






 本文深入解析边框回归的原理及实现细节,阐述了如何通过学习映射关系将Proposal转换为Ground-truth,包括中心点平移和尺度缩放的过程。讨论了正则化因子的重要性,并提出在训练对选取上的策略,即仅使用与Ground-truth高度重合的Proposal进行训练。
本文深入解析边框回归的原理及实现细节,阐述了如何通过学习映射关系将Proposal转换为Ground-truth,包括中心点平移和尺度缩放的过程。讨论了正则化因子的重要性,并提出在训练对选取上的策略,即仅使用与Ground-truth高度重合的Proposal进行训练。
1. 输入 :N 个训练对
,其中,
表示 的是Proposal的中心点坐标和宽高。
方便叙述,以下公式中上标i均略去显示。
另外, 表示的是Ground-truth 的 中心点坐标和宽高。
2.输出:预测的 ground-truth 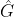
边框回归的目标是学习一种映射关系,来完成Proposal P到 ground-truth G的映射。
首先通过 和
完成中心点的平移,再通过
和
完成尺度的缩放
每个函数 可以被表示为Proposal P的 pool5 特征的线性函数,记为
。
即有:,其中
是可学习的模型参数向量。
可通过 优化正则化的最小均方误差损失学习到:
对于训练对(P,G)的回归目标定义如下:
作者实现边框回归的时候遇到2个小问题。第一,正则化因子非常重要,作者根据验证集设置 = 1000.
第二,选择训练对(P,G)的时候必须非常小心。 如果P和G离得太远,映射P到G会没有意义,这样的P会
导致学习不到东西。因此,作者只使用和G非常靠近的一些P(IoU > 0.6)来训练网络。作者通过给每个P指向
唯一的一个G(IOU最大且IOU>0.6)来实现 "距离最近"。

















 1210
1210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









