



1.概述
本文基于文件加载器(PyPDFLoader)、向量库(Chroma)和langgraph工作流构建一个RAG应用。
工作流思路如下:
1)进入chatbot节点。chatbot节点根据用户输入确定是否需要调用工具,如果不需要调用工具,则直接生成应答,否则执行function calling,并进入工具节点
2)工具节点调用工具进行检索,并判断检索结果是否与问题相关,如果不相关则进入问题重写节点对问题进行改写,如果相关则进入生成解答节点。
3)问题重写节点调用大模型对问题进行改写,改写后再次进入chatbot节点
4)生成解答节点根据用户请求和检索的上下文生成最后的应答
2.文档分块
2.1加载文档
首先,安装PDF文件加载包pypdf:
#pip install pypdf
# pip install langchain-chroma
加载文件,代码如下:
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = PyPDFLoader ("../data/beijing_annual_report_2024.pdf")
docs = loader.load()
docs为Document类型的数组,每页都是一个Document对象,查看一下文档页数和第一页的内容:
print(f"####len = {len(docs)}####")
docs[0].page_content
输出内容如下,共13页文档:
####len = 13####
'各位代表:\n现在,……;支持**新区“三校一院”交钥匙项目开\n学开诊,公共服务共建共享不断深化。'
2.2.文档分块
langchain提供了多种分块器,分别适用不同的场景。这里选用最常用的递归字符文本分块器。
from langchain.text_splitter import RecursiveCharacterTextSplitter
character_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", ",", "、", ";", ""],#块分隔符
chunk_size=1000, #块大小
chunk_overlap=0) #块重叠大小
splits = character_splitter.split_docoments(docs)
查看一下有多少块:
len(splits)
3.向量化存储
本文使用chroma文件存储,当然生产系统肯定要使用服务器存储。
首先导入相关的库:
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_chroma import Chroma
使用向量库时必须先初始化嵌入模型,这里使用text2vec-base-chinese嵌入模型:
embedding = HuggingFaceEmbeddings(
model_name='../models/text2vec-base-chinese' # 高效的语义模型
)
把分块数据加载到chroma向量库中:
persist_directory = "../data/chroma" #chroma库文件路径
vectordb = Chroma.from_documents(
documents=splits,
embedding=embedding,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
进行语义查询:
vectordb.similarity_search("关于就业相关数据", k=2)
结果如下:
[Document(metadata={'comments': '', 'page': 2, 'sourcemodified': "D:20240208203412+12'34'", 'subject': '', 'author': 'sky', 'producer': '', 'moddate': '2024-02-08T20:34:12+12:34', 'keywords': '', 'creator': 'WPS 文字', 'trapped': '/False', 'creationdate': '2024-02-08T20:34:12+12:34', 'total_pages': 13, 'title': '', 'page_label': '3', 'source': '../data/beijing_annual_report_2024.pdf', 'company': ''}, page_content='四是……),
Document(metadata={'sourcemodified': "D:20240208203412+12'34'", 'creator': 'WPS 文字', 'page_label': '3', 'creationdate': '2024-02-08T20:34:12+12:34', 'moddate': '2024-02-08T20:34:12+12:34', 'comments': '', 'producer': '', 'keywords': '', 'source': '../data/beijing_annual_report_2024.pdf', 'page': 2, 'company': '', 'subject': '', 'total_pages': 13, 'author': 'sky', 'trapped': '/False', 'title': ''}, page_content='……,深')]
4.创建chatbot
4.1检索工具化
使用langchain库中的create_retriever_tool方法,把向量库检索器工具化,用于绑定到大模型中,具体代码如下:
from langchain_classic.tools.retriever import create_retriever_tool
retriever = vectordb.as_retriever()
retriever_tool = create_retriever_tool(
retriever,
"retrieve_relevent_information",
"retrieve relevent information about beijing annual report.",
)
测试工具:
retriever_tool.invoke({"query":"关于就业相关数据"})
4.2绑定工具
使用deepseek-chat大模型,并绑定检索工具。
"""
最早选用的是deepseek-chat,但后面调用时发现如果绑定了检索工具,那么对于检索主体之外的问题,则不能回答,比如:我让它写一个关于中国足球的段子,它的回答内容如下:
================================== Ai Message
我主要专注于北京年度报告相关的信息查询,目前无法为您创作关于中国足球的段子。我的功能范围比较有限,主要是帮助您检索北京年度报告中的具体信息。
如果您需要了解北京年度报告中的相关内容,我很乐意为您提供帮助。或者您可以尝试其他更适合创作娱乐内容的工具来编写足球段子。
====================================================================
所以只能改用qwen-plus。
"""
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model = 'deepseek-chat',
