




前端时间在知乎上看到一个问题,今天有空整理并测试了一下:
这个问题很具体,所以还是可以去尝试优化一下,我们基于InnoDB并使用自增主键来讲。
比较简单的做法是将历史数据存放到另一个表中,与最近的数据分开。那是不是历史表随便建就行了?其实这里的区别很大:
先讲一下优化思路:如果数据量太大(远远超过内存),对于批量查询来说单纯的添加索引作用不大,需要将数据按照查询重新组织降低查询需要的IO次数。
首先拿一组数据来分析一下,如果采用自增ID,数据按写入顺序存储在磁盘上,数据在磁盘上的分布情况大体如下:
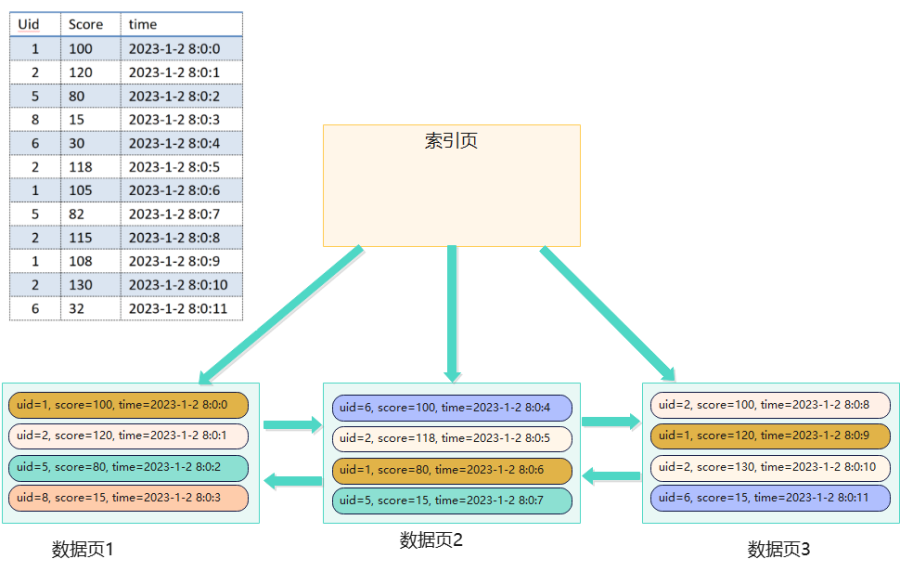
&nbs
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









