




 HDFS是基于Google GFS论文设计的分布式文件系统,具备高容错和可扩展性。主要由NameNode、DataNode和SecondayNameNode组成。NameNode管理元数据,DataNode存储数据。在Hadoop 2.2后,NameNode的高可用通过Zookeeper实现。HDFS读取和写入流程涉及NameNode和DataNode的交互,确保数据的正确性和可靠性。元数据管理包括内存中的元数据、编辑日志和镜像文件,SecondaryNameNode负责元数据的合并和备份。数据容错通过副本冗余实现,而集群容错则利用Zookeeper进行NameNode的主备切换。
HDFS是基于Google GFS论文设计的分布式文件系统,具备高容错和可扩展性。主要由NameNode、DataNode和SecondayNameNode组成。NameNode管理元数据,DataNode存储数据。在Hadoop 2.2后,NameNode的高可用通过Zookeeper实现。HDFS读取和写入流程涉及NameNode和DataNode的交互,确保数据的正确性和可靠性。元数据管理包括内存中的元数据、编辑日志和镜像文件,SecondaryNameNode负责元数据的合并和备份。数据容错通过副本冗余实现,而集群容错则利用Zookeeper进行NameNode的主备切换。
HDFS源自于Google在2003年10月发表的GFS论文,它是一个分布式文件系统,具有高容错,易扩展,存储量大,能够运行在廉价机上等特点,已经被很多企业广泛引用于基础等存储服务。
组件
HDFS中等核心组件主要有两个,一个是NameNode,一个是DataNode。
NmeNode负责管理集群等元数据信息,以及数据分布,DataNode负责存储具体等数据。HDFS存储数据的基本单位是数据块block,默认大小为128M,一个大文件会被拆分成多个数据块,存储在DataNode上。
另外还有一个辅助组件SecondayNameNode,它的主要作用是合并NameNode上的编辑日志和镜像文件,确保编辑日志不会过大,另外在Hadoop早起版本中,SecondayNamenode还作为NameNode的冷备。
架构
HDFS采用主从这种经典的分布式系统架构,如下图所示:
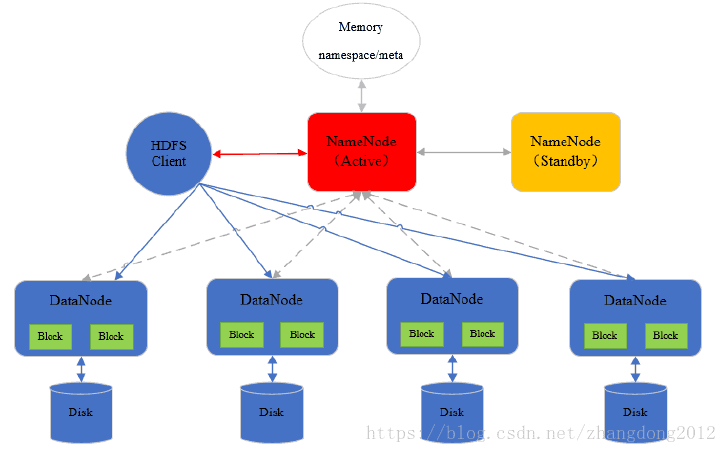
在Hadoop2.2以后,NameNode的高可用依赖于zookeeper来实现动态的这备切换,集群元数据信息通过QJM等高可用的共享存储系统在主备NameNode之间共享。
读流程
HDFS的数据读取流程如下图所示
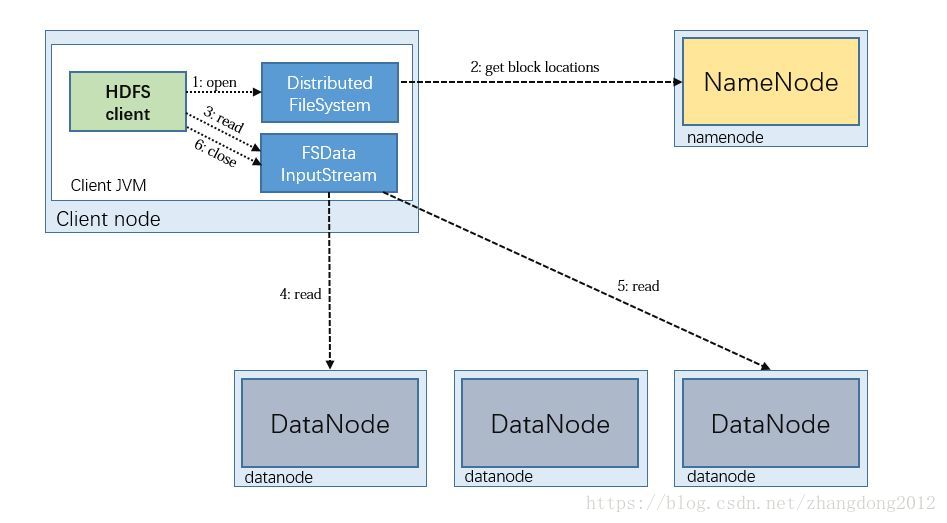
1)客户端请求NameNode读取数据,NameNode进行权限及文件是否存在等校验
2)NameNode定位到组成该文件的block列表,并按照就近原则返回给客户端存储了第一个block的datanode
3)客户端与dataNode通信,读取第一个bock块,然后在向namenode请求第二个bl
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









