




 本文介绍了Spark在YARN模式下的工作原理,详细讲解了yarn-client和yarn-cluster两种模式的区别,以及如何通过spark-submit和IDEA提交YARN应用,包括配置步骤和实例演示。
本文介绍了Spark在YARN模式下的工作原理,详细讲解了yarn-client和yarn-cluster两种模式的区别,以及如何通过spark-submit和IDEA提交YARN应用,包括配置步骤和实例演示。
#Spark on Yarn
首先这部分分为源码部分以及实例部分,例子中包括最基本的通过spark-submit提交以及程序中提交yarn
这里仅仅说明Spark on Yarn的第一部分,分为三块:
- 原理
- spark-submit提交yarn程序
- IDEA代码提交yarn程序
##1 原理
Spark yarn 模式有两种, yarn-client, yarn-cluster, 其中yarn-client适合测试环境, yarn-cluster适合生产环境。
在详细说明Yarn模式之前, 需要先了解几个名词
ResourceManager: 整个集群只有一个, 负责集群资源的统一管理和调度, 因为整个集群只有一个,所以也有单点问题,
NodeManager: 它可以理解为集群中的每一台slave
AM: application master, 对于每一个应用程序都有一个AM, AM主要是向RM申请资源(资源其实就是Container, 目前这个Container就是cpu cores, memory), 然后在每个NodeManager上启动Executors(进一步分布资源给内部任务), 监控跟踪应用程序的进程等。
这里就引入了YARN的调度框架问题: 双层调度框架
(1)RM统一管理集群资源,分配资源给AM
(2)AM将资源进一步分配给Tasks
###1.1 Yarn-cluster模式
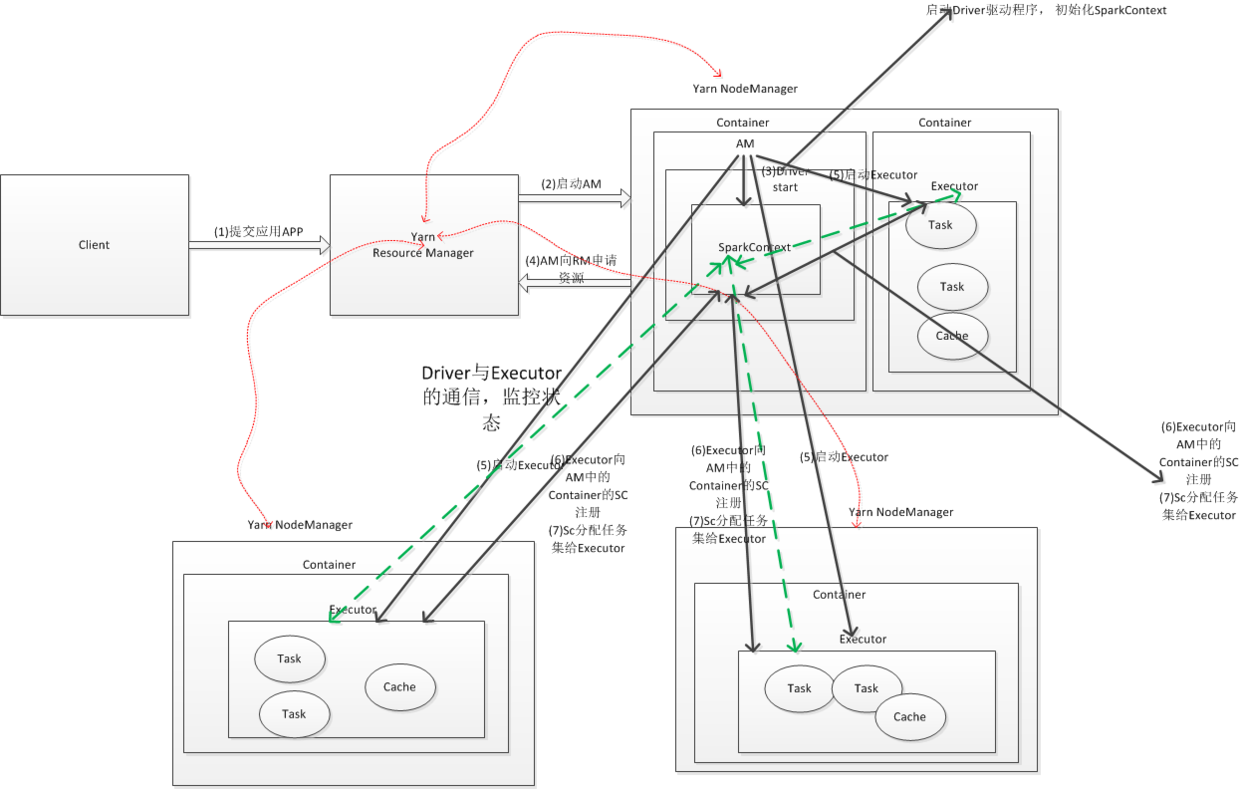
下面来具体说说Spark Yarn Cluster的流程:
(1) Client端启动应用程序,提交APP到YARN RM
(2)RM收到请求之后, 就会在集群中随机选择一个NM, 为该应用程序分配第一个Container, 然后在这个Contaiiner上启动AM,AM则实现了SC等的初始化
