



 本文介绍了Shell的基础知识,包括运行环境、Piping管道以及Linux三剑客——grep、awk和sed的使用。详细讲解了grep的正则表达式、awk的数据处理和sed的数据修改功能,并提供了多个实用示例,帮助读者掌握Shell命令的运用。
本文介绍了Shell的基础知识,包括运行环境、Piping管道以及Linux三剑客——grep、awk和sed的使用。详细讲解了grep的正则表达式、awk的数据处理和sed的数据修改功能,并提供了多个实用示例,帮助读者掌握Shell命令的运用。
Bash官方文档:https://www.gnu.org/software/bash/manual/bash.html
正则表达式 https://docs.microsoft.com/en-us/dotnet/standard/base-types/regular-expression-language-quick-reference
shell 运行环境
- bash下还可以再重新启动⼀个shell,这个shell是sub shell,原shell会复 制⾃⾝给他。在sub shell中定义的变量,会随着sub shell的消亡⽽消失
- () 子shell中运行
- $(ls) 表示执行ls后的结果,与``作用一致,不过可以嵌套
- {}当前shell中执行
- $$当前脚本执行的pid
- &后台执行
- $!运行在后台最后一个作业的pid(进程ID)
shell Piping 管道
❖ Read ⽤来读取输⼊,并赋值给变量
❖ echo ,printf可以简单输出变量。
❖ > file 将输出重定向到另⼀个⽂件
❖ >> 表⽰追加 等价于tee -a
❖ < file 输⼊重定向
| 表⽰管道,也就是前⼀个命令的输出传⼊下⼀个命令 的输入
Linux 三剑客
grep(数据查找定位)
awk(数据切片)
sed(数据修改)
类⽐SQL
grep=select * from table
awk=select field from table
sed=update table set field=new where field=old
grep
- 常用 -i -v -o -E -oE
grep pattern file
grep -i pattern file 忽略大小写
grep -o pattern file 精准匹配
grep -v pattern file 反转查找,输出与查找条件不匹配的行
grep -E pattern file 扩展正则表达式
grep -A -B -C pattern file 显示命中数据的上下文
grep pattern file -r dir / 递归搜索
一般使用 -oE 来模糊搜索
- 实例
echo ‘hello test!’ | grep -o ‘e’
