




 本文介绍了一种从YOLOv3训练日志中提取关键指标并进行可视化的技术,包括总损失值、平均损失值、学习率、训练时间和处理的图像数量。通过Python的pandas和matplotlib库,实现了对大量日志数据的有效处理和图形展示。
本文介绍了一种从YOLOv3训练日志中提取关键指标并进行可视化的技术,包括总损失值、平均损失值、学习率、训练时间和处理的图像数量。通过Python的pandas和matplotlib库,实现了对大量日志数据的有效处理和图形展示。
日志分析:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
#最大迭代次数
max_batches=15000
#
minStep = 18
#其中minStep代表1行Loaded: 0.000024 seconds、10行 Region,1行第n次的结果 1+16+1=18
'''
Loaded: 0.000024 seconds
Region 16 Avg IOU: 0.182902, Class: 0.405722, Obj: 0.503862, No Obj: 0.424742, .5R: 0.000000, .75R: 0.000000, count: 13
Region 23 Avg IOU: 0.105590, Class: 0.662942, Obj: 0.520905, No Obj: 0.509580, .5R: 0.000000, .75R: 0.000000, count: 12
Region 16 Avg IOU: 0.130522, Class: 0.408217, Obj: 0.476290, No Obj: 0.424609, .5R: 0.000000, .75R: 0.000000, count: 14
Region 23 Avg IOU: 0.182063, Class: 0.550706, Obj: 0.494642, No Obj: 0.507713, .5R: 0.070175, .75R: 0.000000, count: 57
Region 16 Avg IOU: 0.200967, Class: 0.390888, Obj: 0.475645, No Obj: 0.427092, .5R: 0.062500, .75R: 0.000000, count: 16
Region 23 Avg IOU: 0.143319, Class: 0.580808, Obj: 0.531322, No Obj: 0.509306, .5R: 0.064516, .75R: 0.000000, count: 31
Region 16 Avg IOU: 0.237835, Class: 0.382465, Obj: 0.380643, No Obj: 0.427353, .5R: 0.066667, .75R: 0.000000, count: 15
Region 23 Avg IOU: 0.106707, Class: 0.574932, Obj: 0.548107, No Obj: 0.510025, .5R: 0.000000, .75R: 0.000000, count: 37
Region 16 Avg IOU: 0.163751, Class: 0.414830, Obj: 0.416970, No Obj: 0.425206, .5R: 0.000000, .75R: 0.000000, count: 3
Region 23 Avg IOU: 0.174204, Class: 0.676216, Obj: 0.571296, No Obj: 0.510338, .5R: 0.045455, .75R: 0.000000, count: 22
Region 16 Avg IOU: 0.191540, Class: 0.441109, Obj: 0.392017, No Obj: 0.425114, .5R: 0.047619, .75R: 0.000000, count: 21
Region 23 Avg IOU: 0.144743, Class: 0.646313, Obj: 0.482872, No Obj: 0.507978, .5R: 0.000000, .75R: 0.000000, count: 30
Region 16 Avg IOU: 0.192162, Class: 0.507017, Obj: 0.467949, No Obj: 0.425880, .5R: 0.000000, .75R: 0.000000, count: 10
Region 23 Avg IOU: 0.129258, Class: 0.672717, Obj: 0.588547, No Obj: 0.509534, .5R: 0.000000, .75R: 0.000000, count: 36
Region 16 Avg IOU: 0.182297, Class: 0.803474, Obj: 0.596444, No Obj: 0.424545, .5R: 0.000000, .75R: 0.000000, count: 4
