




 本文深入解析了Apache Flink的架构,包括JobClient、JobManager和TaskManager的角色与职责,阐述了其分布式处理流程及高可用性设计。
本文深入解析了Apache Flink的架构,包括JobClient、JobManager和TaskManager的角色与职责,阐述了其分布式处理流程及高可用性设计。
概述
本文介绍flink的总体架构,通过本文的学习可以对flink的架构有一个总体把握。
总体架构
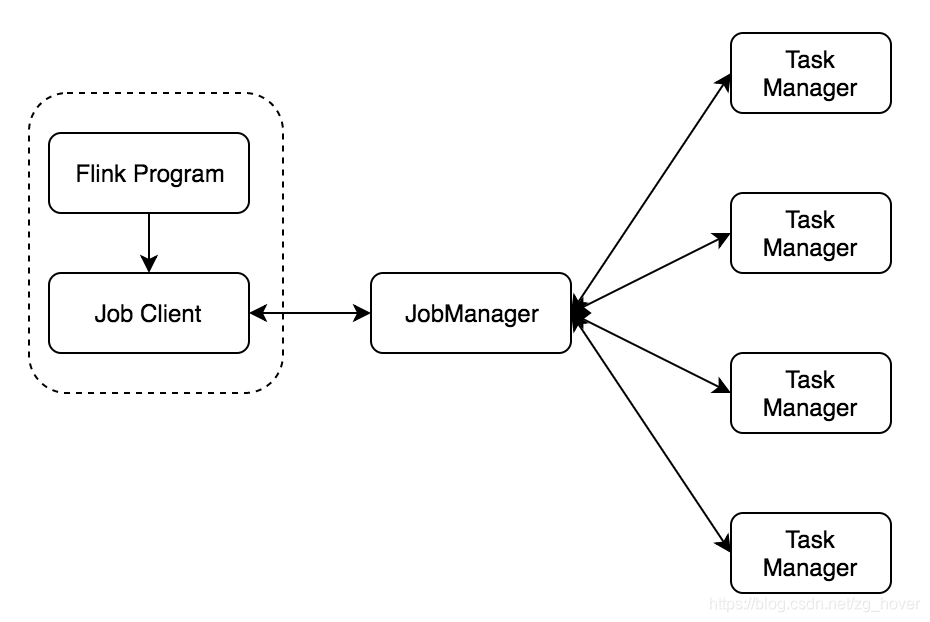
flink也是典型的master-slave分布式架构,如上图所示。
flink的架构总体来说分为以下几个部分:
- Job Client
- Job Manager
- Task Manager
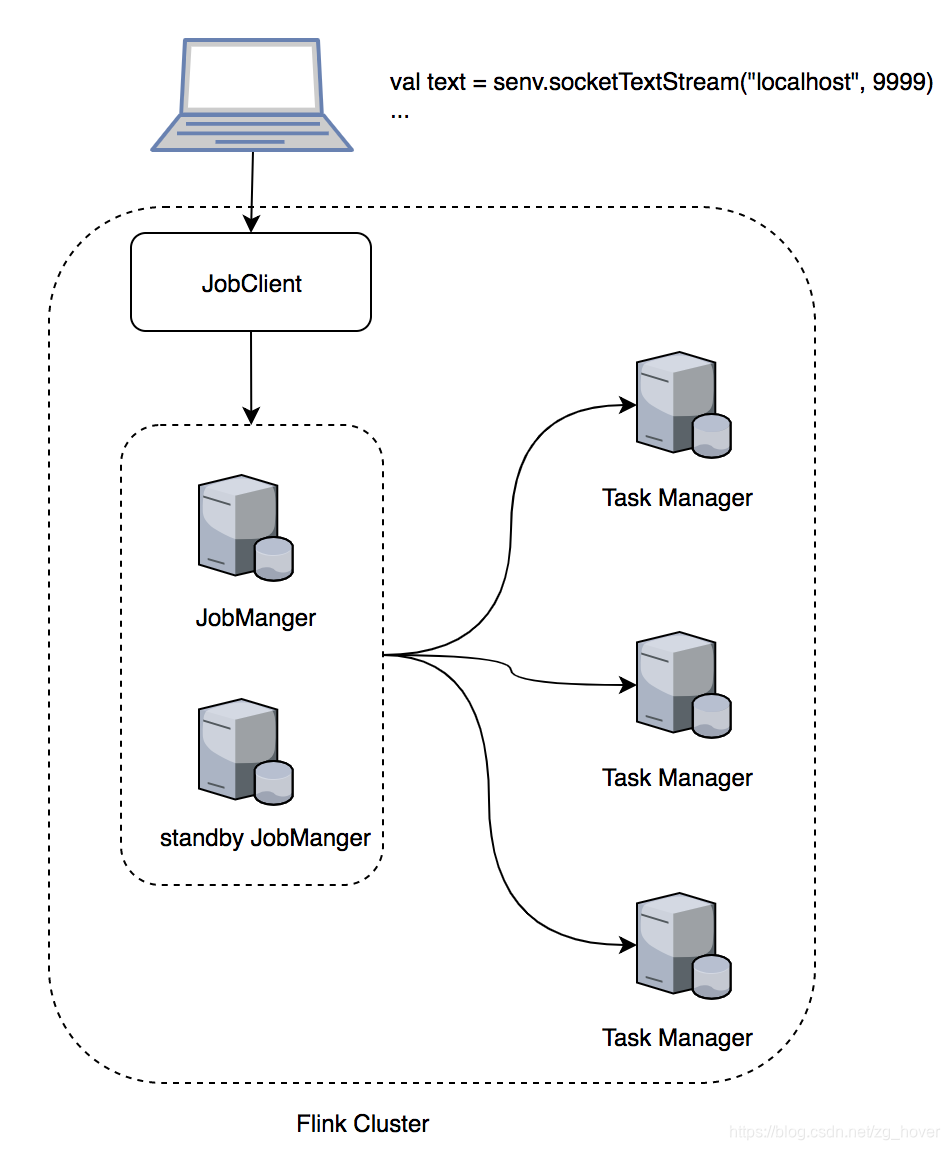