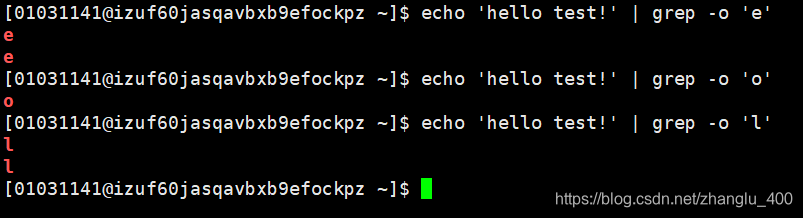
不加-o会把包含匹配信息所在行中的所有内容输出(不在一行的不会输出)
正则表达式
- 基本表达式
^开头
$结尾
[a-z][0-9]区间
.匹配任意一个字符
*0个或多个 能匹配多少匹配多少
.* 加在一起就是:匹配任意多个字符
echo 1234 | grep -E "^.*?" 输出 1234
- 基本正则与扩展正则的区别
? 非贪婪模式 ,尽量少的匹配
+ ⼀个或者多个
() 分组
{} 范围约束
| 匹配多个表达式的任何⼀个
echo 1234 | grep -oE ".*?" 输出 为空
echo 1234 | grep -oE '..*?' 输出 1
2
3
4
解读: .*?什么也没有 再加个. 全部匹配
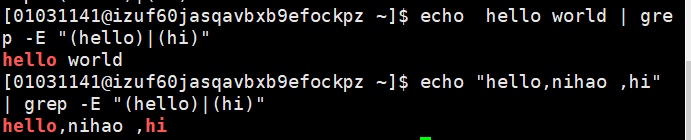
echo "hello,nihao ,hi" | grep -E "(hello)|(hi)" //该括号不加也行
- curl命令:
curl 网址 | grep 正则
curl -s https://www.baidu.com/ | grep 正则
-s :加上表示会屏蔽curl的一些调试信息,一般都加
‘^ <a title=".*"’
^:精准匹配,表示这行开始时有空格,然后是<a title=
- 实例
通过百度搜索关键字,然后通过正则匹配出搜索结果约xxx的内容,关键字以文件的形式作为参数循环传入- 创建文件 vim keywords
- 输入要搜索的关键字:java、python、C++
- shell执行语句 while read m; do echo $m; curl -s http://www.baidu.com/s?wd=$m; done < keywords | grep -o “结果约[0-9,]*”
awk命令
awk ‘条件类型1{动作1} 条件类型2{动作2} …’ filename
awk ‘BEGIN{}END{}’ 开始和结束
-
常用命令
awk ‘pattern{action}’
awk ‘BEGIN{}END{}’ 开始和结束
awk ‘/Running/’ 正则匹配
awk ‘/aa/,/bb/’ 区间选择
awk ‘$2~/xxx/’ 字段匹配
awk ‘NR=2’ 取第二行
awk ‘NR>1’ 去掉第一行 -
awk 内置变量
FS 字段分隔符
OFS 输出数据的字段分隔符
RS 记录分隔符
OR 输出字段的行分隔符
NF 字段数
NR 记录数 -
awk的字段数据处理
-F 参数指定字段分隔符
BEGIN{FS=’_’} 也可以表示分隔符
$0 代表当前记录
$1 代表第一个字段
$N 代表第N个字段
$NF 代表最后一个字段 -
awk的字段分割
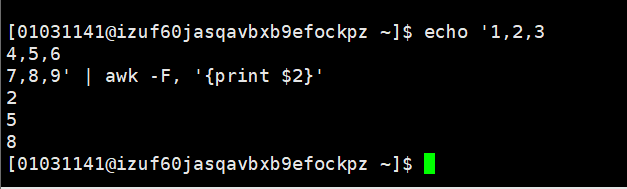
