






 Hive 是一个构建在 Hadoop 之上的数据仓库工具,支持 SQL-92 标准,通过 HQL 实现对 HDFS 中结构化数据的统计分析。Hive 不支持随机修改表中的数据及追加操作。其架构包括元数据存储和 Driver 组件,支持表、分区和分桶等数据模型。
Hive 是一个构建在 Hadoop 之上的数据仓库工具,支持 SQL-92 标准,通过 HQL 实现对 HDFS 中结构化数据的统计分析。Hive 不支持随机修改表中的数据及追加操作。其架构包括元数据存储和 Driver 组件,支持表、分区和分桶等数据模型。
简介
Hive由Facebook开源,是一个构建才hadoop之上到数据仓库工具,可以把hdfs上到结构化数据映射成表,并通过mapreduce进行统计分析。Hive支持SQL-92标准,通过HQL屏蔽了复杂到MapReduce,但由于hadoop本身的限制,hive不支持随机修改表中的数据,也不支持追加操作。
Hive的优点
- 学习成本低
- 能够快速实现复杂的数据分析
- 屏蔽mapreduce
Hive的架构
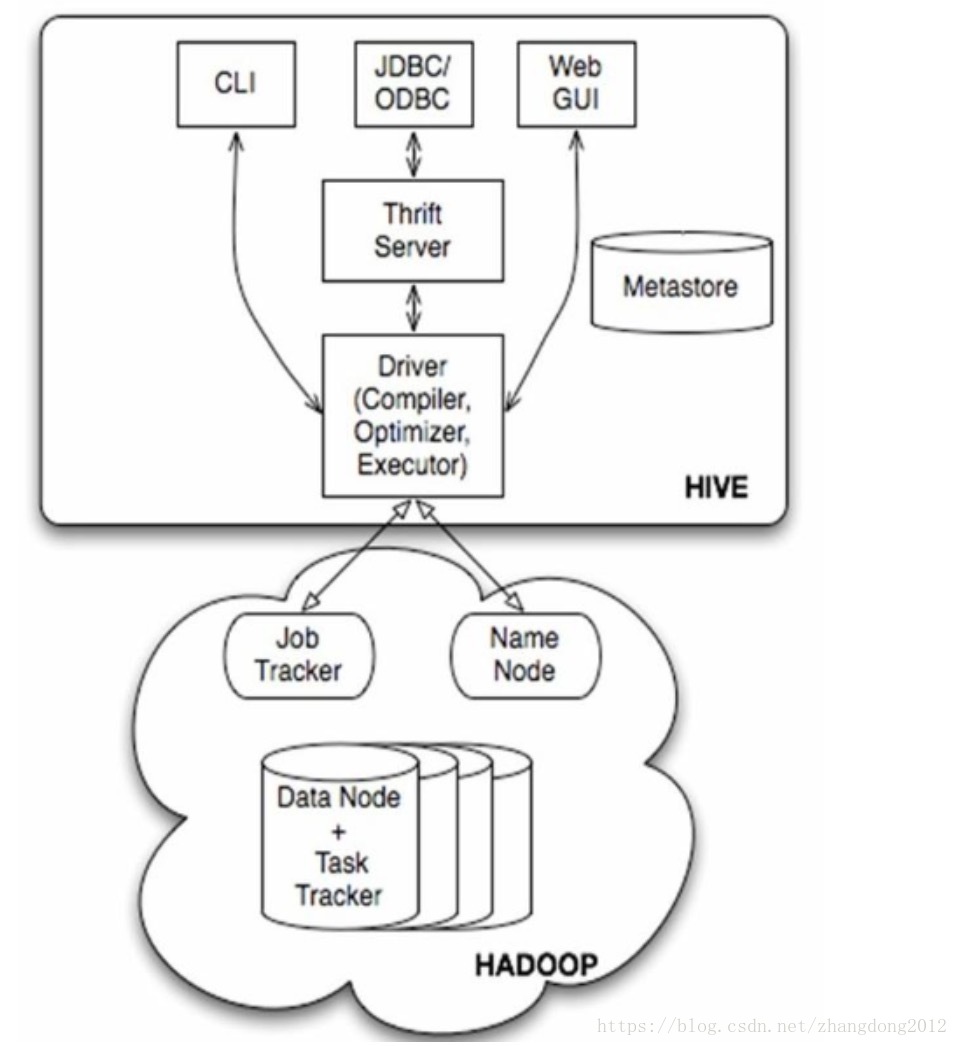
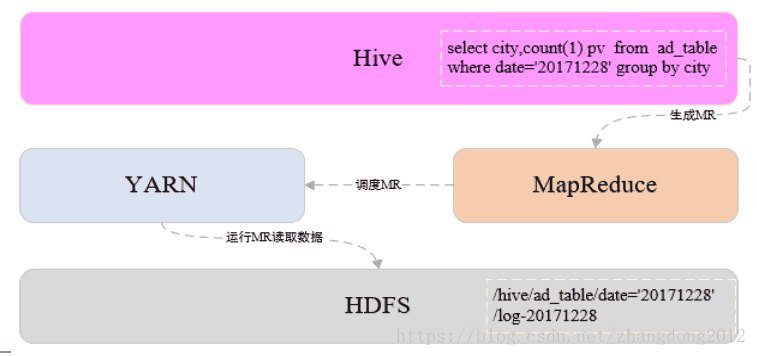
Hive构建在Hadoop之上,通过一个解析引擎和一组元数据将HQL映射成MapReduce任务。
元数据存储了表名/列名/字段名/类型/分区/分桶等详细信息,是一个非常重要等组件。Hive提供的存储元数据信息的方式有两种,一种是基于内置derby数据块,这种模式下只支持最多一个用户访问hive,当客户端Session关闭后,所有元数据信息都会失效,derby数据库被释放;另外一种是基于外部数据库(MySQL等),这种模式由于元数据被集中存储,多个客户端就可以共享。
