



概念
让模型对重要信息重点关注并充分学习吸收的技术.通俗的讲就是把注意力集中放在重要的点上,而忽略其他不重要的因素。根据应用场景的不同,Attention分为空间注意力和时间注意力,前者用于图像处理,后者用于自然语言处理。
由来
最早用在seq2seq模型上,原始编解码模型的encode过程会生成一个中间向量C,用于保存原序列的语义信息。但是这个向量长度是固定的,当输入原序列的长度比较长时,向量C无法保存全部的语义信息,上下文语义信息受到了限制,这也限制了模型的理解能力。
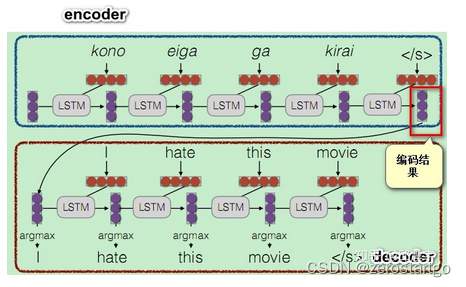
这种编码方法,无法体现对一个句子序列中不同语素的关注程度,在自然语言中,一个句子中的不同部分是有不同含义和重要性的,比如上面的例子中:I hate this movie.如果是做情感分析的应用场景,训练的时候明显应该对hate这个词语做更多的关注。
核心思想
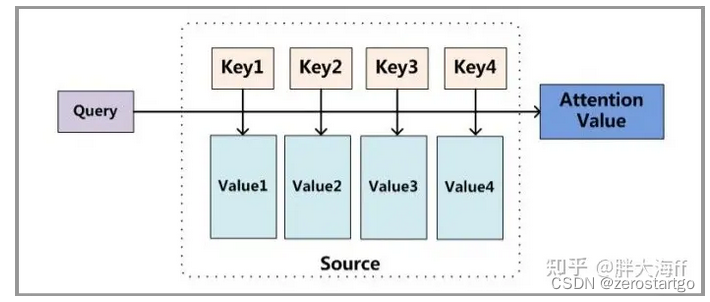
第一步: query 和 key 进行相似度计算,得到权值
第二步:将权值进行归一化,得到直接可用的权重
第三步:将权重和 value 进行加权求和
可以将Attention机制看作一种软寻址(Soft Addressing):Source可以看作存储器内存储的内容,元素由地址Key和值Value组成,当前有个Key=Query的查询,目的是取出存储器中对应的Value值,即Attention数值。通过Query和存储器内元素Key的地址进行相似性比较来寻址,之所以说是软寻址,指的不像一般寻址只从存储内容里面找出一条内容,而是可能从每个Key地址都会取出内容,取出内容的重要性根据Query和Key的相似性来决定,之后对Value进行加权求和,这样就可以取出最终的Value值,也即Attention值。因此Query是一个和任务相关的变量,而Key需要能够体现Value对应位置上的语义信息,目前在自然语言处理中,我们通常将目标作为 Query ,辅助信息作为 Key 和 Value。

















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









