









http://my.oschina.net/u/811744/blog/192604(本文的转载地址)
依然采用IE的F12开发者工具分析抓取到的数据。
关键问题
获取token后,重定向地址的获取
一般网站登录成功后,跳转方式主要有两种:(1)服务器返回的响应头中包含 location header,该header为重定向地址,获取该header内容,访问即可。(2)服务器返回的响应内容中,包含使用javascript方法生成的重定向地址,使用正则表达式获取window.location.replace("redirected URL")内容。
然而,这两种方式都不能获取淘宝的重定向地址。经分析,想拿到淘宝中的个人数据要分三步:(1)淘宝登录,获取token值。(2)根据获取的token值,得到st值。(3)根据获得到的st值,获取重定向地址。
获取个人相关信息
获得重定向地址后,后面的事情就简单多了。打开重定向地址,从返回的html信息中提取相应的地址信息即可。
分析过程
下面红线圈出的是比较重要的信息。需要仔细分析。第一个POST方法是提交登录参数,返回参数中包含token值,那么下面紧跟着的GET方法作用是什么呢?还记得上面提到说要获取淘宝个人数据分三步吧?没错!下面两个分别是获得st值及重定向地址

再来看看第一个GET方法的详细信息,可看到传递的参数中有token值
其响应信息如下,一段js脚本
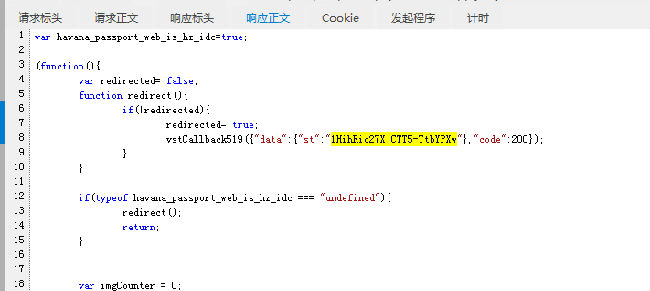
接着,看第二个GET请求的详细信息,地址中包含刚刚得到的st值及其他参数值