echo ‘1,2,3
>4,5,6
>7,8,9’ | awk -F, ‘{print $2}’
其中-F 后的紧跟是分隔符,如图的分隔符是“,”
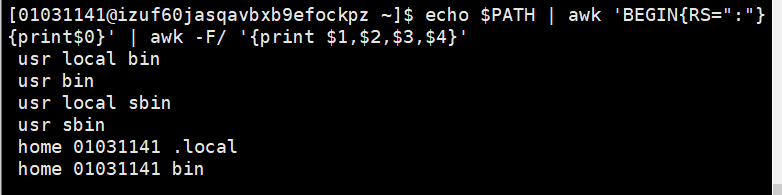
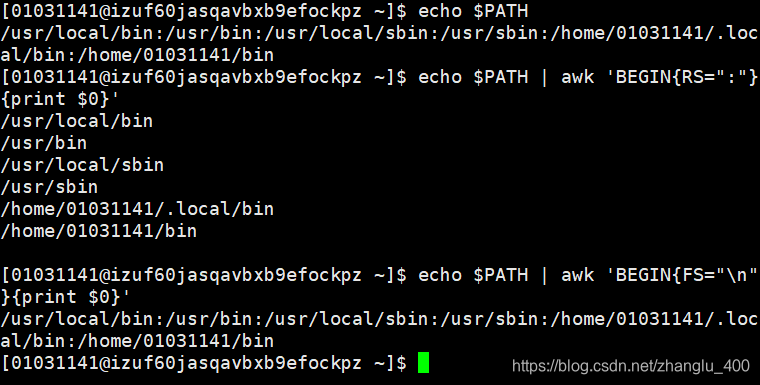
echo $PATH | awk ‘BEGIN{RS=":"}{print$0}’ | awk -F/ ‘{print $1,$2,$3,$4}’
awk ‘BEGIN{print 1*10*2}’ 输出 20
- 把单行拆分为多行
❖ echo $PATH | awk ‘BEGIN{RS=":"}{print $0}’
❖ echo $PATH | awk ‘BEGIN{RS=":"}{print NR,$0}’
❖ echo $PATH | awk ‘BEGIN{RS=":"}END{print NR}’ - 多行组合为单行
❖ echo $PATH | awk ‘BEGIN{RS=":"}{print $0}’ | awk ‘BEGIN{FS="\n";ORS=":"}{print $0}’
‘BEGIN{
初始化语句
}
{
pattern{actions};
pattern{actions};
…
}
END{
读取所有输入行后执行语句
}’
如果BEGIN区块存在,awk首先执行它里面包含的动作指令。
当awk读完所有的输入行后,如果存在END区域,执行END区域的指令
- pattern`(条件)可以是以下两种类型:
- 正则表达式:/正则表达式/
- 布尔表达式:表达式成立,触发相应的actions执行,如 5>3{print}
- actions(动作)是由许多awk指令构成
- awk的I/O指令有print、printf()、getline等
- awk的流程控制指令有if…else…、 while() {…}等
- 所有 awk 的动作,亦即在 {} 内的动作,如果有需要多个指令辅助时,可利用分号“;”间隔, 或者直接以[Enter] 按键来隔开每个指令
- 与 bash shell 的变量不同,在 awk 当中,变量可以直接使用,不需加上 $ 符号。
- awk 主要是处理“每一行的字段内的数据”,而默认的“字段的分隔符号为 “空白键” 或 “[tab]键” ”! 也就是说,比如有这样一行内容“hello shell”, awk就会当成是两列$1取第一列的数据,$2取第二列的数据
例子:
curl https://testing-studio.com/ | grep -o "http[s]://.* " —不用解释吧(过滤http或https://开头的)
----[s]表示区间
"http[s]://[^ '\“]* " 加上了[^ ‘\”] 表示不选择以空格加单引号结尾的或者双引号结尾对