(3)AM启动时会向RM注册,并向RM申请资源
(4)AM一旦申请到资源也就是Container之后, 会在对应的Container(Container信息里面会包含NM节点信息)启动Executor
(5)AM的SC会分配任务及给Executor进行执行(之前Executor会去向AM中的SC注册), 同时EXecutor会向AM汇报运行的状态和进度,也就是上面绿色的通信
(6)AM向RM注册之后, AM会定时向RM汇报程序的运行状态等信息,也就是上面红色部分的通信。
###1.2 Yarn-client
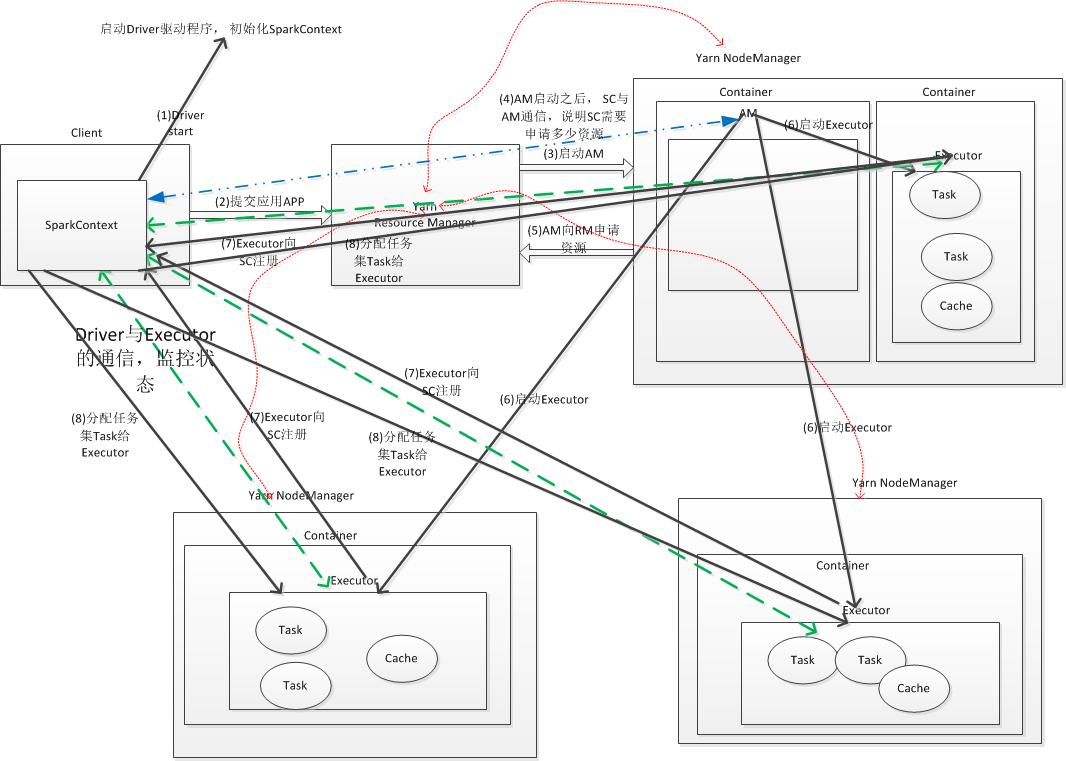
其具体流程和上面的yarn-cluster很类似
(1) Client端启动应用程序,提交APP到YARN RM, 这个过程则涉及到SC的初始化,SC启动时会去初始化DAGScheduler调度器, 使用反射方法去初始化YarnScheduler 和 YarnClientSchedulerBackend,最终Client会去向RM申请启动AM
(2)RM收到请求之后, 就会在集群中随机选择一个NM, 为该应用程序分配第一个Container, 然后在这个Contaiiner上启动AM,AM则实现了SC等的初始化, 此处与yarn-cluster不同的是,SC的初始化驱动程序的启动并不在AM中, 也就是AM并不是Driver端,但是AM会和SC通信来获取其需要的资源情况(多少cpu, 多少memory)
(3)当客户端的SC与AM启动完毕,会通信, AM可知道SC需要的资源情况, 然后AM会向RM注册, 并向RM申请资源Container
(4)AM申请到资源Container之后, 会与COntainer对应的NodeManager通信, 要求他在其Container里面启动Executor, 然后去向客户端的SparkContext注册, 并申请任务集Tasks
(5)客户端的SC分配任务集给Executor,
(6)应用程序运行结束之后,客户端的SC会向RM申请资源释放并去关闭自己,kill进程等
上面的流程介绍完之后, 来对比一下YARN-CLUSTER 与 yarn-client的区别:
其主要区别的是AM的作用不大一样,