Region 23 Avg IOU: 0.172792, Class: 0.732352, Obj: 0.541576, No Obj: 0.507713, .5R: 0.041667, .75R: 0.000000, count: 24
1: 756.629517, 756.629517 avg, 0.000000 rate, 1.112322 seconds, 64 images
'''
#在日志里每10个miniStep,即每10次迭代,一次迭代代表1个batch,会出现 2行(分别是Resize 608或者其它尺寸)
n=10
step=minStep*n+2#18x10+2 #2 Resize 608
#x%step==0 or x%step==1
#x%step!=0 and x%step!=1
lines=int(step*max_batches/n)#lines =91000=182*500
result = pd.read_csv('/home/zhangping/Desktop/yolo_log/ranPianTiny2.txt',
skiprows=[x for x in range(lines) if (x%step==0 or x%step==1)],
error_bad_lines=False,
names=['Total Loss', 'Avg loss','rate','seconds','images'])
#只提取以下类似的行
'''
1: 756.629517, 756.629517 avg, 0.000000 rate, 1.112322 seconds, 64 images
第n次迭代:总的损失值,平均损失值,学习率、时间、图片数量
'''
result1=result.iloc[[i for i in range(minStep*max_batches) if (i+1)%18==0]]#
#总的损失值
totalLoss = result1['Total Loss'].str.split(': ').str[1]#<class 'pandas.core.series.Series'>
totalloss = totalLoss.astype(float)
#平均损失值
avgLoss = result1['Avg loss'].str.split(' ').str[1]#replace
avgLoss = avgLoss.astype(float)
#学习率
rate = result1['rate'].str.split(' ').str[1]
rate = rate.astype(float)
#时间
seconds = result1['seconds'].str.split(' ').str[1]
seconds = avgLoss.astype(float)
#图片数量
images = result1['images'].str.split(' ').str[1]
images = images.astype(float)
#
figure = plt.figure()
gs1 = gridspec.GridSpec(3,2)
#画出总的损失值
ax_totalLoss = figure.add_subplot(gs1[0])
ax_totalLoss.set_xlabel('totalLoss')
ax_totalLoss.set_ylabel('totalLoss')
ax_totalLoss.plot(avgLoss.values,label='totalLoss')
#画出平均损失值
ax_avgloss = figure.add_subplot(gs1[1])
ax_avgloss.set_xlabel('avgloss')
ax_avgloss.set_ylabel('avgloss')
ax_avgloss.plot(avgLoss.values,label='avgloss')
#画出学习率
ax_rate = figure.add_subplot(gs1[2])
ax_rate.set_xlabel('rate')
ax_rate.set_ylabel('rate')
ax_rate.plot(rate.values,label='rate')
#画出时间
ax_seconds = figure.add_subplot(gs1[3])
ax_seconds.set_xlabel('seconds')
ax_seconds.set_ylabel('seconds')
ax_seconds.plot(seconds.values,label='seconds')
#画出图片数量
ax_images = figure.add_subplot(gs1[4])
ax_images.set_xlabel('images')
ax_images.set_ylabel('images')
ax_images.plot(images.values,label='images')
plt.show()
总的损失值、平均损失值等图例:
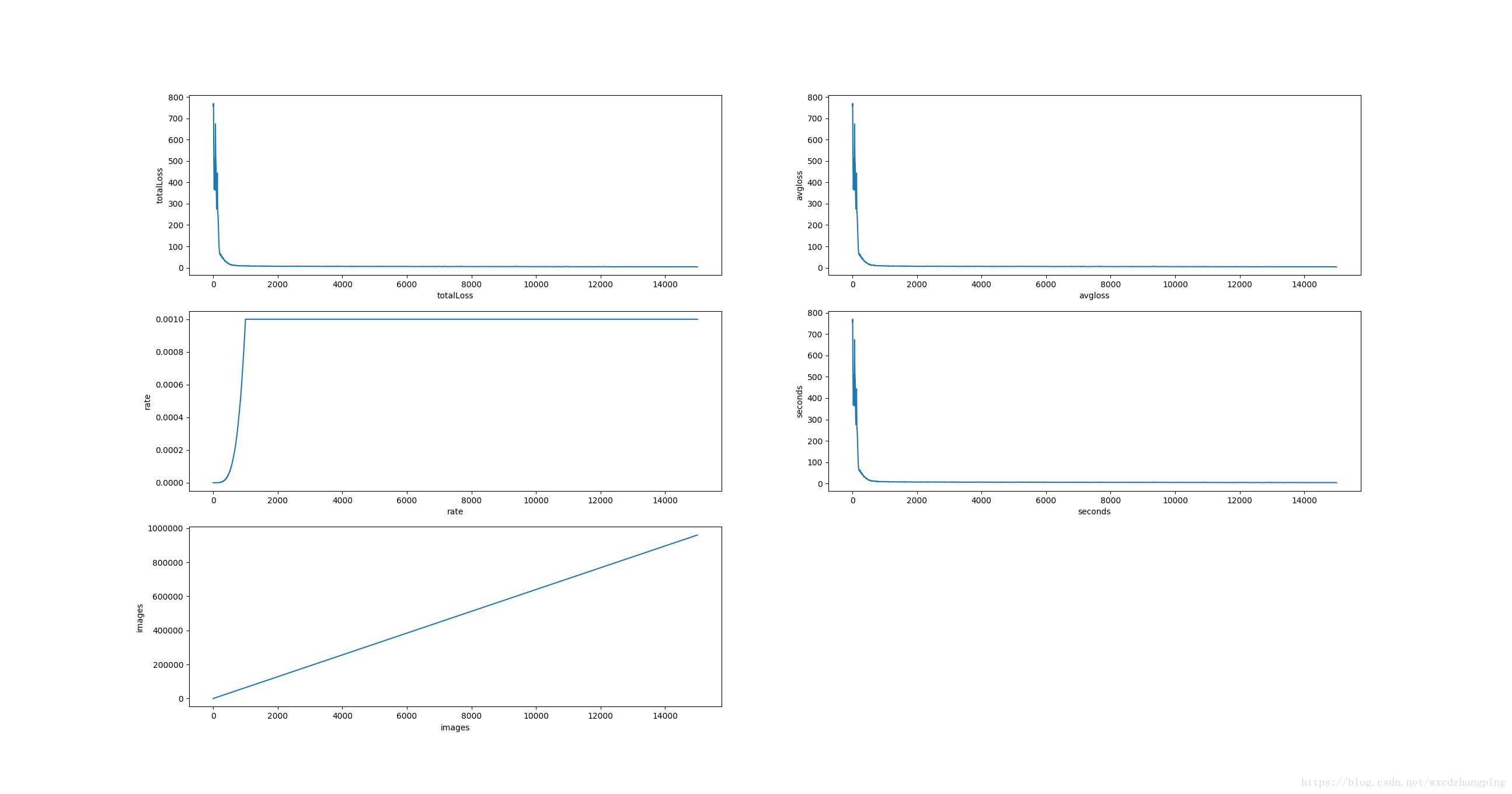
从以上的图例可以看出 总的损失值和平均损失值都在下降~


















 1848
1848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