api_key = "sk-*",
base_url = "https://api.deepseek.com",
)model = llm .bind_tools(tools=[retriever_tool,])
4.3创建chatbot
创建一个chatbot节点,该节点将用于后面的图中,具体代码如下:
from langgraph.graph import MessagesState
def chatbot(state: MessagesState)->dict:
#根据当前的状态确定是检索工具,还是直接作答
response = model.invoke(state["messages"])
return {"messages": [response]}
随意问一个问题,比如让它写一个关于中国足球的段子:
input = {"messages": [{"role": "user", "content": "写一个关于中国足球的段子"}]}
chatbot(input)["messages"][-1].pretty_print()
chatbot的应答内容如下:
================================== Ai Message ==================================
中国足球就像是一个勤奋的学生,每次考试都充满期待地走进考场,结果出来后却发现,不仅没及格,连试卷都拿反了。教练说:“别灰心,我们明年继续努力!”于是球迷们又开始熬夜看比赛,结果发现——这次连球门都找不到了!守门员和前锋互相问:“咱们是攻还是守?”最后裁判叹了口气:“要不……咱们踢毽子吧,至少咱擅长。”
再问一个关于政府工作报告的问题:
input = {"messages": [{"role": "user", "content": "北京市政府工作报告中关于改善民生有哪些举措?"}]}
chatbot(input)["messages"][-1].pretty_print()
可以看到,function calling的相关信息:
================================== Ai Message ==================================
Tool Calls:
retrieve_relevent_information (call_42dca5834a714fd688182f)
Call ID: call_42dca5834a714fd688182f
Args:
query: 北京市政府工作报告 民生 改善举措
5.相关性评价
以下方法使用大模型对从向量库中检索的内容和用户的问题进行相关性判断,相关返回Y,不相关返回N。根据判断结果,返回对应的节点名。该方法用于作为图中条件。
from langchain_core.prompts import ChatPromptTemplate
from typing import Literal
from langchain_core.output_parsers import StrOutputParser
def discrininate_documents(
state: MessagesState,
) -> Literal["generate_answer", "rewrite_question"]:
DISCRIMINATE_PROMPT = (
"你是一个判别器,针对检索出的文档与用户问题的相关性进行判断. \n "
"以下是检索出的文档: \n\n {context} \n\n"
"以下是用户问题: {question} \n"
"如果文档内容与用户问题语义上相关,则标识为相关,否则为无关. \n"
"相关时返回Y,否则返回N."
)question = state["messages"][0].content #用户的问题
context = state["messages"][-1].content #检索结果
prompt = ChatPromptTemplate.from_messages(
[
("user", DISCRIMINATE_PROMPT)
]
)
model = prompt|llm|StrOutputParser()
response = model.invoke({"question" : question, "context" : context})
if response == "Y":
return "generate_answer"
else:
return "rewrite_question"
首先以相关数据进行测试,问题是“改进民生举措”:
from langchain_core.messages import convert_to_messages
input = {
"messages": convert_to_messages(
[
{
"role": "user",
"content": "改善民生举措",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "1",
"name": "retrieve_relevent_information",
"args": {"query": "改善民生举措"},
}
],
},
{"role": "tool", "content": "……住宅物业服务覆盖率达\n到 97%。", "tool_call_id": "1"},
]
)
}
discrininate_documents(input)
然后,以不相关内容进行测试:
from langchain_core.messages import convert_to_messages
input = {
"messages": convert_to_messages(
[
{
"role": "user",
"content": "改善民生举措",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "1",
"name": "retrieve_blog_posts",
"args": {"query": "改善民生举措"},
}
],
},
{"role": "tool", "content": "中国足球就像是一个勤奋的学生,每次考试都充满期待地走进考场,结果出来后却发现,不仅没及格,连试卷都拿反了。教练说:“别灰心,我们明年继续努力!”于是球迷们又开始熬夜看比赛,结果发现——这次连球门都找不到了!守门员和前锋互相问:“咱们是攻还是守?”最后裁判叹了口气:“要不……咱们踢毽子吧,至少咱擅长", "tool_call_id": "1"},
]
)
}
discrininate_documents(input)
6.问题改写
有些情况下,虽然向量库中有所需要的素材,但因为提问的语句有问题,所以未检索到相关的内容,此时需要对问题进行改写,使问题更加的明确和具体。
REWRITE_PROMPT = (
"检查用户输入问题并推测用于的真实意图和想法.\n"
"用户初始问题如下----:"
"\n ------- \n"
"用户初始问题如下----{question}"
"\n ------- \n"
"根据用户的真实意图对问题进行改写并输出改写后的问题"
"注意,仅需要输出改写后的问题"
)
def rewrite_question(state: MessagesState):
"""Rewrite the original user question."""
