






 本文详细分析了Java HashMap的源码,包括其get和put操作的时间复杂度,为何链表长度超过8时转换为红黑树,以及红黑树节点的排序方式。HashMap并非线程安全,推荐在需要线程安全时使用ConcurrentHashMap。此外,文章探讨了HashMap的构造、哈希函数以及在不同情况下如何优化性能。
本文详细分析了Java HashMap的源码,包括其get和put操作的时间复杂度,为何链表长度超过8时转换为红黑树,以及红黑树节点的排序方式。HashMap并非线程安全,推荐在需要线程安全时使用ConcurrentHashMap。此外,文章探讨了HashMap的构造、哈希函数以及在不同情况下如何优化性能。
本系列是Java详解,专栏地址:Java源码分析
第一篇文章:Java详解(1):HashMap介绍,HashMap的迭代,HashMap的线程安全问题
HashMap.java介绍
HashMap官方文档:HashMap (Java Platform SE 8 )
HashMap.java源码共2445行,下载地址见我的文章:Java源码下载和阅读(JDK1.8/Java 11)
文件地址:openjdk-jdk11u-jdk-11.0.6-3/src/java.base/share/classes/java/util
从下图中我们可以看出HashMap继承自AbstractMap
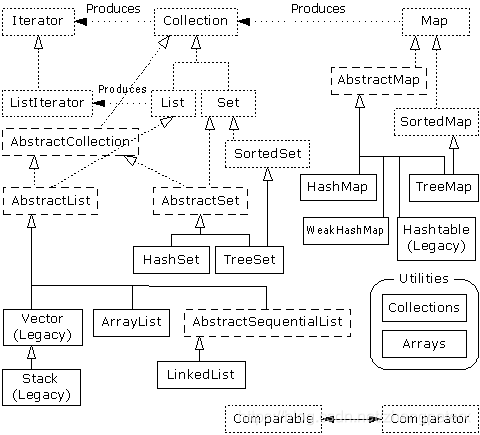
实际继承如下:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {}
在代码开始前的注释里说明了Hash table与Hash map的区别:
1.Hash map允许空key与空的value
2.HashMap不是线程安全的,Hashtable是线程安全的。‘’
文档中还提到:
- HashMap不保证key的顺序。
- 对map进行迭代花费的时间跟
capacity(the number of buckets) 乘以size (the numberof key-value mappings)成正比。所以如果你经常要迭代,那么初始的capacity不要设置太高,或者load factor太小 - 对一个HashMap实例,有2个因素影响性能,一个是初始化时设置的
capacity,另一个是load factor。
capacity就是hash table有多少个桶。
load factor是指当hash table有多少个桶有数据时,capacity会增加。 - 当
hash table的entry个数超过load factor*capacity时,hash table会进行rehash,也就是重建。rehash后hash table有接近2倍buckets的数量。 - 默认的
load factor设置为0.75,能很好的平衡时间和空间。load factor更高可以减少空间浪费,但会增加查找成本。 - 如果预计
HashMap会有很多key,那么可以在创建的时间就提供足够大的capacity,减少rehash开销。 - 如果有很多
key有相同的hashCode,会降低map的性能。改善的方法是让key是Comparable。 HashMap不是synchronized的,意思是HashMap不是线程安全的。想要线程安全可以使用synchronizedMap,使用方法如下:Map m = Collections.synchronizedMap(new HashMap(...));HashMap的迭代器是fail-fast。如果迭代器创建后map的底层结构改变了,那么对迭代器的所有访问(除了remove)都会抛出异常ConcurrentModificationException。但迭代器并不能保证可以做到fail-fast,所以不要依赖异常和迭代器。
下面部分开始分析源码。
首先是构造函数:
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
默认的load factor为0.75,默认的initial capacity为16。
如果指定initial capacity,还需对threshold进行初始化:
this.threshold = tableSizeFor(initialCapacity);
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = -1 >>> Integer.numberOfLeadingZeros(cap - 1);
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
然后我发现不对,就初始化2个参数,hashmap就初始化好了?
可以看到HashMap有个成员对象数组:
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
从注释中的说明,我们可以看出数组是在第一次使用后才初始化的,并且保证长度是2的倍数。初始化操作在putVal函数的开头:
Node<K,V>[] tab; int n;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
resize函数的作用是初始化数组或者扩容数组。
查看put的具体操作:先是对key算了hash后,调用putVal函数。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
哈希函数:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
可以看到如果key是null,那么哈希的结果是0,否则的话对结果进行右移和异或。
异或操作的详细解释:JDK 源码中 HashMap 的 hash 方法原理是什么? - 知乎
简单来说就是让哈希后的结果变得更加稀疏,分散。
查看putVal函数。如果哈希后的结果不存在数组中,那么直接存放:
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
因为哈希后的结果是int范围的,要映射到数组的范围,最简单的做法就是直接进行与运算,所以数组的大小都是2的幂次。
如果数组中已经存在节点了,
1.先判断key是否相同,相同的话直接替换value
2.判断是否是TreeNode
3.向链表中添加节点,如果链表长度大于等于8,就把链表变成红黑树。(注:并不是长度大于等于8就一定会变为红黑树,容量要达到64后才能变为树)
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
删除节点时,当节点个数少于6个时,红黑树会转换成链表。
下面就是面试时容易被问到的题目:
1.HashMap的get和put操作平均时间复杂度和最坏时间复杂度
文档称:This implementation provides constant-time performance for the basic
operations get and put, assuming the hash function disperses the elements properly among the buckets.
翻译成中文就是:HashMap的get和put操作是常量时间复杂度的,O(1)时间复杂度,基于的前提是哈希函数将元素正确分散在存储桶中。
意思就是HashMap的get和put操作默认情况下都是O(1)的时间复杂度。最坏情况则是O(logN),也就是红黑树的情况。
2.为什么链表长度超过8才转换为红黑树
1.因为红黑树的节点占用的空间大小为一般节点的2倍,所以没必要一开始就是红黑树。
2.理想情况下随机hashCode算法下所有桶中节点的分布频率会遵循泊松分布,一个桶中链表长度达到8个元素的概率为0.00000006,几乎是不可能事件。但如果用户实现了一个不好的哈希算法,那么就需要在长度超过8时转换为红黑树。
3.红黑树中的节点如何排序
先根据hashCode排序,相同的情况下调用compareTo方法。
但如果hashCode相同,类不是comparable的,那么先判断名字是否相同,相同的话再调用系统的hash方法进行判断:
if (d = a.getClass().getName().compareTo(b.getClass().getName()) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?-1 : 1);
参考:

















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