Driver是Hive等核心组件,类似于Mapreduce等shuffle,是奇迹发生等地方,解析HQL,优化执行计划以及提交MapReduce到Yarn都是Driver都工作。
Hive的数据模型
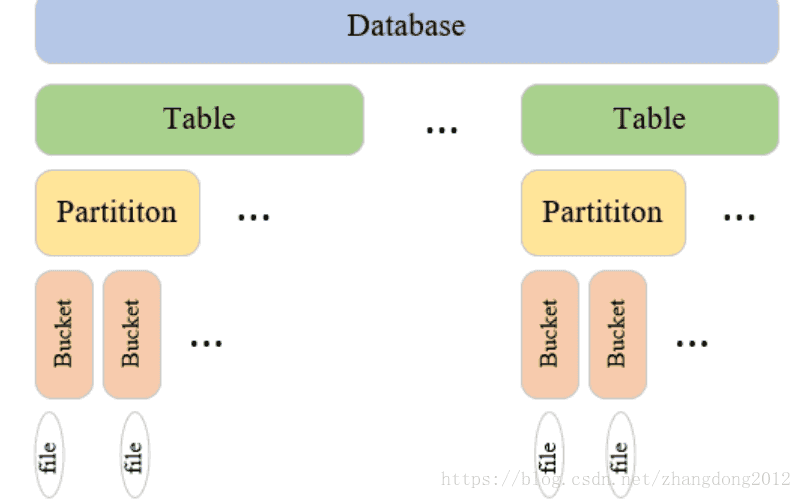
Hive与RDB一样,也是用数据库和表形式来组织数据的,但不同的是,hive在表的基础上提供来分区和分桶的概念,主要的作用都是最小化一次查询的扫描范围。
分区
分区是在表的基础上进行的,在建表时,可以指定分区字段,不同的分区在hdfs上表现为不同的目录。
在选择分区字段时,尽量选择离散字段。
分桶
每个表或分区可以进一步划分桶,桶是一种比分区更细粒度的划分,可以类比Java中Hashmap,主要作为是提高查询效率
数据类型
基本类型
整数类型:tinyint, samllint, int, bigint
浮点类型:float,double
布尔类型:boolean
字符串类型:string复杂类型
数组:array,eg:array<String>
映射:map,eg:map<string,int>
复合类型:struct,eg:struct<city:string, age:int>存储格式
- textfile:默认存储格式,创建表时需要指定分隔符,存储开销和解析开销比较大
- SequenceFile:hadoop提供的一种二进制存储格式,可按行分割并压缩
- RCFile/Orc:列式存储格式


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