yarn-client模式下:AM仅仅向RM请求资源, 然后AM会在对应的Container中要求其所属NodeManager去启动Executor, Client会去与此Container Executor通信, 也就是整个程序运行过程中, Client不能离开
yarn-cluster模式: Driver运行在AM中,也就是SC与Executor的所有通信操作都与Client无关了, 在提交完应用程序之后,Client就可以离开了。
##2 spark-submit提交到yarn
首先安装好Hadoop 并配置好Yarn, 之后启动sbin/start-yarn.sh
其次针对Spark的spark-env.sh里面增加:
export HADOOP_CONF_DIR=/home/kason/bigdata/hadoop-2.7.4/etc/hadoop
export YARN_CONF_DIR=/home/kason/bigdata/hadoop-2.7.4/etc/hadoop
下面说明一个最基本的应用程序
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkDEMO")
val sc: SparkContext = new SparkContext(conf)
val dataRDD: RDD[Int] = sc.parallelize(Array(1,2,3,4))
dataRDD.foreach(print)
print(dataRDD.count())
}
}
通过maven编译成jar包, 然后通过spark-shell去提交此jar包到yarn上
./bin/spark-submit --class SparkDemo --master yarn --deploy-mode cluster --driver-memory 1G --executor-memory 1G --executor-cores 1 /home/kason/workspace/BigdataComponents/SparkLearn/target/SparkLearn-1.0-SNAPSHOT.jar
提交之后显示:
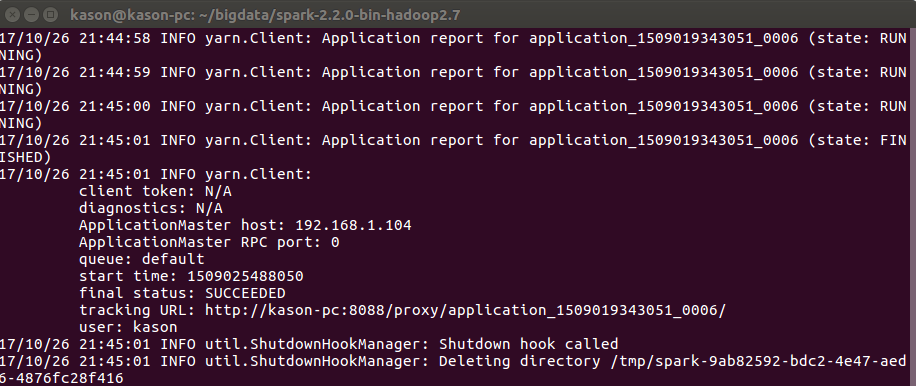