这几个部分可以部署在不同的机器上,如下图所示:
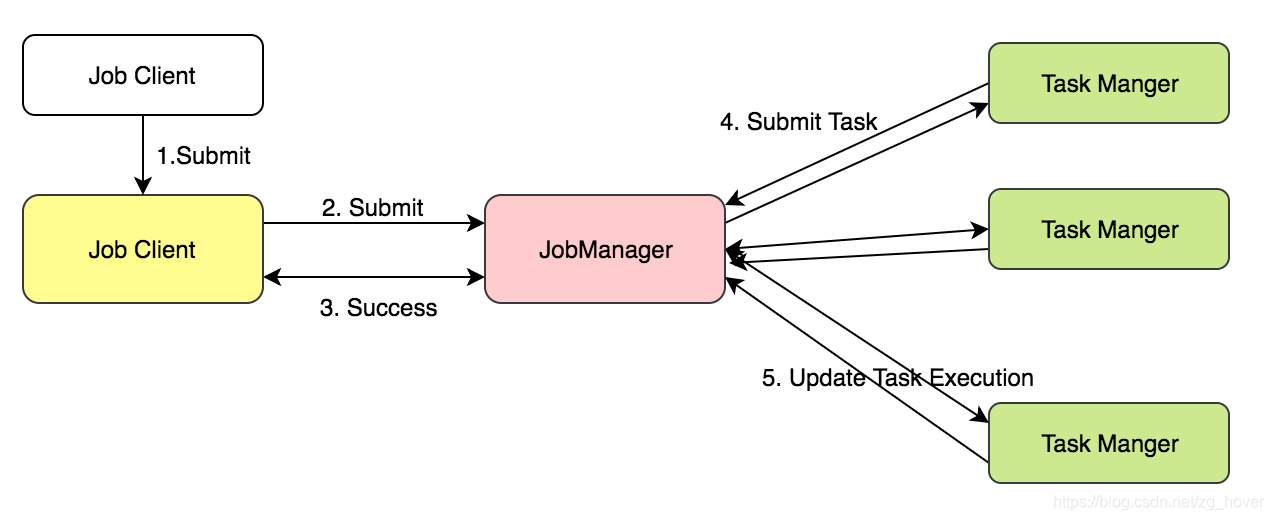
Flink的大致流程如下:用户编写的执行任务通过JobClient端发送到JobManager,由JobManager把任务发送到后端的TaskManager集群,并对执行过程进行管理,完成后由JobManager把结果发送给JobClient。
Flink的任务执行流程
Job Manager
作业管理器(JobManager)协调和管理程序的执行。 他们的主要职责包括:任务调度,检查点(checkpoints)管理,故障恢复等等。
可以有多个JobManager并行运行并分担这些功能。 这有助于实现高可用性,并通过负载均衡来提高性能。 其中一个JobManager会成为领导者(leader)。 如果领导节点发生故障,其他的其中一个JobManager节点(备用节点)将被选为leader节点。
