




 本文介绍如何使用Python制作一个爬虫,从豆瓣美女网站抓取图片。首先,通过PyCharm创建项目Demo,导入requests、beautifulsoup等库。接着,解析网页源代码,找到img标签的src属性,利用urllib下载图片。在遇到'No such file or directory'错误后,创建文件夹保存图片。最后,扩展爬虫功能,爬取多页图片。
本文介绍如何使用Python制作一个爬虫,从豆瓣美女网站抓取图片。首先,通过PyCharm创建项目Demo,导入requests、beautifulsoup等库。接着,解析网页源代码,找到img标签的src属性,利用urllib下载图片。在遇到'No such file or directory'错误后,创建文件夹保存图片。最后,扩展爬虫功能,爬取多页图片。
在开始制作爬虫前,我们应该做好前期准备工作,找到要爬的网站,然后查看它的源代码
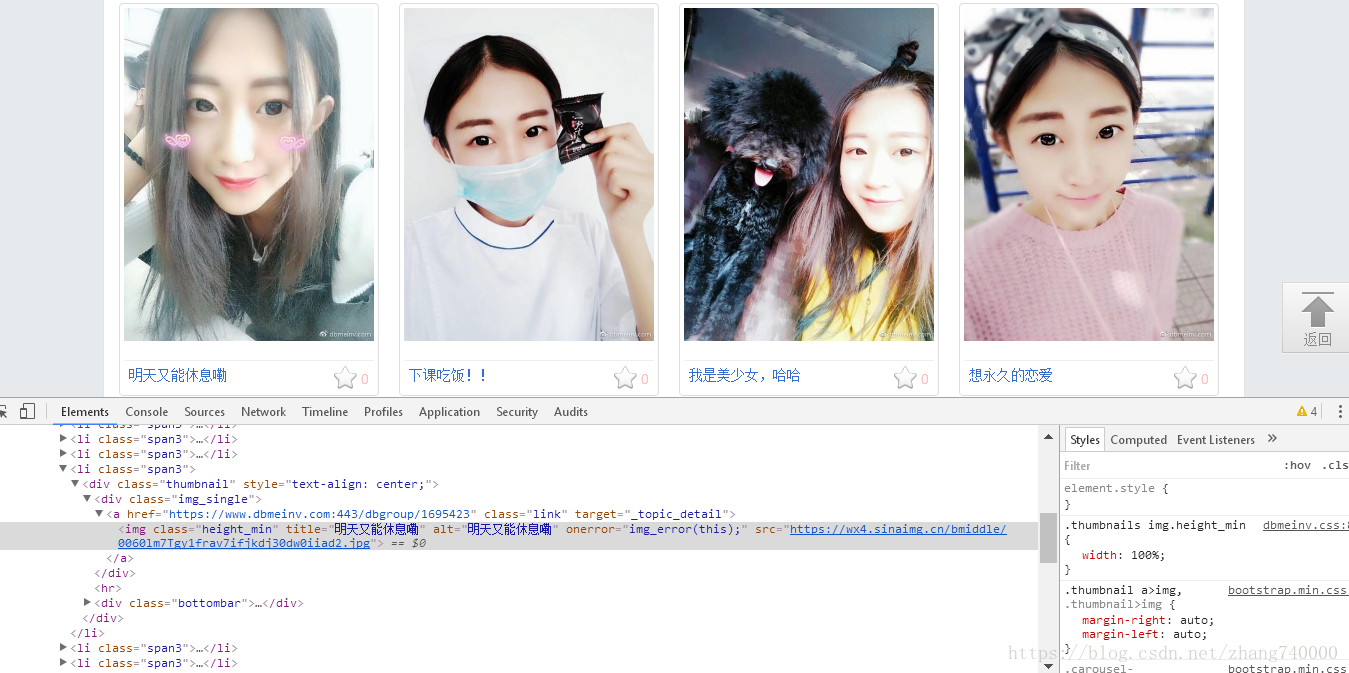
我们这次爬豆瓣美女网站,网址为:https://www.dbmeinv.com/
用到的工具:pycharm ,这是它的图标

打开后,进入它的界面
接下来就是创建一个项目,
我们给它命名为Demo,准备工作做好后,就可以撰写一只爬虫了
1,我们先把这次需要用到的三个包先给它导进去
在开始制作爬虫前,我们应该做好前期准备工作,找到要爬的网站,然后查看它的源代码
我们这次爬豆瓣美女网站,网址为:https://www.dbmeinv.com/
用到的工具:pycharm ,这是它的图标
打开后,进入它的界面
接下来就是创建一个项目,
我们给它命名为Demo,准备工作做好后,就可以撰写一只爬虫了
1,我们先把这次需要用到的三个包先给它导进去

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1989
1989





