




 本文详细介绍了Redis的核心数据结构如string、list等,以及在数据缓存、计数器等场景的应用。还深入讨论了持久化策略,包括RDB、AOF及混合模式的优缺点。此外,分析了Redis的集群架构,包括主从、哨兵和Cluster模式,并提到了常见的缓存问题和分布式锁的实现。最后,强调了使用Redis时的一些注意事项,如避免大value和过多元素,以及利用Redission和Lua脚本增强功能。
本文详细介绍了Redis的核心数据结构如string、list等,以及在数据缓存、计数器等场景的应用。还深入讨论了持久化策略,包括RDB、AOF及混合模式的优缺点。此外,分析了Redis的集群架构,包括主从、哨兵和Cluster模式,并提到了常见的缓存问题和分布式锁的实现。最后,强调了使用Redis时的一些注意事项,如避免大value和过多元素,以及利用Redission和Lua脚本增强功能。
核心数据结构
- string
- list
- set
- sorted set
- hash
应用场景
- 数据缓存
- 计数器
- 分布式锁
- 分布式session
- 全局序号生成器
- 购物车
hset cart:userid goodsid nums #加入商品到购物车
hincrby cart:userid goodsid #调整商品数量
hlen cart:userid #获取商品总数量
hdel cart:userid goodsid #删除购物车中的商品
hgetall cart:userid #获取所有商品
- 抽奖
sadd key userid #参与抽奖
smemebers key #查看所有参与者
srandmember key count/spop key count #抽奖
- 排行榜
zincrby hotnews20191112 1 news01 #一次点击,score + 1
zrevrange hotnews20191112 0 10 withscore # 倒序取点击量在前10的news
#合并多天的数据
zunionstore hotnews_20191112-20191113 hotnews20191112 hotnews20191113
#获取合并后的前10名
zrevrange hotnews_20191112-20191113 0 10 withscores
-分布式锁
#加锁
set lockkey 0 ex 5 nx
#解锁
del lockkey
持久化策略
redis提供了三种持久化策略,分别是:RDB、AOF和混合持久化模式。
RDB是通过数据快照的方式进行数据持久化的,可以通过修改配置文件的save参数来指定持久化策略:
# 900秒内有一次修改
save 900 1
#300秒内有10次修改
save 300 10
#60秒内有1000次修改
save 60 1000
RDB的持久化方式产生的rdb文件是二进制格式,体积比较小,利用rdb文件进行数据恢复的时候速度会比较快,但是,由于是间隔性执行,所以会造成数据丢失,使用的时候还要看业务上能否接收。
AOF持久化方式是通过记录写命令来实现的,通过以下的配置来开启AOF持久化策略:
appendonly yes #开启aof持久化
appendsync always #实时记录没一个写命令
appendsync everysec #每秒钟记录一次(最常用)
appendsync no #不主动记录,交给操作系统?
auto-aof-written-min-size 64m #aof文件重写策略-按照aof文件大小来触发重写
auto-aof-written-percentage 100 #按照文件的增长率来触发aof文件重写
AOF这种持久化策略的好处是不会造成数据丢失,但是aof文件一般会比rdb文件大很多,所有,redis也提供了aof文件重写功能,可以对aof文件中可以进行合并的命令进行合并。但是使用aof文件进行数据恢复的速度要比rdb文件要慢。
混合持久化模式是综合了RDB和AOF各自优势,当触发aof重写时,会将内存中的数据以rdb的格式写入aof文件,在下次aof重写之前,所有的写操作都会以命令行的方式追加到aof文件中。
集群架构
redis的常见集群架构主要有三种,分别是:主从模式、哨兵模式和Cluster模式,这三种架构的结构图大概如下图所示:
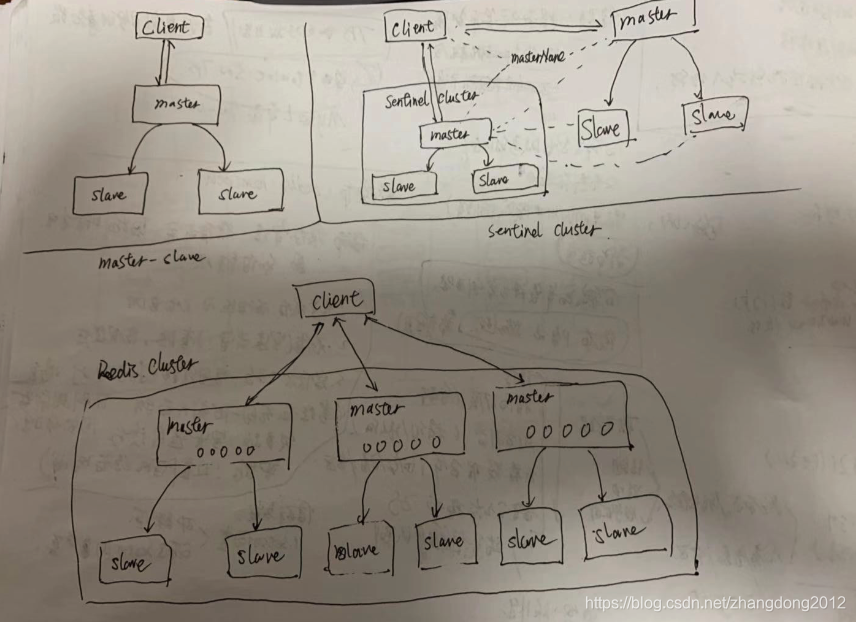
其中,master-slave模式类似于mysql的主备模式,可以用来做数据备份和读写分离,但是,由于redis集群通常要求HA,所以这种主从模式很少引用,主从数据复制的过程如下:
- slave加入到集群,向master发起数据同步请求;
- master节点fork主子线程对当前内存数据做rdb快照,并缓存期间接收到的写请求命令;