Task Manager
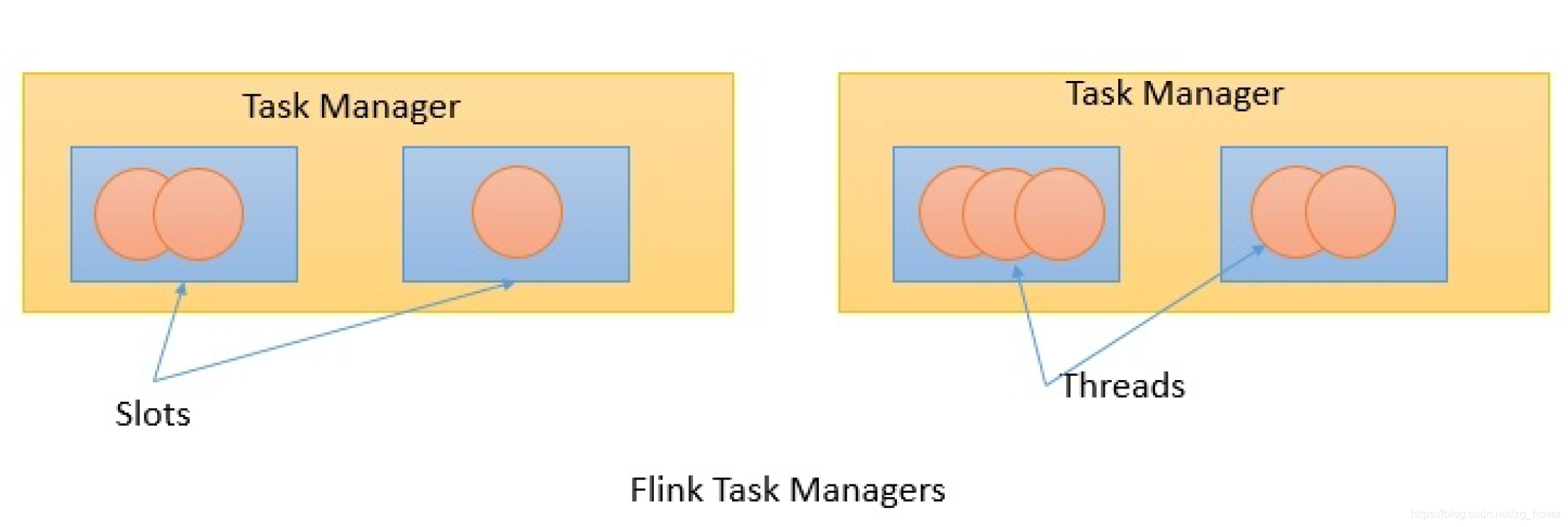
TaskManager(任务管理器)是工作节点,它在JVM中的一个或多个线程中执行任务。
任务执行的并行性由每个TaskManager上可用的任务槽(task slot)确定。
每个任务(Task)代表分配给任务槽的一组资源。 例如,如果任务管理器有四个插槽,那么它将为每个插槽分配25%的内存。
可以在任务槽中运行一个或多个线程。 同一插槽中的线程共享相同的JVM。 同一JVM中的任务共享TCP连接和心跳消息,如下图所示:
Job Client
作业客户端(Job Client)不是Flink程序执行的内部部分,但它是执行的起点。
