Full GC就要报警。
比较差一点的做法,就是在机器上运行jstat,让其把监控信息写入一个文件,每天定时检查一下看一看。
一旦发现频繁Full GC的情况就要进行优化,优化的核心思路是类似的:通过jstat分析出来系统的JVM运行指标,找到Full GC的核心问 题,然后优化一下JVM的参数,尽量让对象别进入老年代,减少Full GC的频率。
4. 线上频繁Full GC的几种表现
一旦系统发生频繁Full GC,大概看到的一些表象如下:
- 机器CPU负载过高;
- 频繁Full GC报警;
- 系统无法处理请求或者处理过慢
所以一旦发生上述几个情况,大家第一时间得想到是不是发生了频繁Full GC。
5. 频繁Full GC的几种常见原因
几个常见的频繁Full GC的原因:
- 系统承载高并发请求,或者处理数据量过大,导致Young GC很频繁,而且每次Young GC过后存活对象太多,内存分配不合理, Survivor区域过小,导致对象频繁进入老年代,频繁触发Full GC。
- 系统一次性加载过多数据进内存,搞出来很多大对象,导致频繁有大对象进入老年代,必然频繁触发Full GC 。
- 系统发生了内存泄漏,莫名其妙创建大量的对象,始终无法回收,一直占用在老年代里,必然频繁触发Full GC。
- Metaspace(永久代)因为加载类过多触发Full GC。
- 误调用System.gc()触发Full GC。
其实常见的频繁Full GC原因无非就上述那几种,在线上处理Full GC的时候,就从这几个角度入手去分析即可,核心利器就是 jstat。 如果jstat分析发现Full GC原因是第一种,那么就合理分配内存,调大Survivor区域即可。 如果jstat分析发现是第二种或第三种原因,也就是老年代一直有大量对象无法回收掉,年轻代升入老年代的对象病不多,那么就dump 出来内存快照,然后用MAT工具进行分析即可通过分析,找出来什么对象占用内存过多,然后通过一些对象的引用和线程执行堆栈的分析,找到哪块代码弄出来那么多的对象的。接着优化代码即可。 如果jstat分析发现内存使用不多,还频繁触发Full GC,必然是第四种和第五种,此时对应的进行优化即可。


















 3297
3297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









