




一、InnoDB 物理存储结构
从 InnoDB 存储引擎的逻辑存储结构看,所有数据都被逻辑地存放在一个空间中,称之为表空间(tablespace)。表空间又由段(segment)、区(extent)、页(page)组成。页在一些文档中有时也称为块(block),InnoDB 存储引擎的逻辑存储结构如下图所示
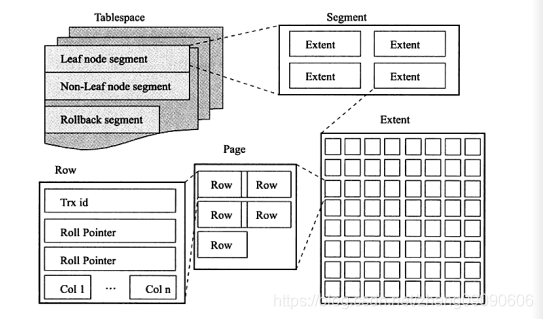
1. 表空间
MySQL 的表存储依赖于存储引擎,最常用的是 InnoDB。
- InnoDB 将数据存储在表空间中。
- 可以是:
- 系统表空间(共享)
- 独立表空间(
.ibd文件,每个表一个文件,推荐开启innodb_file_per_table=ON)
2.段 —— 逻辑上的数据集合
- 段是逻辑容器,对应表中的某种数据结构。
- InnoDB 中主要有两种段:
- 数据段(Data Segment):存放 B+树的叶子节点(即真实的数据行)
- 索引段(Index Segment):存放 B+树的非叶子节点(即索引节点)
其他类型的段:
- 回滚段(Rollback Segment):用于事务回滚和 MVCC
- 系统段、临时段等
3.区 —— 连续的页组
- 大小:1 个区 = 64 个连续的页 = 64 × 16KB = 1MB
- 目的:减少碎片,提高顺序读写效率。
- 当表的数据量较大时,InnoDB 会按“区”为单位申请空间,而不是一页一页地分配。
区的分配策略:
- 初始阶段:先使用碎片区(Fragmented extents),即零散使用的页。
- 超过一定阈值后(如超过 32 页),开始整区分配。
4.页—— 最小存储IO单位
- 大小:默认 16KB(可通过
innodb_page_size配置) - 磁盘 I/O 的基本单位是“块”,所以页是 InnoDB 磁盘与内存之间交互的最小单位。
- 常见的页类型包括:
- 数据页(B+Tree Node):存储索引和行数据(叶子节点存行,非叶子节点存键值)
- undo 日志页
- 系统页
- 事务系统页
- 插入缓冲位图页 等
5.行 —— 页的构成
行不能独立存在 —— 它依附于页
InnoDB 存储引擎是面向行的(row-oriented),也就说数据是按行进行存放的。每个页存放的行记录也是有硬性定义的,最多允许存放 16KB/2-200行的记录,即 7992行记录。
二、表的逻辑结构
1. 字段(列)
- 每个字段有:
- 名称(name)
- 数据类型(如 INT, VARCHAR, DATETIME)
- 是否允许为 NULL
- 默认值(DEFAULT)
- 约束(如主键、唯一、外键)
2. 记录(行)
- 每行是字段值的集合。
- 每行对应数据库中的一条数据。
3. 主键(Primary Key)
- 唯一标识一条记录。
- 不能为空(NOT NULL),且唯一。
- 通常使用
AUTO_INCREMENT自增。
4. 索引(Index)
- 提升查询效率的数据结构(通常是 B+树)。
- 主键自动创建聚簇索引(Clustered Index)。
- 可为其他列创建二级索引(Secondary Index)。
三、约束
| 约束类型 | 说明 |
|---|---|
PRIMARY KEY | 主键,唯一且非空 |
UNIQUE | 唯一约束,允许 NULL(但一个表中 NULL 只能出现一次) |
FOREIGN KEY | 外键,关联另一张表的主键,保证引用完整性 |
NOT NULL | 字段不允许为空 |
CHECK | 检查约束(MySQL 8.0+ 支持) |
DEFAULT | 默认值 |
四、视图
在 MySQL 数据库中,视图(View)是一个命名的虚表,它由一个 SQL 查询来定义,可以当做表使用。与持久表(permanent table)不同的是,视图中的数据没有实际的物理存储。
视图的作用
视图在数据库中发挥着重要的作用。MySQL 数据库从 5.0 版本开始支持视图,视图的主要用途之一是被用做一个抽象装置,特别是对于一些应用程序,程序本身不需要关心基表(base table)的结构,只需要按照视图定义来取数据或更新数据,因此,视图同时在一定程度上起到一个安全层的作用。
虽然视图是基于基表的一个虚拟表,但是用户可以对某些视图进行更新操作,其 本质就是通过视图的定义来更新基本表。一般称可以进行更新操作的视图为可更新视图(updatable view)。视图定义中的 WITH CHECK OPTION 就是针对于可更新的视图的,即更新的值是否需要检查,对于不满足视图定义条件的将会抛出一个异常
五、表的设计规范(开发经验角度)
-
命名规范
- 小写 + 下划线:
user_info,order_detail - 避免使用保留字。
- 小写 + 下划线:
-
主键设计
- 优先使用自增主键(
BIGINT AUTO_INCREMENT) - 避免使用 UUID 作为主键(导致索引分裂、性能下降)
- 优先使用自增主键(
-
字段设计
- 避免
TEXT、BLOB大字段频繁查询 - 使用合适的数据类型:如
TINYINT表状态,DATETIME而非VARCHAR存时间 - 尽量
NOT NULL,避免空值判断复杂
- 避免
-
索引设计
- 高频查询字段建立索引
- 联合索引注意最左前缀原则
- 避免过多索引(影响写性能)
-
分表分库
- 单表数据量超过 500万~1000万行考虑分表
- 使用
Sharding或中间件(如 MyCat、ShardingSphere)
- 不要太过纠结三大范式,根据业务情况适当的反范式设计可以增加性能

















 304
304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