作业客户端负责从用户接受程序,然后创建数据流(data flow),然后将数据流提交给作业管理器(JobManager)以进一步执行。
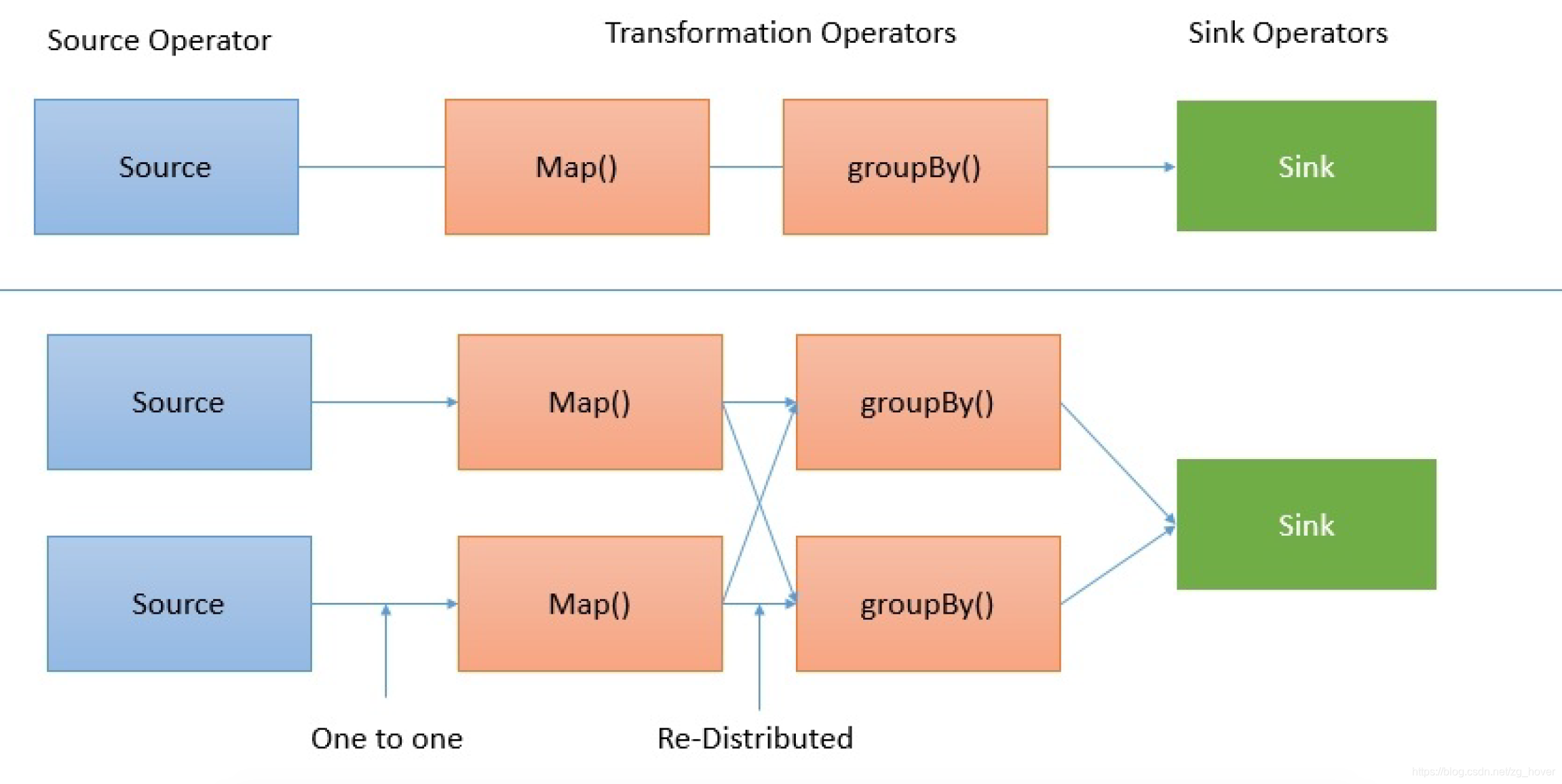
执行完成后,作业客户端将结果提交给用户。 一个数据流是一个执行计划。这里可以理解成pipeline,把多个执行算子组合而成的任务,形成一个dataflow,在这个dataflow中有些可以并行执行。如下图所示:
总结
本文介绍了flink的总体架构,从总体架构上来看,flink是典型的master-slave架构,但flink对master端进行了一些加强的设计,这样能够保证master的高可用性。
参考资料
- 《mastering apache flink》

















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









