




1 shell操作
shell可以维护和管理HBase
1.1 需求
订单数据保存到Hbase
id | 状态 | 金额 | 支付方式 | 用户id | 操作时间 | 商品分类 |
ID | STATUS | PAY_MONEY | PAYWAY | USER_ID | OPERATION_DATE | CATEGORY |
000001 | 已付款 | 200 | 1 | 001 | 2023-03-2 23:33:05 | 手机 |
使用shell操作以下步骤
1 、创建表
2、添加数据
3、更新数据
4、删除数据
5、查询数据
1.2创建表
启动Hbase shell的shell实际时JRuby的IRB,在其中添加了一些HBase命令
启动shell
hbase shell
创建表语法:
create "表名","列簇"
创建订单表,表明ORDER_INFO
create "ORDER_INFO","C1"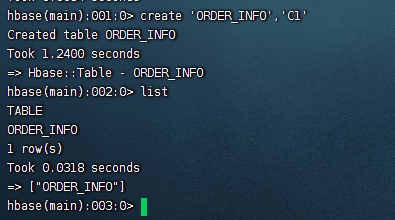
注意
create要小写
一个表可以包含若干个列簇
命令解析:调用hbase提供的ruby脚本的create方法,传递两个字符串参数
每个命令都是一个ruby脚本 https://gitee.com/apache/hbase/tree/branch-2.1/hbase-shell/src/main/ruby/shell/commands
1.3 查看表
hbase(main):002:0> list
TABLE
ORDER_INFO
1 row(s)
Took 0.0318 seconds
=> ["ORDER_INFO"]1.4删除表
要删除一个表,首先需要禁用表
禁用表
语法:disable '表名'
disable 'ORDER_INFO'然后删除表
语法: drop '表名'
drop 'ORDER_INFO'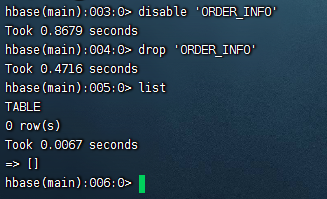
1.5添加数据
put操作,用来将数据保存到表中,一次只能保存一个列,有点类似map的put
put的语法:put '表名','ROWKEY','列蔟名:列名','值'
往表中添加一条数据
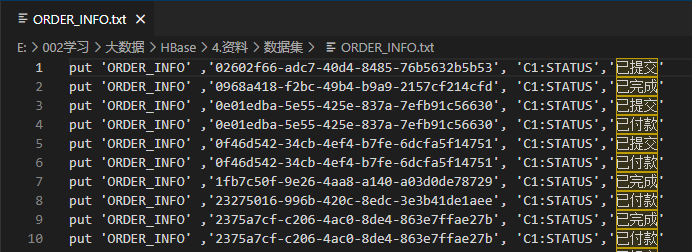
put "ORDER_INFO",'000001','C1:STATUS','已提交'
put "ORDER_INFO",'000001','C1:PAY_MONEY',4070
put "ORDER_INFO",'000001','C1:PAYWAY',1
put "ORDER_INFO",'000001','C1:USER_ID','4944191'
put "ORDER_INFO",'000001','C1:OPERATION_DATE','2023-03-04 00:10:10'
put "ORDER_INFO",'000001','C1:CATEGORY','手机'1.6 查看添加的数据
按照rowkey,查找对应的数据000001
get命令,用来获取单独一行的数据,语法:get '表名','rowkey'
get 'ORDER_INFO','000001'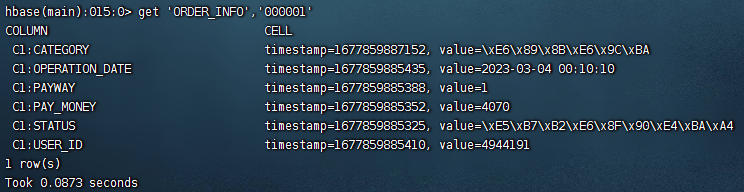
显示中文,shell中的中文时以十六进制编码格式显示中文,我们需要在get命令后面添加一个属性{FORMATTER=>'toString'}
get 'ORDER_INFO','000001',{FORMATTER=>'toString'}{ key => value},这个是Ruby语法,表示定义一个HASH结构
get是一个HBase Ruby方法,’ORDER_INFO’、’000001’、{FORMATTER => 'toString'}是get方法的三个参数
FORMATTER要使用大写
在Ruby中用{}表示一个字典,类似于hashtable,FORMATTER表示key、’toString’表示值
1.7 更新
将订单000001,更改为已付款
使用put命令,语法跟之前添加数据一样,可以理解为map中添加同样键值的数据的覆盖
