






1.作业题目
Python原生代码实现KNN算法(鸢尾花数据集)
2.算法设计
步骤:
(1)利用KNN算法对鸢尾花数据进行分类(利用sklearn自带的iris数据集)
(2)将33%的数据作为测试集
(3)将数据传入预测函数中,得出结果
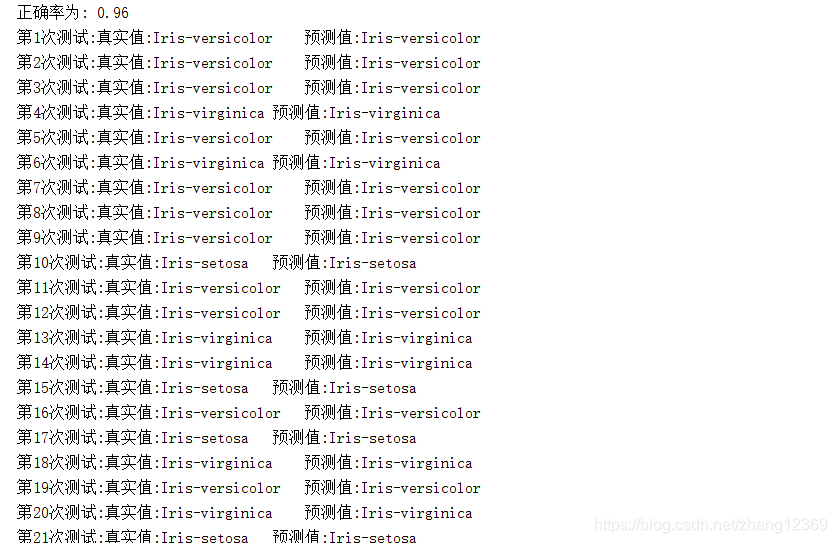
(4)将传入的数据与实际数据进行对比,得出正确率
(5)主函数整合
所有方法:
(1)获取鸢尾花数据:iris_data(self)
(2)将数据分割成测试集和训练集data(self)
(3)K值传入:__init__(self,k)
(4)训练函数:fit(self,x_train,y_train)
(5)预测函数:_predict(self,x_test)
(6)predict(self,X_predict)
(7)正确率函数:sorce(self,x_test,y_test)
3测试用例设计及调试过程截屏
部分重要代码:
def iris_data(self):
iris = load_iris()
iris_data = iris.data
iris_target = iris.target
return iris_data, iris_target
#加载数据,返回测试集,训练集
def data(self):
# 1.获取鸢尾花的特征值,目标值
iris_data, iris_target = self.iris_data()
# 2.将数据分割成训练集和测试集 test_size=0.33表示将33%的数据用作测试集
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.33)
return x_train,x_test,y_train,y_test
def _predict(self,x_test):
#欧氏距离
d = [np.sqrt(np.sum((x_i - x_test) ** 2)) for x_i in self.x_train]
#将欧氏距离递增排序
neard=np.argsort(d)
#选取最近的k个点
top_k=[self.y_train[i] for i in neard[:self.k]]
#判断k个点中,类别最多的那一类
#计数,将每个类出现的概率
votes=Counter(top_k)
return votes.most_common(1)[0][0] #显示前1个最多的元素
结果截屏:
调试过程截屏:
4总结
作业参考地址:https://blog.youkuaiyun.com/qq_41689620/article/details/82421323
https://blog.youkuaiyun.com/xzy53719/article/details/83149738
本次作业让我深刻的认识到自己的不足,在程序实现过程中,遇到了各种各样的问题,
首先自己没有找到numpy等包,所以在运行时会出现错误,
解决方式:将anaconda中的包导入;
其次在获取iris数据集时,很长时间找不到出错的位置,
解决方式:获取数据集需要使用一些包内自带的函数,但包及函数都需要对应查找;
最后,在程序中的一些调用会存在一些冲突,所以使得程序逻辑不太完整,
解决方式:程序部分运行测试
收获:进一步了解了KNN算法以及python语句的使用方式,实际对分析数据集有了一定了解及想法。

















 2030
2030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