其响应如下,返回值包含一个url

对比发现,与下面打开的url一致,即为重定向地址。
完整代码
# -*- coding:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
|
# -*- coding: utf-8 -*-
import
urllib
import
urllib2
import
cookielib
import
re
#登录地址
checkCodeUrl
=
''
#post请求头部
headers
=
{
'x-requestted-with'
:
'XMLHttpRequest'
,
'Accept-Language'
:
'zh-cn'
,
'Accept-Encoding'
:
'gzip, deflate'
,
'ContentType'
:
'application/x-www-form-urlencoded; chartset=UTF-8'
,
'Host'
:
'login.taobao.com'
,
'DNT'
:
1
,
'Cache-Control'
:
'no-cache'
,
'User-Agent'
:
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:14.0) Gecko/20100101 Firefox/14.0.1'
,
'Referer'
:
'https://login.taobao.com/member/login.jhtml?redirectURL=http%3A%2F%2Fwww.taobao.com%2F'
,
'Connection'
:
'Keep-Alive'
}
#用户名,密码
username
=
raw_input
(
"Please input your username in taobao: "
)
password
=
raw_input
(
"Please input your password of taobao: "
)
#请求数据包
postData
=
{
'TPL_username'
:username,
'TPL_password'
:password,
"need_check_code"
:
"false"
,
"loginsite"
:
0
,
"newlogin"
:
1
,
'TPL_redirect_url'
:'',
'from'
:
'tbTop'
,
'fc'
:
"default"
,
'style'
:
'default'
,
'css_style'
:'',
'tid'
:'',
'support'
:
'000001'
,
'CtrlVersion'
:
'1,0,0,7'
,
'loginType'
:
3
,
'minititle'
:'',
'minipara'
:'',
"umto"
:
"NAN"
,
'pstrong'
:
2
,
'llnick'
:'',
'sign'
:'',
'need_sign'
:'',
"isIgnore"
:'',
"full_redirect"
:'',
'popid'
:'',
'callback'
:
'1'
,
'guf'
:'',
'not_duplite_str'
:'',
'need_user_id'
:'',
'poy'
:'',
'gvfdcname'
:
10
,
'from_encoding'
:'',
"sub"
:'',
"allp"
:'',
'action'
:
'Authenticator'
,
'event_submit_do_login'
:
'anything'
,
'longLogin'
:
0
}
#登录主函数
def
loginToTaobao():
#cookie 自动处理器
global
checkCodeUrl
cookieJar
=
cookielib.LWPCookieJar()
#LWPCookieJar提供可读写操作的cookie文件,存储cookie对象
cookieSupport
=
urllib2.HTTPCookieProcessor(cookieJar)
opener
=
urllib2.build_opener(cookieSupport, urllib2.HTTPHandler)
urllib2.install_opener(opener)
#打开登陆页面
taobao
=
urllib2.urlopen(tbLoginUrl)
resp
=
taobao.read().decode(
"gbk"
)
displayCookies(cookieJar)
#提取验证码地址
pattern
=
r
'img id="J_StandardCode_m" src="https://s.tbcdn.cn/apps/login/static/img/blank.gif" data-src="(\S*)"'
checkCodeUrlList
=
re.findall(pattern, resp)
checkCodeUrl
=
checkCodeUrlList[
0
]
print
"checkCodeUrl:"
, checkCodeUrl
#此时直接发送post数据包登录
result
=
sendPostData(tbLoginUrl, postData, headers)
#此时默认不需要输入验证码
print
"result: "
, result
while
(
not
result[
"state"
]):
print
"failed to login in, error message: "
,result[
"message"
]
if
result[
"code"
]
=
=
"3425"
or
result[
"code"
]
=
=
"1000"
:
getCheckCode(checkCodeUrl)
result
=
sendPostData(tbLoginUrl, postData, headers)
print
"result: "
, result
print
"successfully login in!"
#获取st值
url
=
url
+
"&token="
+
result[
"token"
]
+
"&callback=vstCallback519"
text
=
urllib2.urlopen(url).read()
print
text
displayCookies(cookieJar)
st
=
re.search(r
'"st":"(\S*)"( |})'
,text).group(
1
)
print
st
#获取重定向地址
myTaobaoUrl
=
myTaobaoUrl
+
"st="
+
st
+
"&"
+
"TPL_uesrname=sunecho307"
myTaobao
=
urllib2.urlopen(myTaobaoUrl)
print
myTaobao.read()
displayCookies(cookieJar)
def
displayCookies(cookiejar):
print
"+"
*
20
+
"displayCookies"
+
"+"
*
20
for
cookie
in
cookiejar:
print
cookie
def
sendPostData(url, data, header):
print
"+"
*
20
+
"sendPostData"
+
"+"
*
20
data
=
urllib.urlencode(data)
request
=
urllib2.Request(url, data, header)
response
=
urllib2.urlopen(request)
#url = response.geturl()
text
=
response.read().decode(
"gbk"
)
info
=
response.info()
status
=
response.getcode()
response.close()
print
status
print
info
print
"Response:"
, text
result
=
handleResponseText(text)
return
result
def
handleResponseText(text):
"""处理登录返回结果"""
print
"+"
*
20
+
"handleResponseText"
+
"+"
*
20
text
=
text.replace(
','
,
' '
)
responseData
=
{
"state"
:
False
,
"message"
: "",
"code"
: "",
"token"
: ""}
m1
=
re.match(r
'\{?"state":(\w*)\ '
, text)
if
m1
is
not
None
:
s
=
m1.group(
1
)
if
s
=
=
"true"
:
responseData[
"state"
]
=
True
#提取token
m4
=
re.search(r
'"token":"(\w*)"( |})'
, text)
if
m4
is
not
None
:
responseData[
"token"
]
=
m4.group(
1
)
else
:
m2
=
re.search(r
'"message":"(\S*)"( |})'
, text)
if
m2
is
not
None
:
msg
=
m2.group(
1
)
responseData[
"message"
]
=
msg
else
:
print
"failed to get the error message"
m3
=
re.match(r
'.+\"code":(\w*)\ '
, text)
if
m3
is
not
None
:
code
=
m3.group(
1
)
responseData[
"code"
]
=
code
else
:
print
"failed to get the error code"
return
responseData
def
getCheckCode(url):
print
"+"
*
20
+
"getCheckCode"
+
"+"
*
20
response
=
urllib2.urlopen(url)
status
=
response.getcode()
picData
=
response.read()
path
=
"C:\\Users\\Echo\\Desktop\\checkcode.jepg"
if
status
=
=
200
:
localPic
=
open
(path,
"wb"
)
localPic.write(picData)
localPic.close()
print
"请到%s,打开验证码图片"
%
path
checkCode
=
raw_input
(
"请输入验证码:"
)
print
checkCode,
type
(checkCode)
postData[
"TPL_checkcode"
]
=
checkCode
postData[
"need_check_code"
]
=
"true"
else
:
print
"failed to get Check Code, status:"
,status
if
__name__
=
=
"__main__"
:
loginToTaobao()
|
总结
在前两篇的基础上,增加了一些功能:(1)验证码输入错误,可以重复输入(2)获取淘宝中的个人相关信息,目前还不完善,只能得到登录后页面的html信息,相关信息还未提取,后面补充。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