put 'ORDER_INFO','000001','C1:STATUS','已付款'注意观察时间戳
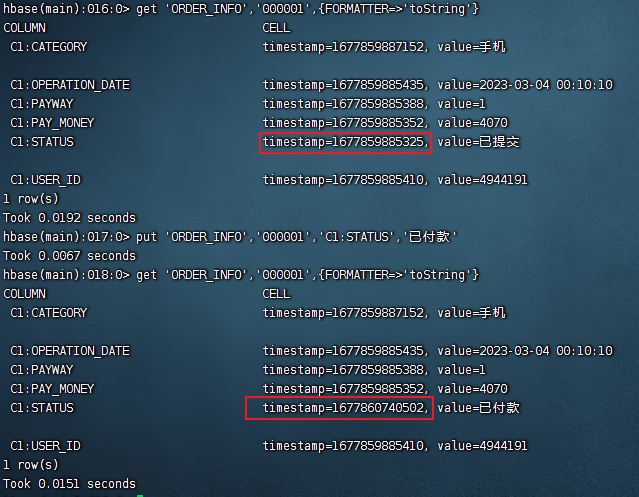
1.8 删除
可以删除指定列(单元格),也可以删除指定行
将订单000001的状态删除,delete命令,语法格式:delete:'表名','rowkey','列簇:列'
delete 'ORDER_INFO','000001','C1:STATUS'注意:此处HBase默认会保存多个时间戳的版本数据,所以这里的delete删除的是最新版本的列数据。
删除整行数据,删除订单000001的全部信息,deleteall命令,语法:deleteall '表名','rowkey'
deleteall 'ORDER_INFO','000001'删除所有版本数据
1.9 导入数据集
上传数据集到指定目录
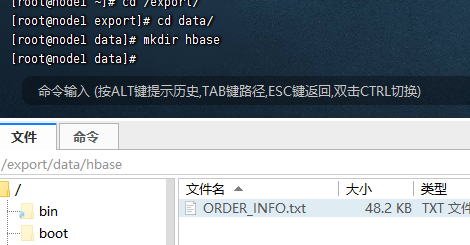
数据集
执行,在操作系统命令行下执行
hbase shell /export/data/hbase/ORDER_INFO.txt1.10计数操作
count命令用来统计一个表里面有多少行数据,语法: count '表名'
count 'ORDER_INFO'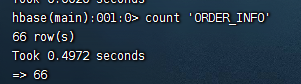
注意:这个操作比较耗时,需要慎用,因为会逐个regionserver扫描
1.11 大数据量计数
大量数据计数,Hbase提供了一个mapreduce程序进行计数,语法:$HBASE_HOME/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter '表名'
前提条件,启动YARN
# 启动YARN集群
start-yarn.sh
# 启动history server
mr-jobhistory-daemon.sh start historyserver计数操作
$HBASE_HOME/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'ORDER_INFO'1.12 扫描操作
查询ORDER_INFO所有数据
scan命令,语法,scan '表名'
scan 'ORDER_INFO',{FORMATTER=>'toString'}注意:避免扫描一张大表,数据量大的时候不要使用
要求:只显示三条
scan 'ORDER_INFO',{FORMATTER=>'toString',LIMIT=>3}要求,只查询订单状态和支付方式
scan 'ORDER_INFO',{FORMATTER=>'toString',COLUMNS=>['C1:STATUS','C1:PAYWAY'],LIMIT=>3}要求:查询指定订单id的数据
根据ROWKEY来查询对应的数据,ROWKEY为0968a418-f2bc-49b4-b9a9-2157cf214cf,只查询订单状态、支付方式,语法: scan '表名',{ROWPREFIXFILTER=>'rowkey'}
scan 'ORDER_INFO',{FORMATTER=>'toString',COLUMNS=>['C1:STATUS','C1:PAYWAY'],ROWPREFIXFILTER=>'0968a418-f2bc-49b4-b9a9-2157cf214cf'}注:其实是根据过滤器进行查询的
1.13过滤器(*)
海量数据查询,基本操作难以完成,需要借助FIlter来完成,Filter可以根据列簇,列,版本等条件进行过滤查询,因为在hbase中,主键、列、版本都是有序存储的,所以借助filter,可以高效的查询。
过滤器基于java编写,ruby提供了相应的操作函数
过滤器原生java API,http://hbase.apache.org/2.2/devapidocs/index.html
支持的过滤器如下
hbase(main):007:0> show_filters
# 允许用户指定一个参考列或引用列来过滤其他列的过滤器
DependentColumnFilter #
