





要学好一种语言,磨耳朵是非常必要的,只有长期让相同的声音不停刺激大脑,才能将语言听的懂,说的地道。
做一款好的听力产品,最重要的是找到高质量且具有性价比的语料库。Speechling作为专注于口语的非盈利平台,拥有丰富专业的资料可供学习和下载。
本文通过python自动化脚本,结合speechling的语料库,实现了英语、西班牙语、法语、日语、韩语、意大利语、葡萄牙语、德语和俄语等多语种沉浸式听力。通过电脑扬声器,播放设置语言的男声女声及其对应的汉语,且将对应的文字进行屏幕显示,效果如下:
首先,分析音频主页,获取支持的语种。如下图所示:
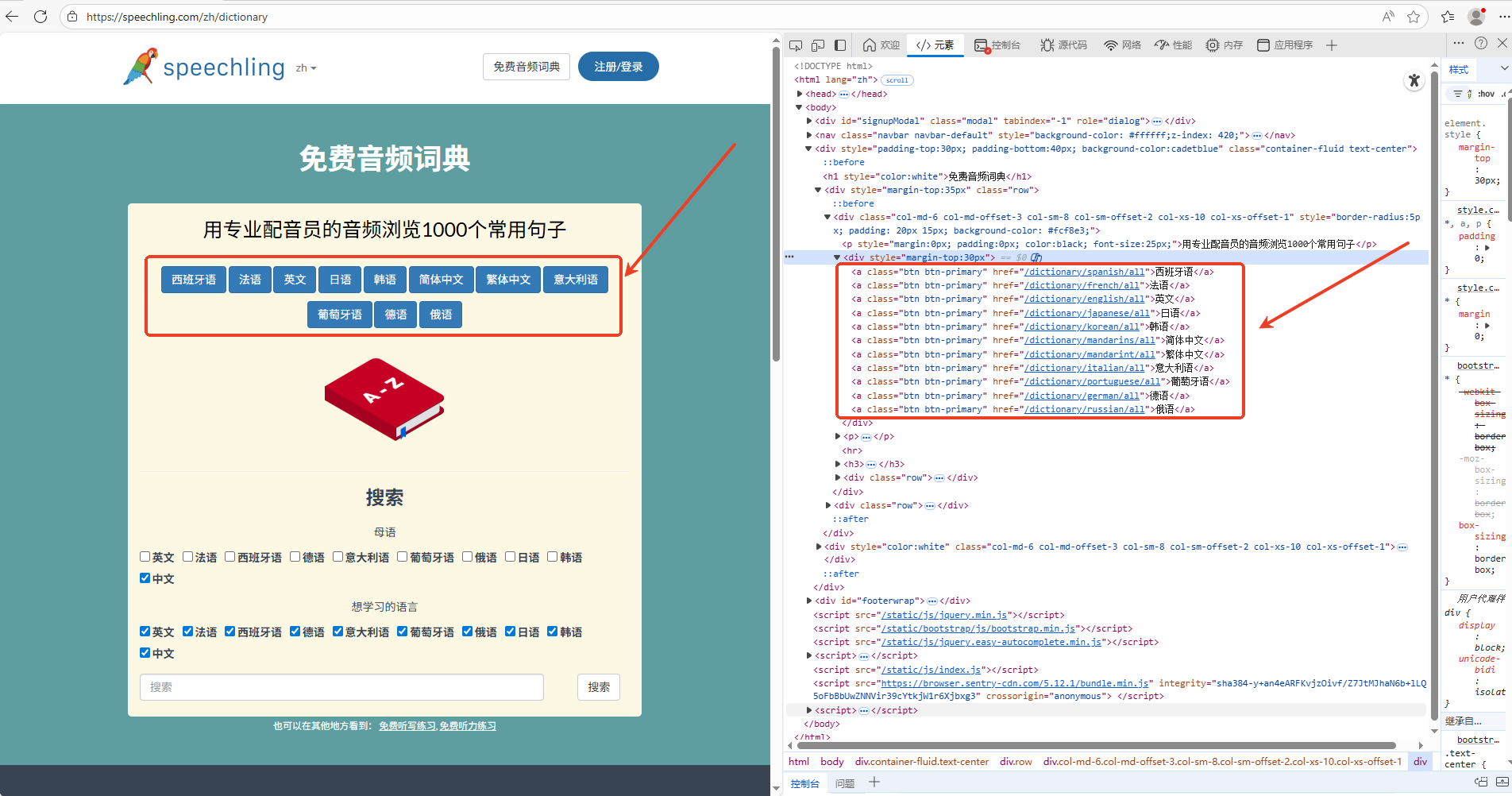
配置文件如下:
# 默认支持语言
#英语-english
#西班牙语-spanish
#法语-french
#日语-japanese
#韩语-korean
#意大利语-italian
#葡萄牙语-portuguese
#德语-german
#俄语-russian
[global]
lag = japanese
其次,分析类别页,获取所有的类别。如下图所示:
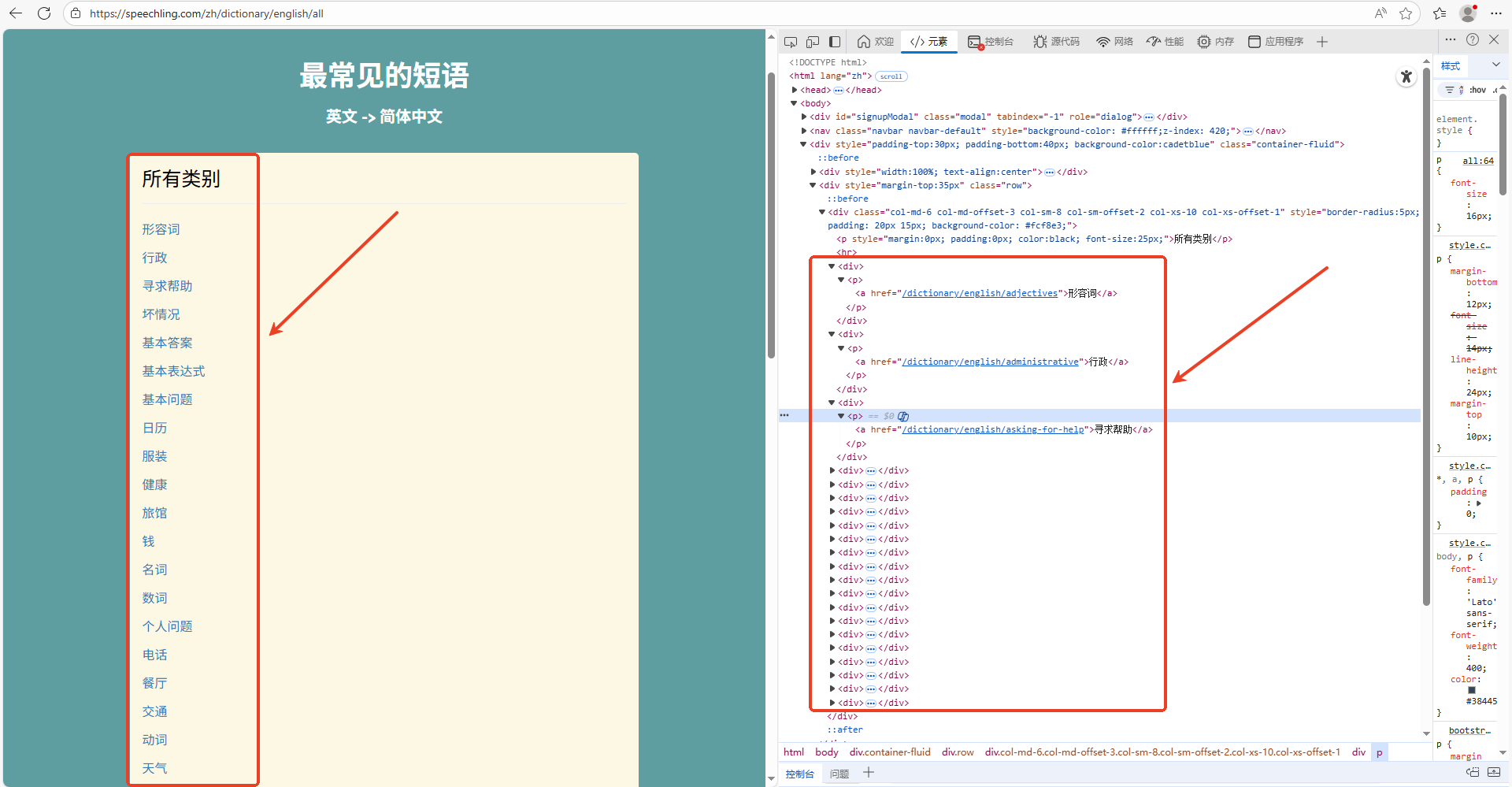
获取类别的python代码:
def get_classes_url(url):
items = {}
response = requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
