




 本文介绍了SparkSQL中的关键概念,包括SparkSession、Dataset、Catalog、Catalyst等,并解释了这些组件如何共同工作来实现高效的数据处理。SparkSession是SparkSQL的入口点,而Dataset则是一种强类型的数据结构,用于表示结构化查询。
本文介绍了SparkSQL中的关键概念,包括SparkSession、Dataset、Catalog、Catalyst等,并解释了这些组件如何共同工作来实现高效的数据处理。SparkSession是SparkSQL的入口点,而Dataset则是一种强类型的数据结构,用于表示结构化查询。
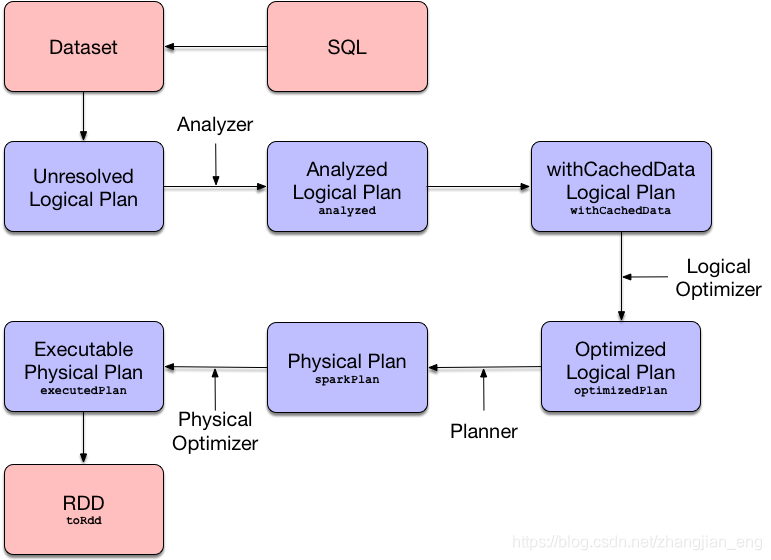
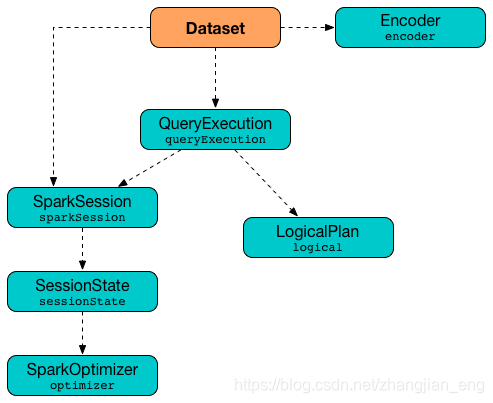
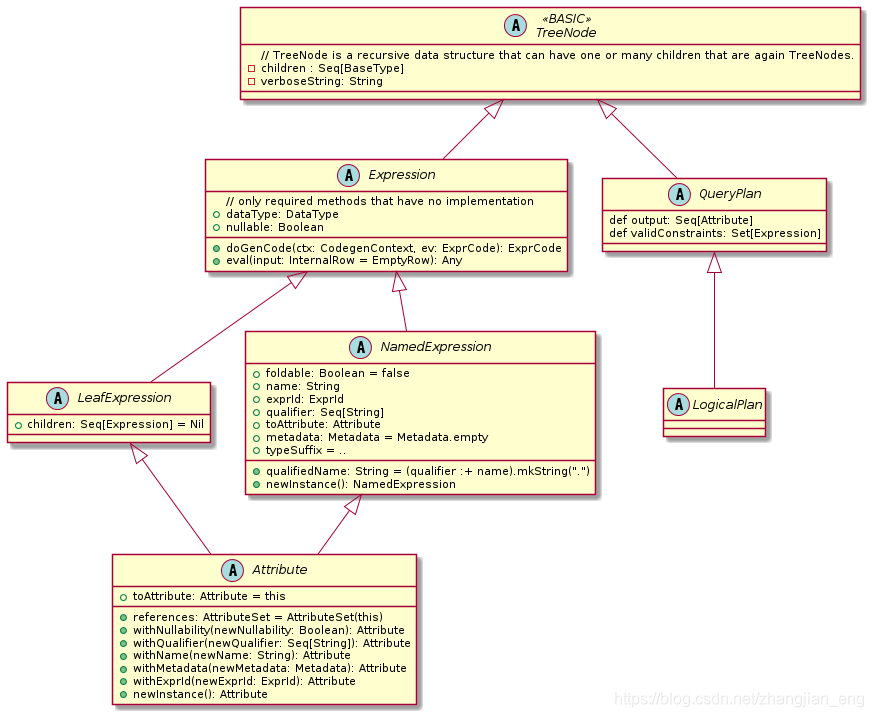
| 角色 | 说明 |
|---|---|
| Spark Session | SparkSession 是 Spark SQL 的入口点。它是您在开发 Spark SQL 应用程序时创建的第一个对象之一。作为 Spark 开发人员,您可以使用SparkSession.builder方法(该方法使您可以访问用于配置会话的Builder API)创建一个 SparkSession |
| Dataset | Dataset是 Spark SQL 中的强类型数据结构,表示结构化查询。 |
| Catalog | Metastore管理据接口,存储关系和实体的对应关系,实体如databases、tables、views、functions、columns,SparkSession.catalog property. |
| Catalyst | Catalyst 是一个与执行无关的框架,用于表示和操数据流图,即关系运算符和表达式的树。 |
| TreeNode | Catalyst 数中的根节点或者子树 |
| Expression | Expression 是一个可执行节点(在 Catalyst 树中),它可以在给定输入值的情况下确定结果值,每个内部Row可以生成一个 Java 对象 |
| QueryPlan | QueryPlan 是Catalyst 的一部分,用于构建结构化查询的关系运算符树。 Scala 特有的,是一个抽象类,它是LogicalPlan和SparkPlan(分别用于逻辑和物理计划)的基类。 QueryPlan |
参考:
1)https://cwiki.apache.org/confluence/display/KYLIN/Introduction+to+Internal+of+Spark+SQL

















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