KeyOnlyFilter #
ColumnCountGetFilter
SingleColumnValueFilter
PrefixFilter
SingleColumnValueExcludeFilter
FirstKeyOnlyFilter
ColumnRangeFilter
ColumnValueFilter
TimestampsFilter
FamilyFilter
QualifierFilter
ColumnPrefixFilter
RowFilter
MultipleColumnPrefixFilter
InclusiveStopFilter
PageFilter
ValueFilter
ColumnPaginationFilter rowkey 过滤器 | RowFilter | 实现行键字符串的比较和过滤 |
PrefixFilter | rowkey前缀过滤器 | |
KeyOnlyFilter | 只对单元格的键进行过滤和显示,不显示值 | |
FirstKeyOnlyFilter | 只扫描显示相同键的第一个单元格,其键值对会显示出来 | |
InclusiveStopFilter | 替代 ENDROW 返回终止条件行 | |
列过滤器 | FamilyFilter | 列簇过滤器 |
QualifierFilter | 列标识过滤器,只显示对应列名的数据 | |
ColumnPrefixFilter | 对列名称的前缀进行过滤 | |
MultipleColumnPrefixFilter | 可以指定多个前缀对列名称过滤 | |
ColumnRangeFilter | 过滤列名称的范围 | |
值过滤器 | ValueFilter | 值过滤器,找到符合值条件的键值对 |
SingleColumnValueFilter | 在指定的列蔟和列中进行比较的值过滤器 | |
SingleColumnValueExcludeFilter | 排除匹配成功的值 | |
其他过滤器 | ColumnPaginationFilter | 对一行的所有列分页,只返回 [offset,offset+limit] 范围内的列 |
PageFilter | 对显示结果按行进行分页显示 | |
TimestampsFilter | 时间戳过滤,支持等值,可以设置多个时间戳 | |
ColumnCountGetFilter | 限制每个逻辑行返回键值对的个数,在 get 方法中使用 | |
DependentColumnFilter | 允许用户指定一个参考列或引用列来过滤其他列的过滤器 |
语法: scan '表名',{FILTER=>"过滤器(比较运算符,'比较器表达式')"}
比较运算符:=等于,>大于,>=大于等于,<小于,<=小于等于,!=不等于
比较器:BinaryComparator匹配完整字节数组,BinaryPrefixComparator匹配字节数组前缀BitComparator匹配比特位,NullComparator匹配空值,RegexStringComparator匹配正则表达式
SubstringComparator匹配子字符串
比较器表达式:比较器类型:比较器值。
BinaryComparator表达式为:binary:值,BinaryPrefixComparator表达式为:binaryprefix:值,BitComparator表达式为:bit:值,NullComparator表达式为null,RegexStringComparator 表达式为:regexstring:正则表达式,SubstringComparator表达式为:substring:值
示例
只查询订单的ID为:02602f66-adc7-40d4-8485-76b5632b5b53、订单状态以及支付方式
订单ID实际就是ROWKEY,应该使用rowkey的过滤器,通过hbase的api,找到rowkey的过滤器RowFilter
RowFilter
public RowFilter ( CompareOperator op, ByteArrayComparable rowComparator)
Constructor.