- master将rdb快照文件发送给slave,slave完成数据回放后,master在将增量数据发给slave;
- 后续slave进入增量同步;
哨兵模式是在主从模式的基础上改进而来的,在主从模式下引入哨兵,来监控主从集群的状态,客户端通过哨兵集群来获取master节点的链接信息,然后再去与master节点进行数据交互,如果master节点宕机,那么,哨兵会通过修改配置文件+重启的方式来切换集群的master节点,修改后的master节点能够通过哨兵被客户端感知到,但是在哨兵模式下,将slave拉到master的过程比较慢,会造成redis集群一段时间的不可用,如果业务流量比较大的话,缓存集群不可用是很可怕的,要根据业务特点谨慎选择。
集群模式是目前比较推荐的redis高可用架构,这种架构内部又一个个小的master-slave组成,节点互为主备,同时,每个节点会被redis划分成若干个槽位,然后采用一致性hash的方式来存取数据,这又两个好处,一是redis集群可以水平扩展,不像哨兵模式下服务能力受master节点的限制,二是可以最大程度上减小由于节点宕机造成的影响,因为cluster内部的一个master-slave只存储了一部分数据,即使某一个master宕机并进程master-slave切换的过程中,也不会对所有key产生影响。redis默认将所有master划分成16384个槽位,但这个数量可以通过配置进行调整。
常见问题
- 缓存穿透
缓存穿透指的是请求那些在数据库中不存在、在缓存中也不存在的数据,解决这个问题的方式通常有两种:
- 对请求参数进行校验,过滤一部分不合法的数据
- 对null值做缓存,并设置一个过期时间,防止后续有有数据了,比如请求一个id=50的商品信息,
此时没有,但后续管理员增加了一个id=50的商品。
- 缓存击穿
缓存击穿指的是某一个热点key在某个时间失效了,导致大量请求透过缓存打到数据库上,这种问题可以从缓存和业务代码
两个方面来解决
- 将热点key设置为永不过期
- 通过加锁的方式将并发请求这个key的线程进行同步处理,确保只有一个线程会去查数据库并对缓存进行重建
- 缓存雪崩
缓存雪崩指的是大片的缓存数据在同一时刻失效了,导致大量请求打到数据库,把数据库压块,最终造成整个系统不可用
- 可以随机设置key的过期时间,避免同时失效(个人觉得这个解决方案比较好)
- 可以根据数据的特点进行分区存储,例如按照地域或类别等
- 设置永久过期
Redis分布式锁
参考:https://blog.youkuaiyun.com/kongtiao5/article/details/102659153
- 加锁
public boolean lock(String value)
{
//这里的setnx和expire可以合并成一条指令
if (jedisTemplate.setnx(LOCK_KEY, value))
{
jedisTemplate.expire(LOCK_KEY,5,TimeUnit.SECONDS);
return true;
}
return false;
}
- 解锁
public boolean unlock(String value)
{
String script =
"if redis.call('get',KEYS[1]) == ARGV[1] then" +
" return redis.call('del',KEYS[1]) " +
"else" +
" return 0 " +
"end";
try
{
Object result = jedis.eval(script, Collections.singletonList(LOCK_KEY),
Collections.singletonList(value));
if("1".equals(result.toString()))
{
return true;
}
return false;
}
catch(Exception e)
{
return false;
}
finally
{
jedis.close();
}
}
一些使用上的注意事项
- 保证key的可读性,做到见名思意;
- 保证key的简介,避免过长,会占用redis内存;
- key值不要包含特殊字符;
- 避免value体积过大,例如list中元素太多货哈希中field的太多;
- 避免调用耗时操作,例如keys,或在大value上调用类似hgetall 这种操作;
- string类型的value建议不要超过10kb;
- list中的元素尽量不要超过5000个;
由于redis是单线程模型,大value或耗时的操作会导致后续操作被阻塞。
其他
Redision
Lua脚本

















 5867
5867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









