spark报错总结+我的解决方法
最新推荐文章于 2025-05-14 08:30:21 发布







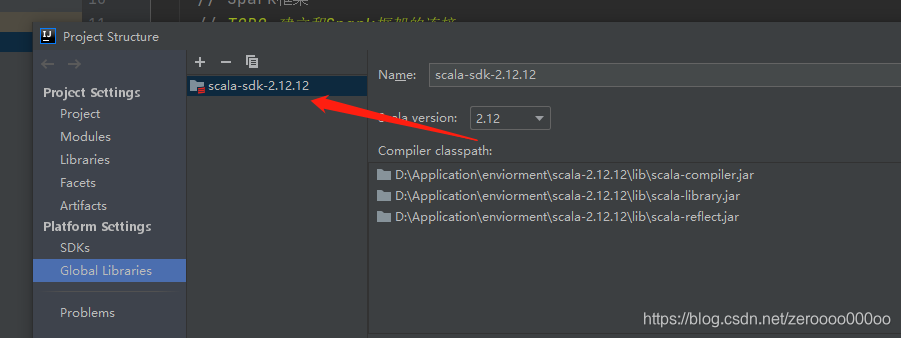
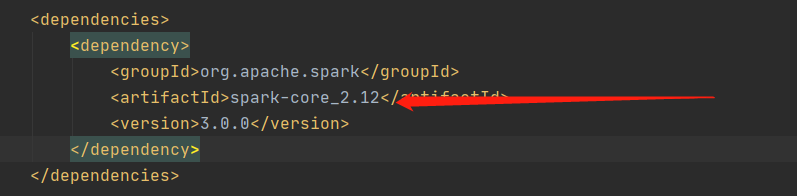
 博客内容概述:遇到Spark运行时的`java.lang.NoSuchMethodError: scala.Product.init(Lscala/Product;)V`错误,原因是POM文件中Scala版本冲突。解决方法是确保所有相关Scala库的版本保持一致。
博客内容概述:遇到Spark运行时的`java.lang.NoSuchMethodError: scala.Product.init(Lscala/Product;)V`错误,原因是POM文件中Scala版本冲突。解决方法是确保所有相关Scala库的版本保持一致。
博客内容概述:遇到Spark运行时的`java.lang.NoSuchMethodError: scala.Product.init(Lscala/Product;)V`错误,原因是POM文件中Scala版本冲突。解决方法是确保所有相关Scala库的版本保持一致。
博客内容概述:遇到Spark运行时的`java.lang.NoSuchMethodError: scala.Product.init(Lscala/Product;)V`错误,原因是POM文件中Scala版本冲突。解决方法是确保所有相关Scala库的版本保持一致。
 1579
1436
1342
1579
1436
1342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言