Parameters:
op - the compare op for row matching
rowComparator - the comparator for row matching
scan 'ORDER_INFO',{FILTER=>"RowFilter(=,'binary:e180a9f2-9f80-4b6d-99c8-452d6c037fc7')",COLUMN=>['C1:STATUS','C1:PAYWAY'],FORMATTER=>'toString'}
# 注意:rowComparator参数,即binary:e180a9f2-9f80-4b6d-99c8-452d6c037fc7中,:前后不能有空格
# = 其实是上面api中的CompareOperator查询状态为已付款的订单
要是用列的值的过滤器
SingleColumnValueFilter
public SingleColumnValueFilter (byte[] family, byte[] qualifier, CompareOperator op, byte[] value)
Constructor for binary compare of the value of a single column. If the column is found and the condition passes, all columns of the row will be emitted. If the condition fails, the row will not be emitted.
Use the filterIfColumnMissing flag to set whether the rest of the columns in a row will be emitted if the specified column to check is not found in the row.
Parameters:
family - name of column family
qualifier - name of column qualifier
op - operator
value - value to compare column values against
scan 'ORDER_INFO',{FILTER=>"SingleColumnValueFilter('C1','STATUS',=,'binary:已付款')",FORMATTER=>'toString'}
# 注意,=不能加引号查询支付方式为1,且金额大于3000的订单
一个过滤器不能实现,需要多个过滤器实现查询
scan 'ORDER_INFO',{FILTER=>"SingleColumnValueFilter('C1','PAYWAY',=,'binary:1') AND SingleColumnValueFilter('C1','PAY_MONEY',>,'binary:3000')", FORMATTER=>'toString'}
# 不要漏掉箭头,作者实践中漏掉了
HBase shell中比较默认都是字符串比较,所以如果是比较数值类型的,会出现不准确的情况
例如:在字符串比较中4000是比100000大的
1.14 INCR
某新闻APP应用为了统计每个新闻的每隔一段时间的访问次数,他们将这些数据保存在HBase中。
该表格数据如下所示:要求:原子性增加新闻的访问次数值。
新闻ID | 访问次数 | 时间段 | ROWKEY |