all_classes = soup.find('div', class_='container-fluid')
# 使用lambda函数动态查找具有特定href的a标签
links = all_classes.find_all('a', href=lambda href: href and 'dictionary' in href)
for link in links:
items[link.text]=link['href']
return items
再次,分析某一类目的所有条目页,获取条目名称和对应超链接。如下图所示:
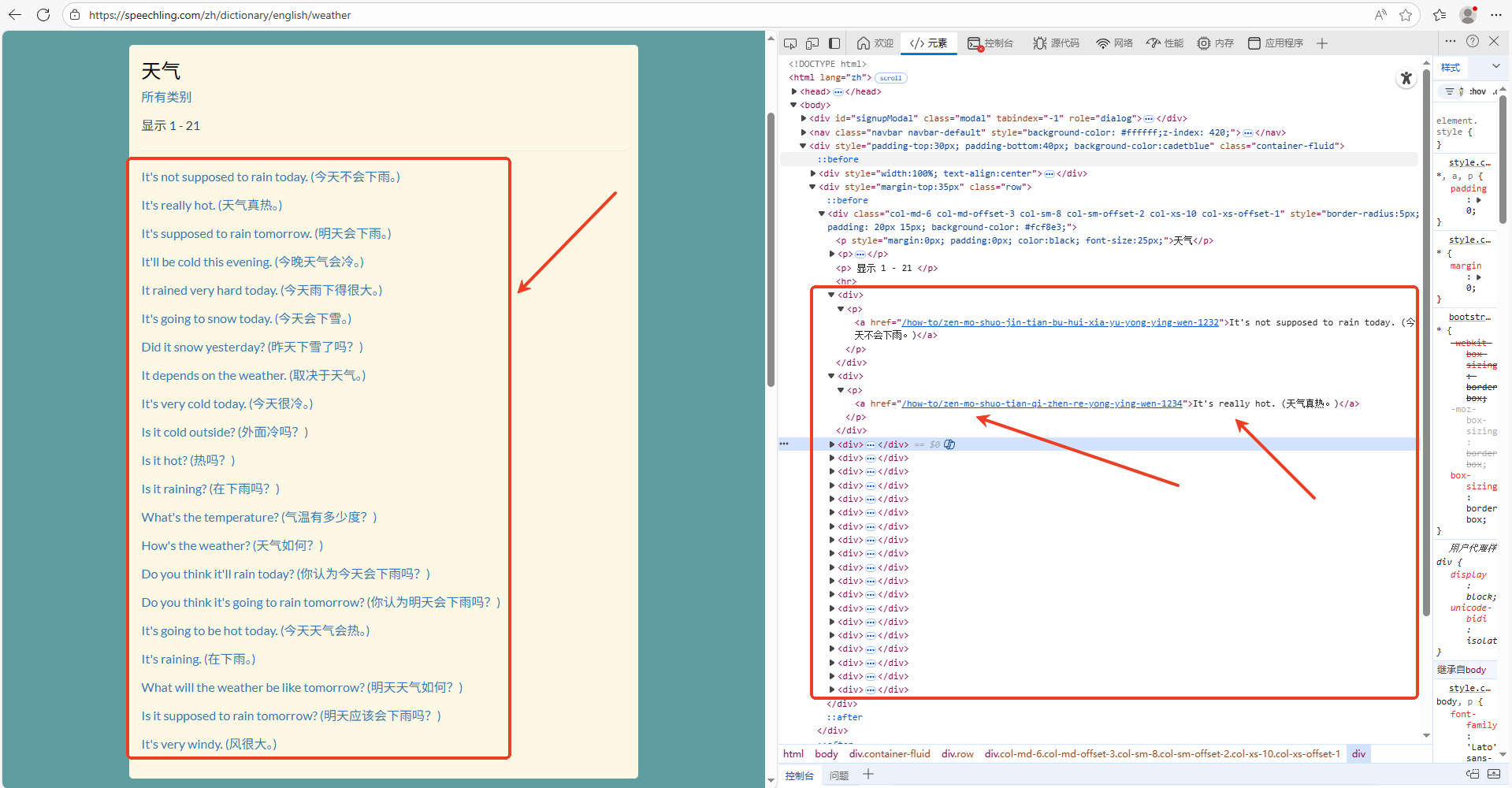
获取条目的python代码:
def get_items_url(url):
response = requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
items = {}
# 使用lambda函数动态查找具有特定href的a标签
links = soup.find_all('a', href=lambda href: href and 'how-to' in href)
for link in links:
items[link['href'][-4:]]=link.text
return items
最后,分析具体的条目页,获取对应的音频链接。如下图所示:
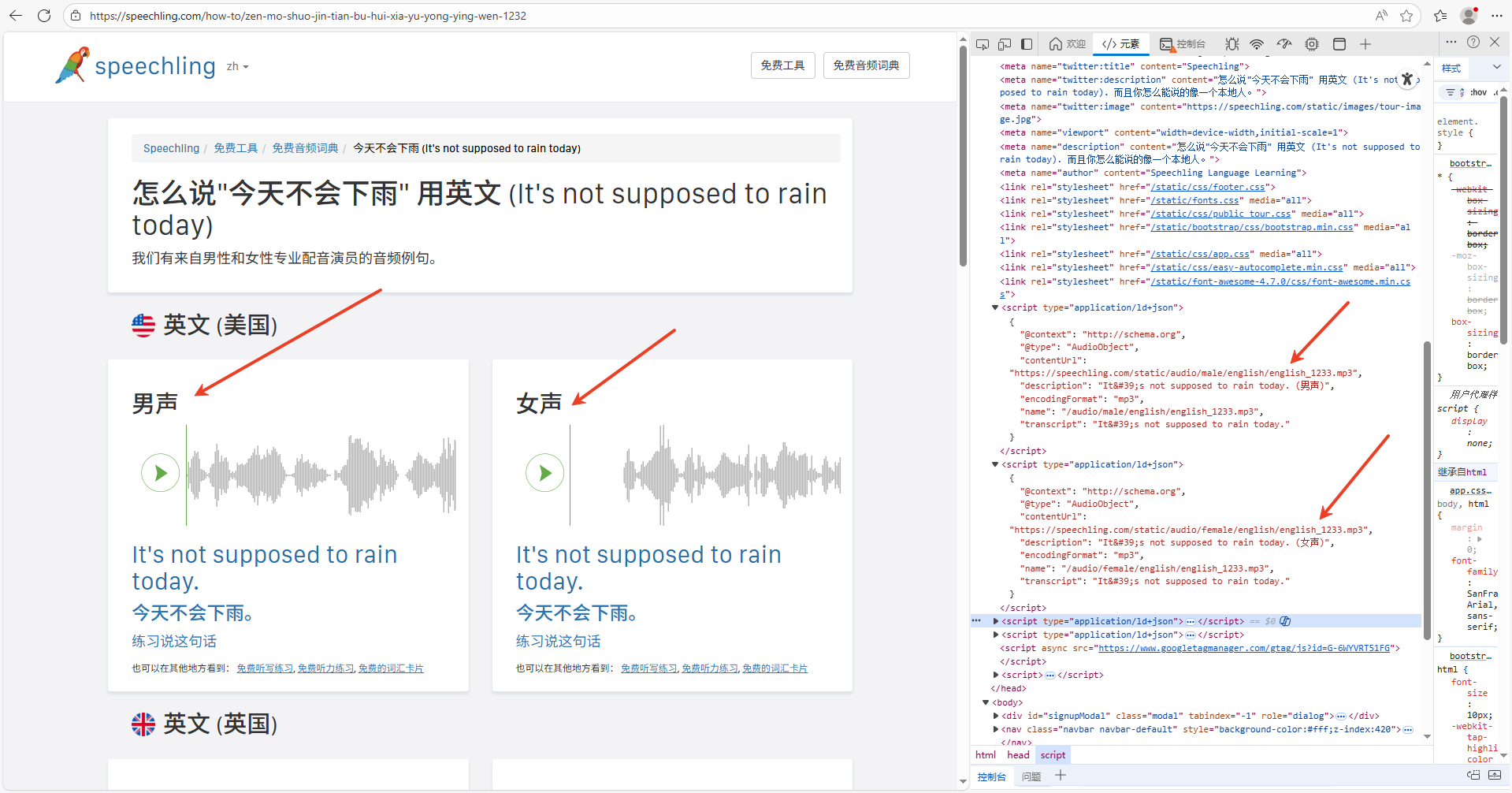
播放mp3对应的URL的python代码:
def play_mp3_url(url):
