




JVM运行时数据区相关组成看下图:
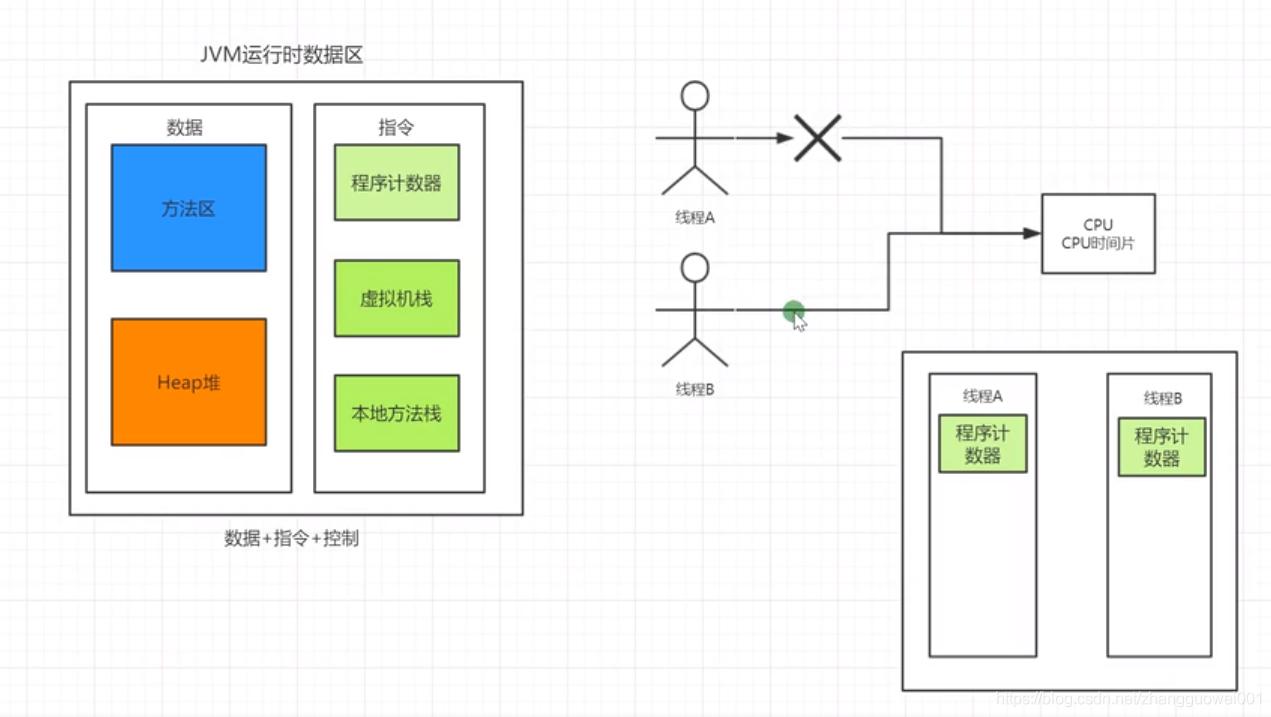
1 不同线程有自己的程序计数器,虚拟机栈和本地方法栈,但是公用方法区和Heap堆,因此多线程运行会有安全问题
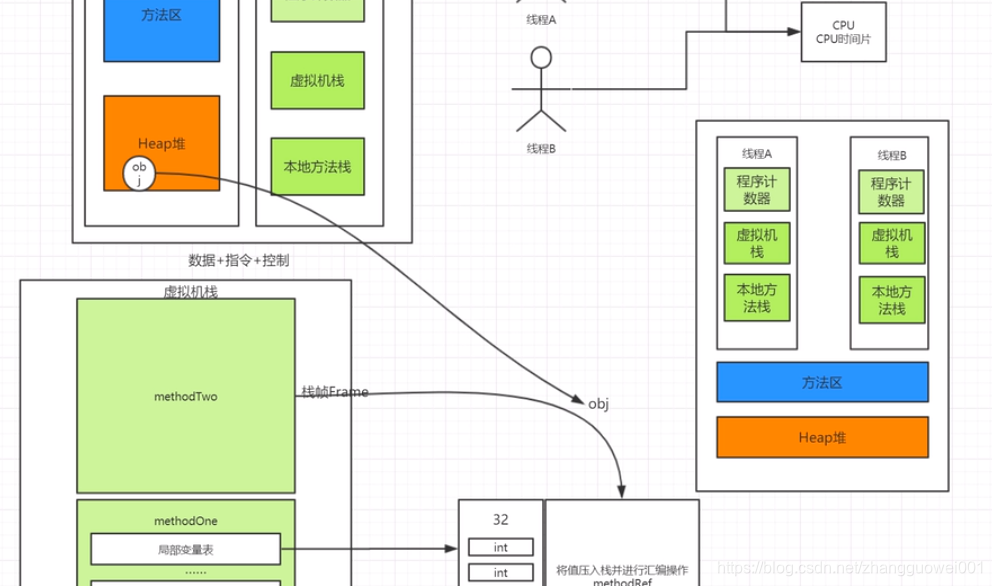
2 栈(stack)是存放方法的局部变量的内存空间,每个方法都会分配一块内存空间frame,方法一旦执行完成,frame就被销毁,对于原始类型,变量的值也保存在stack中,对于引用类型,stack里保存的是指向对象的内存地址(引用)
栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享
栈的概念:是弹压,就像子弹壳装弹,一粒一粒压进去,但是打出来的时候是从上面打出来的,最先压进去的最后弹出来,如果进去顺序是123,打出来顺序是321,这就是后进先出
3 堆(heap)是存放的Object,java是传值的,不是传引用的。
4 队列就是按次序来,先进先出,先到先来
5 垃圾回收器GC(Garbage Collection):
局部变量方法在执行完后内存马上被回收。
Heap里面的对象由GC自动回收。
GC维护和检测对象的引用,当引用数为0时自动回收。
GC并不是实时回收的。
以下面的程序为例来说明jvm内存中的Stack,Heap和GC(垃圾回收):
public class MakeMoney {
public static void main(String [] args){
double rate = 30;
double money = 0.0;
Person zhangsan = new Person("张三",50);
money = task1(rate);
money = money+task2(zhangsan);
System.out.println("张三一共赚了" + money +"元");
}
public static double task1(double rate){
int hour = 5;
return rate*hour;