注意:去掉了星号前面的点
sed
sed 本身也是一个管道命令,可以分析 standard input ,而且 sed 还可以将数据进行取代、删除、新增、撷取特定行等等的功能
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到屏幕上。但如果加上 -n 参数后,则只有经过 sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令行界面上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以执行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正则表达式的语法。(默认是基础正则表达式语法)
-i :直接修改读取的文件内容,而不是由屏幕输出。
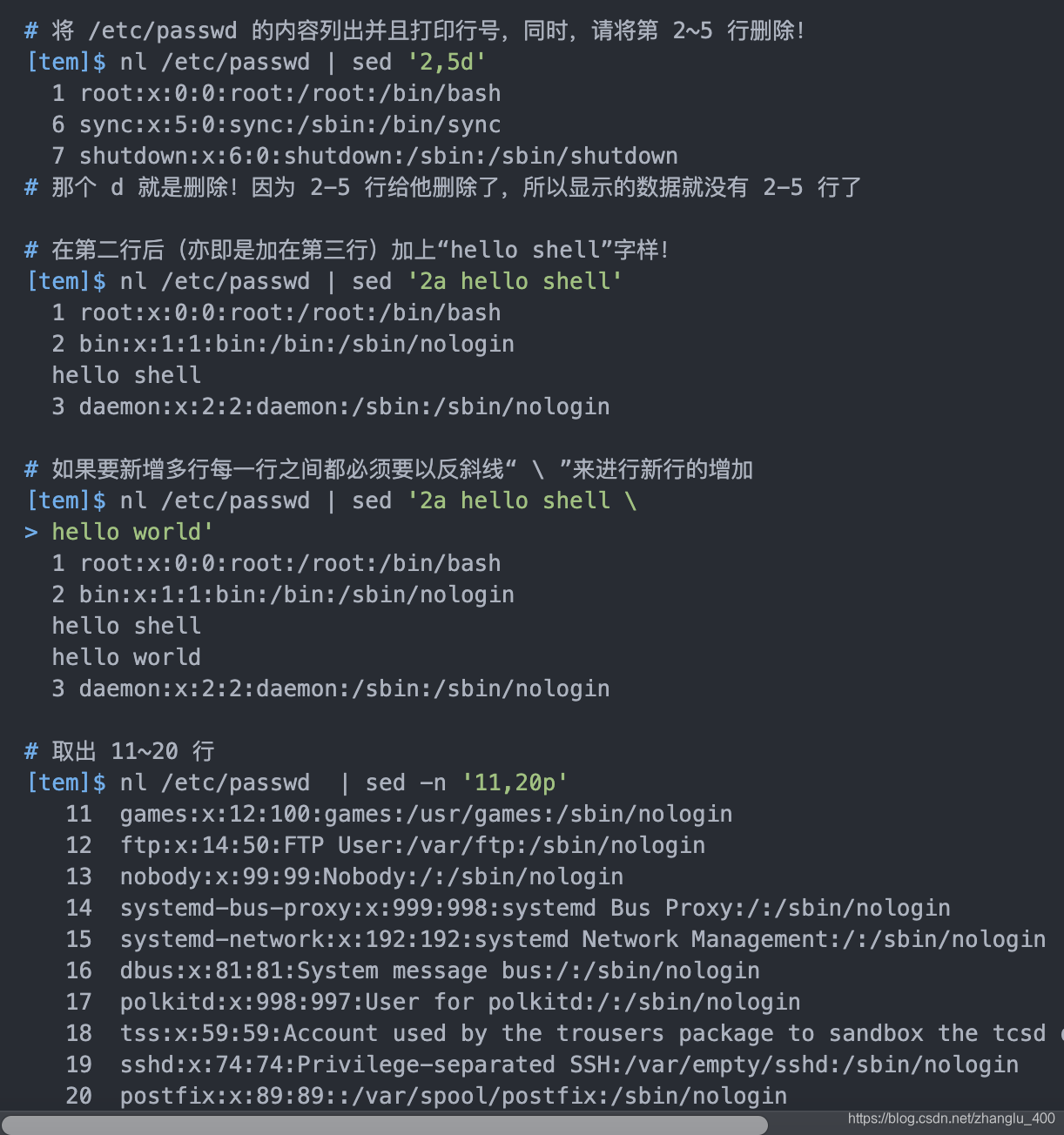
动作说明: [n1[,n2]]function
n1, n2 :不见得会存在,一般代表“选择进行动作的行数”,举例来说,如果我的动作
是需要在 10 到 20 行之间进行的,则“ 10,20[动作行为] ”
function 有下面这些:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i:插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以取代匹配到的值!通常这个 s 的动作可以搭配正则表达式!
例如 1,20s/old/new/g就是啦!
less命令
curl -s http://www.baidu.com | less 进入交互式界面,可以上下左右移动
sed ‘s#ti原始内容#替换后内容#g’ g结尾表示全局替换
| sort | uniq 去重
sed后面接的动作,务必以 ‘单引号’ 括起来哦
如果有多个动作,使用-e分隔 如,nl /etc/passwd | sed -n -e ‘1,10p’ -e ‘2,5d’ -e ‘6i hello’
补充正则
字符匹配:
.任意单个字符
[]指定范围的字符
[^]不在指定范围的字符
次数匹配:
- 匹配前面字符0次或者任意次
? 0或1次
- 1次或多次
{m} 匹配m次
{m,n} 至少m,至多n次
位置:
^ 行首
$ 行尾
^$ 空行
分组:
() 表示一个整体
egrep ‘r(oo)|(at)o‘ 1.txt 匹配roo或者ato
或者:
|
a|b a或b
C|cat C或cat
(C|c)at Cat或cat

















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