#print(url)
response = requests.get(url)
mp3_data = io.BytesIO(response.content)
pygame.mixer.init()
pygame.mixer.music.load(mp3_data)
pygame.mixer.music.play()
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10)
完整代码如下:
import requests
import io
import pygame
from bs4 import BeautifulSoup
import configparser
def play_mp3_url(url):
#print(url)
response = requests.get(url)
mp3_data = io.BytesIO(response.content)
pygame.mixer.init()
pygame.mixer.music.load(mp3_data)
pygame.mixer.music.play()
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10)
def get_items_url(url):
response = requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
items = {}
# 使用lambda函数动态查找具有特定href的a标签
links = soup.find_all('a', href=lambda href: href and 'how-to' in href)
for link in links:
items[link['href'][-4:]]=link.text
return items
def get_classes_url(url):
items = {}
response = requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
all_classes = soup.find('div', class_='container-fluid')
# 使用lambda函数动态查找具有特定href的a标签
links = all_classes.find_all('a', href=lambda href: href and 'dictionary' in href)
for link in links:
items[link.text]=link['href']
return items
#英语:english
#俄语:russian
config = configparser.ConfigParser()
config.read('./config.ini')
lag=config['global']['lag']
#列表
url = 'https://speechling.com/zh/dictionary/'+lag+'/all'
class_items = get_classes_url(url)
for class_name, class_url in class_items.items():
print(class_name)
items = get_items_url('https://speechling.com/zh'+class_url)
for num, text in items.items():
new_num = int(num) + 1
#需要做url变换
play_mp3_url("https://speechling.com/static/audio/female/"+lag+"/"+lag+"_" + str(new_num) + ".mp3")
play_mp3_url("https://speechling.com/static/audio/male/"+lag+"/"+lag+"_" + str(new_num) + ".mp3")
play_mp3_url("https://speechling.com/static/audio/female/mandarins/mandarins_" + str(new_num) + ".mp3")
# play_mp3_url("https://speechling.com/static/audio/male/mandarins/mandarins_" + num + ".mp3")
print(text)

















 1369
1369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