}
public static double task2(Person person){
int hour = 6;
return hour*person.rate;
}
}
class Person{
private String name;
public double rate;
public Person(String name,double rate){
this.name = name;
this.rate = rate;
}
}
第一步:在程序未执行时的堆栈如下图

第二步:开始执行main()方法,首先jvm会先为main方法分配一段内存空间,内存又依次为rate,money,zhangsan开辟空间,因为zhangsan是引用数据类型,所以jvm会在Heap中创建对象,分配一段内存空间,Stack中的zhangsan指向Heap中为zhangsan这个对象的内存地址

第三步:接着执行task1,jvm为task1方法分配内存空间,task1中有两个变量rate和hour,jvm会从main的内存中将rate的的值传递过来,同时为hour分配空间,如下图

第四步:task1执行完,jvm会自动释放内存,task1的内存块将不存在

接下来将执行task2,传递一个person进来,jvm会给person和hour分配内存空间,person同样指向heap中的内存空间,它是main方法中zhangsan的引用
最后,task2执行完后,jvm自动回收task2的内存空间,接着回收main函数的内存空间,然后没有任何对象指向Heap中的zhangsan,jvm就会回收Heap中的zhangsan对象的内存空间

部分素材出自:
作者:Veteor
链接:https://www.jianshu.com/p/26fe70b000b4
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。

















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