messages = state["messages"]
question = messages[0].content
prompt = REWRITE_PROMPT.format(question=question)
model = llm|StrOutputParser()
response = model.invoke([{"role": "user", "content": prompt}])
return {"messages": [{"role": "user", "content": response}]}
测试一下:
input = {
"messages": convert_to_messages(
[
{
"role": "user",
"content": "改善民生",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "1",
"name": "retrieve_relevent_information",
"args": {"query": "改善民生"},
}
],
},
{"role": "tool", "content": "meow", "tool_call_id": "1"},
]
)
}response = rewrite_question(input)
print(response["messages"][-1]["content"])
7.解答问题
此处解答问题是基于用户问题和检索出的上下文给出的解答:
GENERATE_PROMPT = (
"你的任务是回答用户的提问. "
"回答问题时需要参考{context}中的内容. "
"以下是用户问题"
"Question: {question}. "
"如果不知道如何作答,请诚实回答 '我不知道'. "
"保持答案简洁,不要超过3句.\n"
)
def generate_answer(state: MessagesState):
"""Generate an answer."""
question = state["messages"][0].content
context = state["messages"][-1].content
prompt = GENERATE_PROMPT.format(question=question, context=context)
response = llm.invoke([{"role": "user", "content": prompt}])
return {"messages": [response]}
测试一下:
input = {
"messages": convert_to_messages(
[
{
"role": "user",
"content": "改善民生有哪些举措?",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "1",
"name": "etrieve_relevent_information",
"args": {"query": "改善民生有哪些举措"},
}
],
},
{
"role": "tool",
"content": "持……。持续打好蓝天保卫战",
"tool_call_id": "1",
},
]
)
}response = generate_answer(input)
response["messages"][-1].pretty_print()
8.创建图
基于以上的成果组件创建图,具体代码如下:
from langgraph.graph import StateGraph, START, END
from langgraph.prebuilt import ToolNode
from langgraph.prebuilt import tools_condition
graph = (
StateGraph(MessagesState)
.add_node(chatbot)
.add_node("retrieve", ToolNode([retriever_tool]))
.add_node(rewrite_question)
.add_node(generate_answer)
.add_edge(START, "chatbot")
.add_conditional_edges("chatbot", tools_condition,
{
"tools": "retrieve",
END: END,
}
)
.add_conditional_edges("retrieve", discriminate_documents)
.add_edge("generate_answer", END)
.add_edge("rewrite_question", "chatbot")
.compile()
)
可视化工作流,检查图的正确性:
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
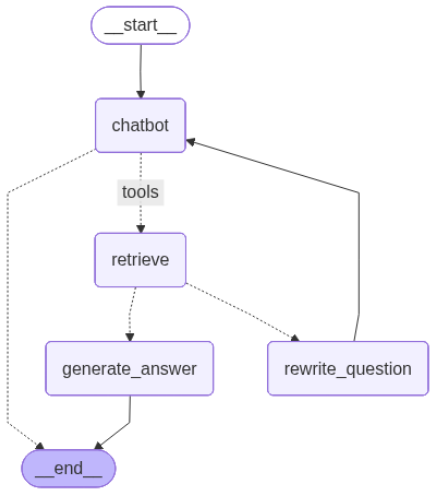
调用图:
for chunk in graph.stream(
{
"messages": [
{
"role": "user",
"content": "工作报告中有哪些改进民生的举措?",
}
]
}
):
for node, update in chunk.items():
print("Update from node", node)
update["messages"][-1].pretty_print()
print("\n\n")
输出结果如下:
Update from node chatbot
================================== Ai Message ==================================
Tool Calls:
retrieve_relevent_information (call_a527c420e54d47a597b63e)
Call ID: call_a527c420e54d47a597b63e
Args:
query: 工作报告 改进民生 举措Update from node retrieve
================================= Tool Message =================================
Name: retrieve_relevent_information…………
Update from node generate_answer
================================== Ai Message ==================================……,助力改善民生。

















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