0000000001 | 12 | 00:00-01:00 | 0000000001_00:00-01:00 |
0000000002 | 12 | 01:00-02:00 | 0000000002_01:00-02:00 |
rowkey索引的命名,将提高查询的效率
incr操作:对某个单元格(列)进行原子性计数,语法:incr '表名','列簇':'列名',累加值(默认累加1)
如果某一列要累加,需要用incr创建
使用put创建的列,不能用incr
导入数据(数据样例)
incr 'NEWS_VISIT_CNT','0000000012_01:00-02:00','C1:CNT',1
incr 'NEWS_VISIT_CNT','0000000013_02:00-03:00','C1:CNT',23执行命令
hbase shell /export/data/NEWS_VISIT_CNT.txt 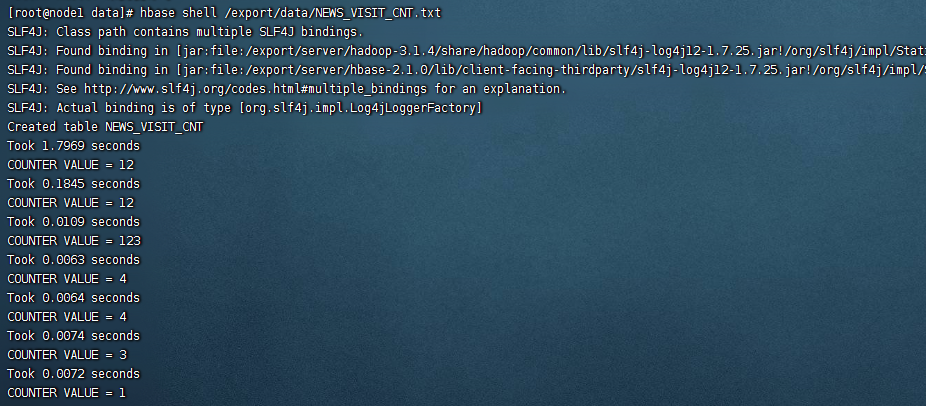
查看导入的数据
scan 'NEWS_VISIT_CNT',{LIMIT=>5,FORMATTER=>'toString'}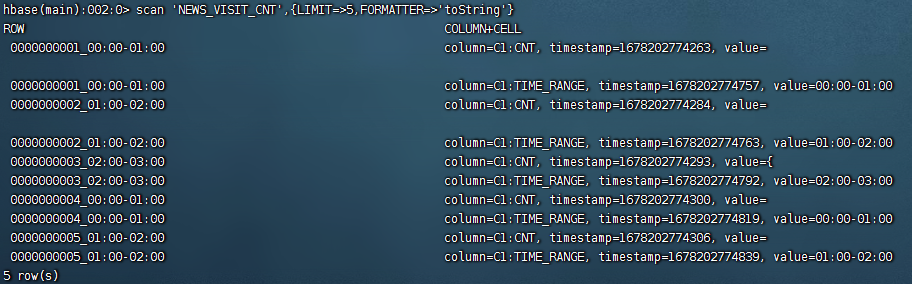
查询0000000020新闻01:00 - 02:00的访问次数
get_counter 'NEWS_VISIT_CNT','0000000020_01:00-02:00','C1:CNT'对这条新闻的这个访问时间加1
incr 'NEWS_VISIT_CNT','0000000020_01:00-02:00','C1:CNT'incr是原子的累加,incr创建的列才能累加,put创建的列不能累加
2 shell管理
2.1 status
显示服务器状态

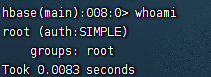
2.2 whoami
我是谁,显示当前用户
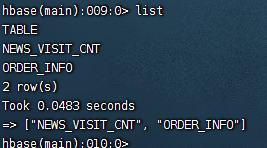
2.3list
显示所有表
2.4count
统计指定表的数据条数(慎用:非常耗时)
count 'ORDER_INFO'2.5describe
查看表的信息,也可以通过webUI查看
describe 'ORDER_INFO'
2.6exists
检查表是否存在
exists 'ORDER_INFO'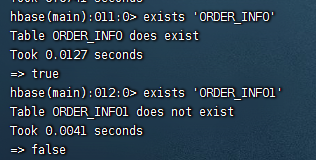
2.7is_enabled,isdisabled
检查表是否被禁用
is_enabled 'ORDER_INFO'
is_disables 'ORDER_INFO'
2.8alter
改变表和列簇的模式(慎用)
create 'USER_INFO','C1','C2'
#新增列簇
alter 'USER_INFO','C3'
#删除列簇
alter 'USER_INFO','delete'=>'C3'2.9disable/enable
禁用一张表,启用一张表(慎用)
disable 'USER_INFO'
enable 'USER_INFO'2.10drop
删除一张表(慎用)
drop 'USER_INFO'2.11 truncate
清空一张表(慎用)
truncate 'ORDER_INFO'


















 2931
2931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