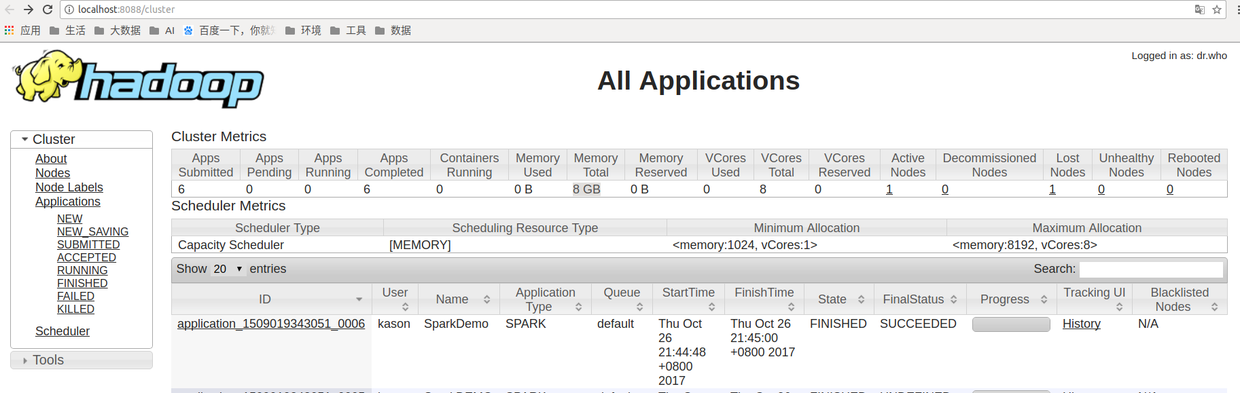
根据Yarn上的application id找到对应日志:
##3 IDEA代码提交到yarn
通过IDEA实现代码提交其实很简单, 主要是设置Master, Yarn模式不像mesos以及standalone模式通过传输url来实现资源管理, yarn模式实际上是Hadoop Yarn接管资源管理,具体代码如下:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkDEMO")
.setMaster("yarn")
//.setMaster("spark://kason-pc:7077")
.set("spark.yarn.jars","hdfs://kason-pc:9000/system/spark/yarn/jars/*")
.setJars(List("/home/kason/workspace/BigdataComponents/out/artifacts/SparkLearn_jar/SparkLearn.jar"))
//.setJars(GETJars.getJars("/home/kason/workspace/BigdataComponents/spark-main/target/spark-main/WEB-INF/lib"))
val sc: SparkContext = new SparkContext(conf)
val dataRDD: RDD[Int] = sc.parallelize(Array(1,2,3,4))
val result = dataRDD.map(res => res * 2)
result.collect().foreach(println(_))
print(result.count())
}
}
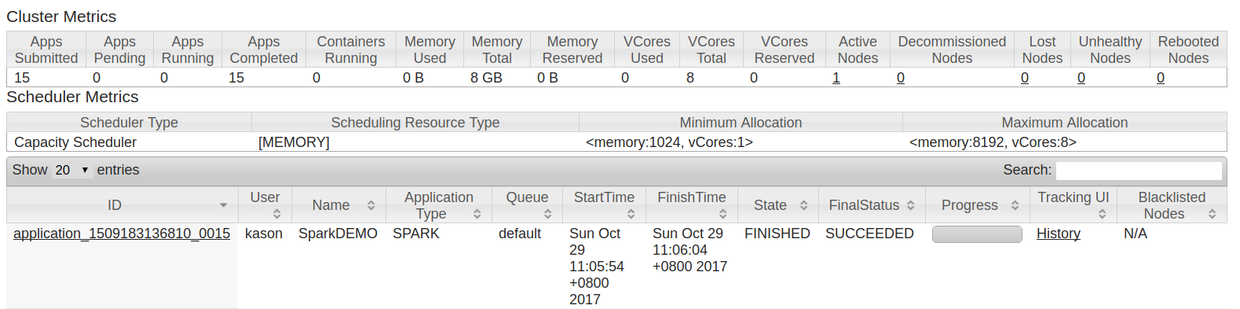
运行spark之后, 去8088yarn页面去查看一下:
注意IDEA代码提交到yarn只能使用yarn-client模式

















 2423
2423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









